Archive
Game Changer
Even though I’m a huge fan of the man, I was quite skeptical when I heard Bjarne Stroustrup enunciate: “C++ feels like a new language“. Of course, Bjarne was talking about the improvements brought into the language by the C++11 standard.
Well, after writing C++11 production code for almost 2 years now (17 straight sprints to be exact), I’m no longer skeptical. I find myself writing code more fluidly, doing battle with the problem “gotchas” instead of both the problem and the language gotchas. I don’t have to veer off track to look up language technical details and easily forgotten best-practices nearly as often as I did in the pre-C++11 era.
It seems that the authors of the “High Integrity C++” coding standard agree with my assessment. In a white paper summarizing the changes to their coding standard, here is what they have to say:

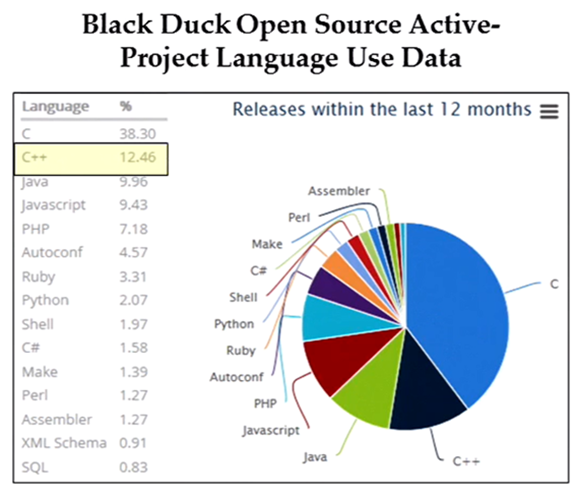
Even though C++’s market niche has shrunk considerably in the 21st century, it is still widely used throughout the industry. The following chart, courtesy of Scott Meyers’ recent talk at Facebook, shows that the old-timer still has legs. The pending C++14 and C++17 updates virtually guarantee its relevance far into the future; just like the venerable paper clip and spring-loaded mouse trap.
Stopping The Spew!
Every C++ programmer has experienced at least one, and most probably many, “Template Spew” (TS) moments. You know you’ve triggered a TS moment when, just after hitting the compile button on a program the compiler deems TS-worthy, you helplessly watch an undecipherable avalanche of error messages zoom down your screen at the speed of light. It is rumored that some novices who’ve experienced TS for the very first time have instantaneously entered a permanent catatonic state of unresponsiveness. It’s even said that some poor souls have swan-dived off of bridges to untimely deaths after having seen such carnage.
Note: The graphic image that follows may be highly disturbing. You may want to stop reading this post at this point and continue to waste company time by surfing over to facebook, reddit, etc.
TS occurs when one tries to use a templated class object or function template with a template parameter type that doesn’t provide the behavior “assumed” by the class or function. TS is such a scourge in the C++ world that guru Scott Meyers dedicates a whole item in “Effective STL“, number 49, to handling the trauma associated with deciphering TS gobbledygook.
For those who’ve never seen TS output, here is a woefully contrived example:

The above example doesn’t do justice to the havoc the mighty TS dragon can wreak on the mind because the problem (std::vector<T> requires its template arg to provide a copy assignment function definition) can actually be inferred from a couple of key lines in the sea of TS text.
Ok, enough doom and gloom. Fear not, because help is on the way via C++14 in the form of “concepts lite“. A “concept” is simply a predicate evaluated on a template argument at compile time. If you employ them while writing a template, you inform the compiler of what kind(s) of behavior your template requires from its argument(s). As a use case illustration, behold this slide from Bjarne Stroustrup:

The “concept” being highlighted in this example is “Sortable“. Once the compiler knows that the sort<T> function requires its template argument to be “Sortable“, it checks that the argument type is indeed sortable. If not, the error message it emits will be something short, sweet, and to the point.
The concept of “concepts” has a long and sordid history. A lot of work was performed on the feature during the development of the C++11 specification. However, according to Mr. Stroustrup, the result was overly complicated (concept maps, new syntax, scope & lookup issues). Thus, the C++ standards committee decided to controversially sh*tcan the work:
C++11 attempt at concepts: 70 pages of description, 130 concepts – we blew it!
After regrouping and getting their act together, the committee whittled down the number of pages and concepts to something manageable enough (approximately 7 pages and 13 concepts) to introduce into C++14. Hence, the “concepts lite” label. Hopefully, it won’t be long before the TS dragon is relegated back to the dungeon from whence it came.
No Runtime Overhead
Since I have the privilege of using C++11/14 on my current project, I’ve been using the new language idioms as fast as I can discover and learn them. For example, instead of writing risky, exception-unsafe, naked “new“, code like this:
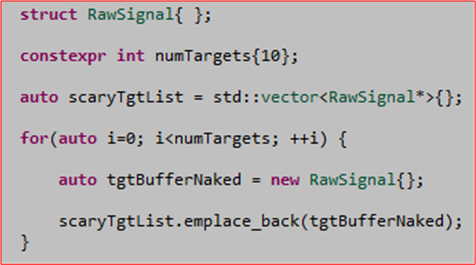
I’ve been writing code like this instead:
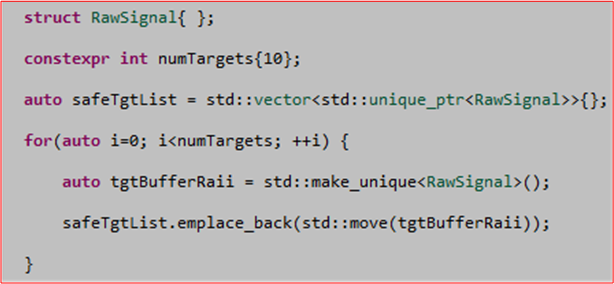
By using std::unique_ptr instead of a naked pointer, I don’t have to veer away from the local code I’m writing to write matching delete statements in destructors or in catch() exception clauses to prevent inadvertent memory leaks.
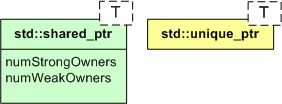
I could’ve used a std::shared_ptr (which can be copied instead of “moved“) in place of the std::unique_ptr, but std::shared_ptr is required to maintain a fatter internal state in the form of strong and weak owner counters. Unless I really need shared ownership of a dynamically allocated object, which I haven’t so far, I stick to the slimmer and more performant std::unique_ptr.
When I first wrote the std::unique_ptr code above, I was concerned that using the std::move() function to transfer encapsulated memory ownership into the safeTgtList vector would add some runtime overhead to the code (relative to the C++98/03 style of simply copying the naked pointer into the scaryTgtList vector). It is, after all, a function, so I thought it must insert some code into my own code.
However, after digging a little deeper into my concern, I discovered (via Stroustrup, Sutter, and Meyers) that std::move() adds zero runtime overhead to the code. Its use is equivalent to performing a static_cast on its argument – which is evaluated at compile time.
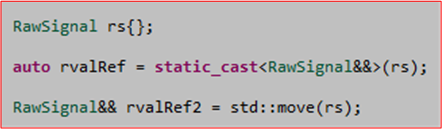
As Scott Meyers stated at GoingNative13, std::move() doesn’t really move anything. It simply prepares for a subsequent real move by casting its argument from an lvalue to an rvalue – which is required for movement of an object’s innards. In the previous code, the move is actually performed within the std::vector::emplace_back() function.
Quoting Scott Meyers: “think of std::move() as an rvalue_cast“. I’m not sure why the ISO C++ committee didn’t define a new rvalue_cast keyword instead of std::move() to drive home the point that no runtime overhead is imposed, but I’d speculate that the issue was debated. Perhaps they thought rvalue_cast was too technical a term for most users?
Update 10/25/13
As I said early in the post, the code example is “like” the code I’ve been writing. The real code that triggered this post is as shown here:
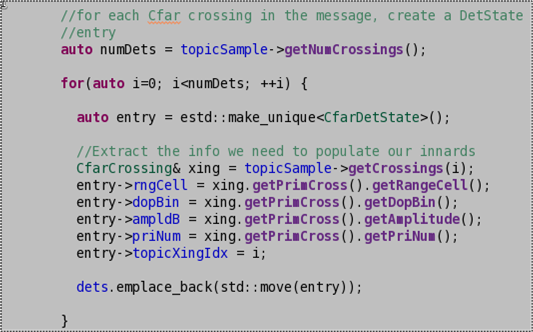
Since each “entry” CfarDetState object must be uniquely intialized form it’s associated CfarCrossing object, I can’t simply insert estd::make_unique<CfarDetState>() into the emplace_back() function. All of the members of each “entry” must be initialized first. Regardless of whether I use emplace_back() or push_back(), std::move(entry) must be used as the argument of the chosen function.
The Current Crop
There are a bazillion books on C++03 out in the wild. However, even though there are lots of pieces of C++11 material available for consumption online, there are (AFAIK) only 6 C++11 books currently available:

Lucky BD00. He has 24 X 7 e-access to all of these tomes through his Safari Books Online membership.
Note that even though he has some C++11/14 training material available for purchase on his web site, none of Scott Meyers‘ “Effective” series of C++ books has been updated yet. Fear not. The first in the series, “Effective C++11/14“, is coming to market in early 2014. The description of Scott’s upcoming GoingNative 2013 session, titled “An Effective C++11/14 Sampler“, reads as follows:
After years of intensive study (first of C++0x, then of C++11, and most recently of C++14), Scott thinks he finally has a clue. About the effective use of C++11, that is (including C++14 revisions). At last year’s Going Native, Herb Sutter predicted that Scott would produce a new version of Effective C++ in the 2013-14 time frame, and Scott’s working on proving him almost right. Rather than revise Effective C++, Scott decided to write a new book that focuses exclusively on C++11/14: on the things the experts almost always do (or almost always avoid doing) to produce clear, efficient, effective code. In this presentation, Scott will present a taste of the Items he expects to include in Effective C++11/14. If all goes as planned, he’ll also solicit your help in choosing a cover for the book.
It’s about time that Scott got a clue. 🙂
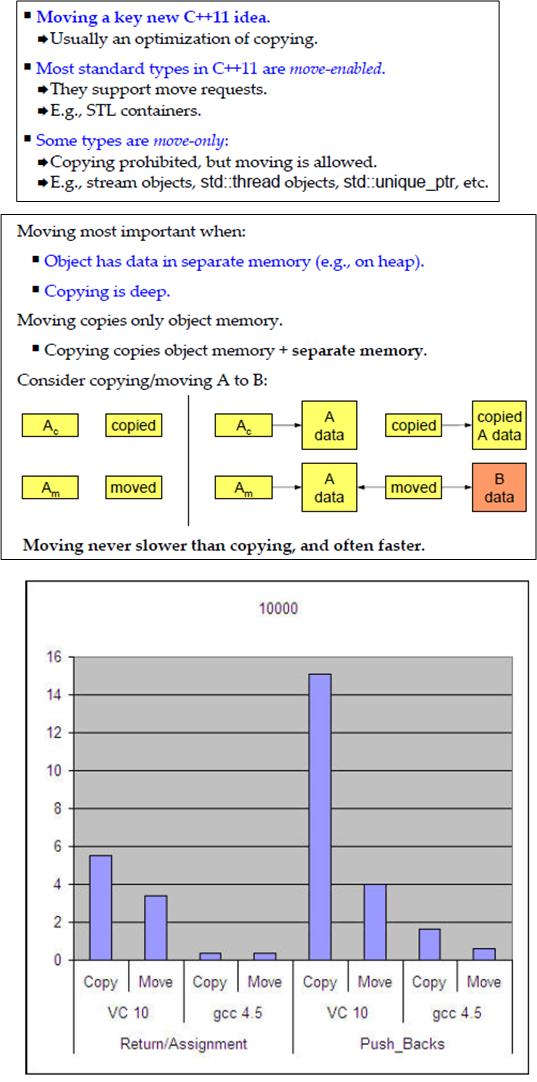
My C++11 “Move” Notes
Being a slow learner, BD00 finds it easier to learn a new topic by researching the writings from multiple sources of authority. BD00 then integrates his findings into his bug-riddled brain as “the truth as he sees it” (not the absolute truth – which is unknowable). The different viewpoints offered up by several experts on a subject tend to fill in holes of understanding that would otherwise go unaddressed. Thus, since BD00 wanted to learn more about how C++11’s new “move” and “rvalue reference” features work, he gathered several snippets on the subject and hoisted them here.
Why Move?
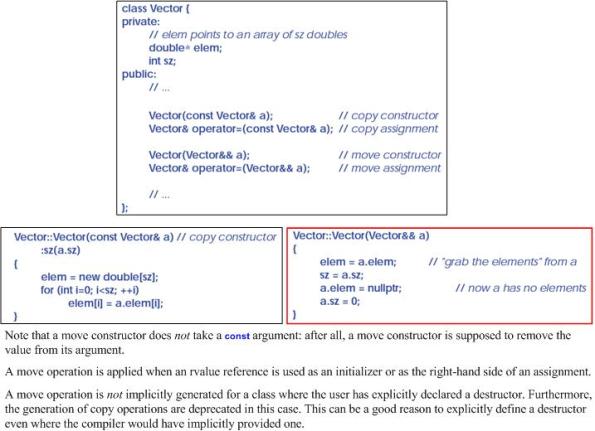
The motivation for adding “rvalue” references and “move” semantics to C++11 to complement its native “copy” semantics was to dramatically improve performance when large amounts of heap-based data need to be transferred from one class object to another AND it is known that preserving the “from” class object’s data is unnecessary (e.g. returning a non-static local object from a function). Rather than laboriously copying each of a million objects from one object to another, one can now simply “move” them.
Unlike its state after a “copy“, a moved-from object’s data is no longer present for further use downstream in the program. It’s like when I give you my phone. I don’t make a copy of it and hand it over to you. After I “move” it to you, I’m sh*t outta luck if I want to call my shrink – until I get a new phone.
Chapter 13 – C++ Primary, Fifth Edition, Lippman, Lajoie, Moo

Chapter 3 – The C++ Programming Language, 4th Edition, Bjarne Stroustrup
Chapter 3 – The C++ Standard Library, 2nd Edition, Nicolai M. Josuttis

Overview Of The New C++ (C++11), Scott Meyers
Broken Books
With the addition of features like auto, initializer lists, lambdas, and smart pointers, a lot of C++98 programming idioms and guidance have become obsolete now that C++11 is here. Thus, as Herb Sutter said at GoingNative 2012, a boatload of code examples in the best C++ books are now “broken“.
As a result, new and revamped versions of the books will take awhile to become available. Here’s Herb’s “estimated time of arrival” for several stalwart books:

In the meantime, you can feast your eyes on, and feed the left side of your brain with, these links:
- Bjarne Stroustrup’s C++11 FAQ page
- Wikipedia C++11
- Scott Meyers Overview Of C++11
- C++11 Features To GCC Compiler Map
- C++ Standards Committee Home Page
- GoingNative 2012
- C++11 Features in Visual C++ 11
- Clang Compiler C++11 Support
- Writing Modern C++ Code (Herb Sutter)
Do you know of any other good links to add to this post?
Concurrency Support
Assuming that I remain a lowly, banana-eating programmer and I don’t catch the wanna-be-uh-manager-supervisor-director-executive fever, I’m excited about the new features and library additions provided in the C++11 standard.

Specifically, I’m thrilled by the support for “dangerous” multi-threaded programming that C++11 serves up.

For more info on the what, why, and how of these features and library additions, check out Scott Meyers’ pre-book training package, Anthony Williams’ new book, and Bjarne’s C++11 FAQ page.

Just As Fast, But Easier To Write
I love watching Herb Sutter videos on C++. His passion and enthusiasm for the language is infectious. Like Scott Meyers, Herb always explains the “why” and “how” of a language feature in addition to the academically dry “what” .
In this talk, “Writing modern C++ code: how C++ has evolved over the years“, Herb exhibits several side by side code snippets that clearly show much easier it is to write code in C++11 (relative to C++98) without sacrificing efficiency.
Here’s an example (which I hope isn’t too blurry) in which the C++11 code is shorter and obsoletes the need for writing an infamous”new/delete” pair.

Note how Herb uses the new auto, std::make_shared, std::shared_ptr, and anonymous lambda function features of C++11 to shorten the code and minimize the chance of making mistakes. In addition, Herb’s benchmarking tests showed that the C++11 code is actually faster than the C++98 equivalent. I don’t know about you, but I think this is pretty w00t!
I love paradoxes because they twist the logical mind into submission to the cosmos. Thus, I’m gonna leave you with this applicable quote (snipped from Herb’s presentation) by C++ expert and D language co-creator Andrei Alexandrescu:

Note: As a side bonus of watching the video, I found out that the Microsoft Parallel Patterns Library is now available for Linux (via Intel).

Dissin’ Boost
To support my yearning for learning, I continuously scan and probe all kinds of forums, books, articles, and blogs for deeper insights into, and mastery of, the C++ programming language. In all my external travels, I’ve never come across anyone in the C++ community that has ever trashed the boost libraries. Au contraire, every single reference that I’ve ever seen has praised boost as a world class open source organization that produces world class, highly efficient code for reuse. Here’s just one example of praise from Scott Meyers‘ classic “Effective C++: 55 Specific Ways To Improve Your Programs And Designs“:

Notice that in the first paragraph, I wrote the word external in bold. Internal, which means “at work” where politics is always involved, is another story. Sooooo, let me tell you one.
Years ago, a smart, highly productive, and dedicated developer who I respect started building a distributed “framework” on top of the ACE library set (not as a formal project – on his own time). There’s no doubt that ACE is a very powerful, robust, and battle-tested platform. However, because it was designed back in the days when C++ compiler technology was immature, I think its API is, let’s say “frumpy“, unconventional, and (dare I say) “obsolete” compared to the more modern Boost APIs. Boost-based code looks like natural C++, whereas ACE-based code looks like a macro derived dialect. In the functional areas where ACE and Boost overlap (which IMHO is large), I think that Boost is head over heels easier to learn and use. But that’s just me, and if you’re a long-time ACE advocate you might be mad at me now because you’re blinded by your bias – just like I am blinded by mine.

Fast forward to the present moment after other groups in the company (essentially, having no choice) have built their one-off applications on top of the homegrown, ACE-based, framework. Of course, you know through experience that “homegrown” means:
- the framework API is poorly documented,
- the build process is poorly documented,
- forks have been spawned because of the lack of a formally funded maintenance team and change process,
- the boundary between user and library code is jagged/blurry,
- example code tutorials are non-existent.
- it is most likely to cost less to build your own, lighter weight framework from scratch than to scale the learning curve by studying tens of 1,000s of lines of framework code to separate the API from the implementation and figure out how to use the dang thing.
Despite the time-proven assertions above, the framework author and a couple of “other” promoters who’ve never even tried to extract/build the framework, let alone learn the basics of the “jagged” API and write a simple sample distributed app on top of it, have naturally auto-assumed that reusing the framework in all new projects will save the company time and money.
Along comes a new project in which the evil Bulldozer00 (BD00) is a team member. Being suspicious of the internal marketing hype, and in response to the “indirect pressure and unspoken coercion” to architect, design, and build on top of the one and only homegrown framework, BD00 investigates the “product“. After spending the better part of a week browsing the code base and frustratingly trying to build the framework so that he could write a little distributed test app, BD00 gives up and concludes that the bulleted list definition above has withstood the test of time….. yet again.
When other members of BD00’s team, including one member who directly used the ACE-based framework on a previous project, investigate the qualities of the framework, they come to the same conclusion: thank you, but for our project, we’ll roll our own lighter weight, more targeted, and more “modern” framework on top of Boost. But of course, BD00 is the only politically incorrect and blatantly over-the-top rejector of the intended one-size-fits-all framework. In predictable cause-effect fashion, the homegrown framework advocates dig their heels in against BD00’s technical criticisms and step up their “cost and time savings” rhetoric – including a diss against Boost in their internal marketing materials. Hmmm.
Since application infrastructure is not a company core competence and certainly not a revenue generator, BD00 “cleverly” suggests releasing the framework into the open source community to test its viability and ability to attract an external following. The suggestion falls on deaf ears – of course. Even though BD00 (who’s deliberately evil foot-in-mouth approach to conflict-handling almost always triggers the classic auto-reject response in others) made the helpful(?) suggestion, the odds are that it would be ignored regardless of who had made it. Based on your personal experience, do you agree?
Note 1: If interested, check out this ACE vs Boost vs Poco libraries discussion on StackOverflow.com.
Note2: There’s a whole ‘nother sensitive socio-technical dimension to this story that may trigger yet another blog post in the future. If you’ve followed this blog, I’ve hinted about this bone of contention in several past posts. The diagram below gives a further hint as to its nature.

Scott Meyers On C++0x
From what I know (which is very little), it looks like the C++0x programming standard will finally be released to the world as C++0B this spring. As part of preparing for this release, I recently listened to an interview with “Effective” Scott Meyers on Software Engineering Radio.
In case you find yourself bored, and with an hour of free time on your hands, check out my audio + notes pencast recording of the interview on the Livescribe smart pen site: here. (Clicking on the pic below won’t start the pencast in-situ. I haven’t figured out how to embed pencasts into this blog yet).

The interview was an interesting mix of good technical information from Scott, triggered by great questions from the interviewer. Nevertheless, at several points during the interview, the interviewer seemed to interject sarcastic commentary that showed his disdain for the language. He obviously wasn’t/isn’t a C++ language fan, but he still did a great job with his questions. The interview never veered off into a “your language sux and my language rules” religious war and the interviewer’s snarky remarks kept the interview refreshing:
“Why doesn’t C++ have garbage collection? …… Because then there would be nothing left.”
In summary, Scott used his considerable teaching talent to clearly and concisely explain these key features of the “C++0B” standard:
- concurrency
- the “auto” keyword
- move semantics using rvalue references
- variadic templates
- lambda functions
- uniform initialization syntax
- tuples (or as the interviewer pronounced, “two-pulls” 🙂 )
If C++ is your programming language of choice and you haven’t followed the development of the new standard, now may be the time to start wading in? The Meyers interview, this excellent Wikipedia C++0x starter page, and Bjarne Stroustrup’s C++0x FAQ page may help.

Related Articles
- An Interview with C++ Creator Bjarne Stroustrup (codeguru.com)
- Type Inference vs. Static/Dynamic Typing (herbsutter.com)
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

