Archive
Goalodicy
Goalodicy – the pursuit of idiotic goals
The last book I read was Scott Adams’ “How to Fail at Almost Everything and Still Win Big: Kind of the Story of My Life“. The current book I’m reading is Oliver Burkeman‘s “The Antidote: Happiness for People Who Can’t Stand Positive Thinking“. Coincidentally, and unbeknownst to me before I began reading the books, both authors trash the dogma that setting specific goals is a worthwhile idea. Burkeman has this (and much, much more) to say on goal pursuit:
A business goal would be set, announced, and generally greeted with enthusiasm. But then evidence would begin to emerge that it had been an unwise one – and goalodicy would kick in as a response. The negative evidence would be reinterpreted as a reason to invest more effort and resources in pursuit of the goal. And so things would, not surprisingly, go even more wrong…. There is a good case to be made that many of us, and many of the organisations for which we work, would do better to spend less time on goal-setting, and, more generally, to focus with less intensity on planning for how we would like the future to turn out. – Oliver Burkeman
Scott Adams is even more critical of the “best practice” of goal-setting than Burkeman:
Throughout my career I’ve had my antennae up, looking for examples of people who use systems as opposed to goals. In most cases, as far as I can tell, the people who use systems do better. The systems-driven people have found a way to look at the familiar in new and more useful ways. To put it bluntly, goals are for losers. That’s literally true most of the time. For example, if your goal is to lose ten pounds, you will spend every moment until you reach the goal—if you reach it at all—feeling as if you were short of your goal. In other words, goal-oriented people exist in a state of nearly continuous failure that they hope will be temporary. That feeling wears on you. In time, it becomes heavy and uncomfortable… Goal-oriented people exist in a state of continuous pre-success failure at best, and permanent failure at worst if things never work out. – Scott Adams
If you’re a laser-focused, SMART goal-oriented person, you might want to revisit some of the foundational bricks in your worldview in light of what Burkeman and Adams have to say. But then again, neither Burkeman nor Adams are absolutists. They don’t emphatically advise against all goal-setting. They simply suggest considering alternative, less psychically destructive methods of attempting to better our lives (devise/use a system; envision a qualitatively desirable future and move toward it).
You might say every system has a goal, however vague. And that would be true to some extent. And you could say that everyone who pursues a goal has some sort of system to get there, whether it is expressed or not. You could word-glue goals and systems together if you chose. All I’m suggesting is that thinking of goals and systems as very different concepts has power. – Scott Adams
There is plenty of very real research testifying to the fact that the practice (of goal-setting) can be useful. Interpreted sufficiently broadly, setting goals and carrying out plans to achieve them is how many of us spend most of our waking hours. – Oliver Burkeman

A Hoarrific Failure
Work started (on the 503 Mark II software system) with a team of fifteen programmers and the deadline for delivery was set some eighteen months ahead in March 1965.
Although I was still managerially responsible for the 503 Mark II software, I gave it less attention than the company’s new products and almost failed to notice when the deadline for its delivery passed without event.
The programmers revised their implementation schedules and a new delivery date was set some three months ahead in June 1965. Needless to say, that day also passed without event.
I asked the senior programmers once again to draw up revised schedules, which again showed that the software could be delivered within another three months. I desperately wanted to believe it but I just could not. I disregarded the schedules and began to dig more deeply into the project.
The entire Elliott 503 Mark II software project had to be abandoned, and with it, over thirty man-years of programming effort, equivalent to nearly one man’s active working life, and I was responsible, both as designer and as manager, for wasting it.
The above story synopsis was extracted from Tony “Quicksort” Hoare‘s 1980-ACM Turing award lecture.
Mr. Hoare’s classic speech is the source of a few great quotes that have transcended time:
I conclude that there are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult…. No committee will ever do this until it is too late.
A feature which is included before it is fully understood can never be removed later.
At first I hoped that such a technically unsound project would collapse but I soon realized it was doomed to success.
The price of reliability is the pursuit of the utmost simplicity. It is a price which the
very rich find most hard to pay.The mistakes which have been made in the last twenty years are being repeated today on an even grander scale. (1980)
Dontcha think that last quote can be restated today as:
The mistakes which have been made in the last fifty years are being repeated today on an even grander scale.
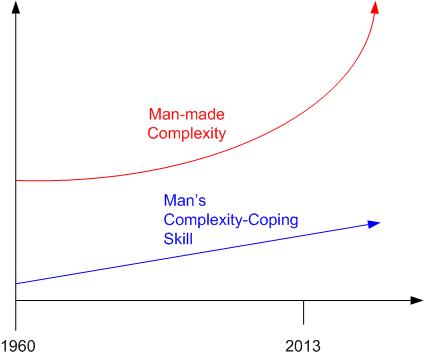
Since man’s ability to cope with complexity is relentlessly being dwarfed by his propensity to create ever greater complexity, the same statement might probably be true 50 years hence, no?
Proximity In Space And Time
When a failure occurs in a complex, networked, socio-technical system, the probability is high that the root cause is located far away from the failure detection point in time, space, or both. The progression in time goes something like this:
fault ———–> error———-> error—————–>error——>failure discovered!
An unanticipated fault begets an error, which begets another error(s), which begets another error(s), etc, until the failure is manifest via loss of life or money somewhere and sometime downstream in the system. In the case of a software system, the time from fault to catastrophic failure may take milliseconds, but the distance between fault and failure can be in the 100s of thousands of lines of source code sprinkled across multiple machines and networks.

Let’s face it. Envisioning, designing, coding, and testing for end-to-end “system level” error conditions in software systems is unglamorous and tedious (unless you’re using Erlang – which is thoughtfully designed to lessen the pain). It’s usually one of the first things to get jettisoned when the pressure is ratcheted up to meet some arbitrary schedule premised on a baseless, one-time, estimate elicited under duress when the project was kicked-off. Bummer.
Still Applicable Today

Note: This graphic was clipped out of Bill Livingston’s D4P4D.
No Lessons Learned
Because I’m fascinated by the causes and ubiquity of socio-technical project explosions, I try to follow technical press reports on the status of big government contracts. Here’s a recent article detailing the demise of the DoD’s Joint Tactical Radio System (JTRS): “How to blow $6 billion on a tech project“.
Even though the reasons for big, software-intensive, multi-technology project failures have been well known for decades, disasters continue to be hatched and cancelled daily around the world by both public and private institutions everywhere – except yours, of course.
What follows are some snippets from the Ars Technica article and the JTRS wikipedia entry. The well-known, well-documented, contributory causes to the JTRS project’s demise are highlighted in bold type.
When JTRS and GMR launched, the services broke out huge wish lists when they drafted their initial requests for proposals on individual JTRS programs. While they narrowed some of these requirements as the programs were consolidated, requirements were constantly revised before, during, and after the design process.
In hindsight, the military badly underestimated the challenges before it.
First and foremost was the software development problem. When JTRS started, software-defined radio (SDR) was still in its infancy. The project’s SCA architecture allowed software to manipulate field-programmable gate arrays (FPGAs) in the radio hardware to reconfigure how its electronics functioned, exposing those FPGAs as CORBA objects. But when development began, hardware implementations of CORBA for FPGAs didn’t really exist in any standard form.
Moving code for a waveform from one set of radio hardware to another didn’t just mean a recompile—it often meant significant rewrites to make it compatible with whatever FGPAs were used in the target radio, then further tweaking to produce an acceptable level of performance. The result: the challenge of core development tasks for each of the initial designs was often grossly underestimated. Some of those issues have been addressed by specialized CORBA middleware, such as PrismTech’s OpenFusion, but the software tools have been long in coming.
When JTRS began, there was no WiFi, no 3G or no 4G wireless, and commercial radio communications was relatively expensive. But the consumer industry didn’t even look at SDR as a way to keep its products relevant in the future. Now, ASIC-based digital signal processors are cheap, and new products also tend to include faster chips and new hardware features; people prefer buying a new $100 WiFi router when some future 802.11z protocol appears instead of buying a $3,000 wireless router today that is “future proofed” (and you can’t really call anything based on CORBA “future proofed”).
“If JTRS had focused on rapid releases and taken a more modular approach, and tested and deployed early, the Army could have had at least 80 percent of what it wanted out of GMR today, instead of what it has now—a certified radio that it will never deploy.”
Having an undefined technical problem is bad enough, but it gets even worse when serious “scope creep” sets in during a 15-year project.
Each of the five sub-programs within JTRS aimed not at an incremental goal, but at delivering everything at once. That was a recipe for disaster.
By 2007 (10 years after start) the JTRS program as a whole had spent billions and billions—without any radios fielded.

In the fall of 2011, after 13 years of toil and $6B of our money wasted, the monster was put out of its misery. It was cancelled on October 2011 by the United States Undersecretary of Defense:
Our assessment is that it is unlikely that products resulting from the JTRS GMR development program will affordably meet Service requirements, and may not meet some requirements at all. Therefore termination is necessary.
And here’s what we, the taxpayers, have to show for the massive investment:
After 13 years in the pipeline, what those users saw was a radio that weighed as much as a drill sergeant, took too long to set up, failed frequently, and didn’t have enough range. (D’oh! and WTF!)
Well Known And Well Practiced
It’s always instructive to reflect on project failures so that the same costly mistakes don’t get repeated in the future. But because of ego-defense, it’s difficult to step back and semi-objectively analyze one’s own mistakes. Hell, it’s hard to even acknowledge them, let alone to reflect on, and to learn from them. Learning from one’s own mistake’s is effortful, and it often hurts. It’s much easier to glean knowledge and learning from the faux pas of others.
With that in mind, let’s look at one of the “others“: Hewlitt Packard. HP’s 2010 $1.2B purchase of Palm Inc. to seize control of its crown jewel WebOS mobile operating system turned out to be a huge technical and financial and social debacle. As chronicled in this New York Times article, “H.P.’s TouchPad, Some Say, Was Built on Flawed Software“, here are some of the reasons given (by a sampling of inside sources) for the biggest technology flop of 2011:
- The attempted productization of cutting edge, but immature (freeze ups, random reboots) and slooow technology (WebKit).
- Underestimation of the effort to fix the known technical problems with the OS.
- The failure to get 3rd party application developers (surrogate customers) excited about the OS.
- The failure to build a holistic platform infused with conceptual integrity (lack of a benevolent dictator or unapologetic aristocrat).
- The loss of talent in the acquisition and the imposition of the wrong people in the wrong positions.
Hmm, on second thought, maybe there is nothing much to learn here. These failure factors have been known and publicized for decades, yet they continue to be well practiced across the software-intensive systems industry.
Obviously, people don’t embark on ambitious software development projects in order to fail downstream. It’s just that even while performing continuous due diligence during the effort, it’s still extremely hard to detect these interdependent project killers until it’s too late to nip them in the bud. Adding salt to the wound, history has inarguably and repeatedly shown that in most orgs, those who actually do detect and report these types of problematiques are either ignored (the boy who cried wolf syndrome) or ostracized into submission (the threat of excommunication syndrome). Note that several sources in the HP article wanted to “remain anonymous“.

Related articles
- Sluggish code and HP power plays blamed for webOS’ failure (slashgear.com)
- Leaks: webOS struggled with poor staff, fundamental design (electronista.com)
- Why WebOS Failed (technologizer.com)
Unfriendly Fire
In Nancy Leveson’s new book, “Engineering A Safer World“, she analyzes (in excruciating detail) all the little screw-ups that occurred during an accident in Iraq where two F-15 fighters shot down two friendly black hawk helicopters – killing all aboard. To set the stage for dispassionately explaining the tragedy, Ms. Leveson provides the following hierarchical command and control model of the “system” at the time of the fiasco:

Holy shite! That’s a lot of levels of “approval required“, no?
In typical BD00 fashion, the dorky figure below dumbs down and utterly oversimplifies the situation so that he can misunderstand it and jam-fit it into his flawed UCB mental model. Holy shite! That’s still a lot of levels of “ask me for permission before you pick your nose“, no?

So, what’s the point here? It’s that every swingin’ dick wants to be an esteemed controller and not a low level controlleee. Why? Because….
“Work is of two kinds: first, altering the position of matter at or near the earth’s surface relatively to other such matter; second, telling other people to do so. The first kind is unpleasant and ill paid; the second is pleasant and highly paid.” – Bertrand Russell
People who do either kind of work can be (but perhaps shouldn’t be) judged as bozos, or non-bozos. The bozo to non-bozo ratio in the “pleasant” form of work is much higher than the “unpleasant” form of work. – BD00
Rimshot

Research In Motion (RIM) is the creator of the wildly successful Blackberry phone. However, even with the recent release of the well-respected (but too late to the game) Playbook tablet, RIM’s financial and market positions have started to erode as a result of the iPhone and Android onslaught.
Either RIM is shot, or they’re well on their way to being shot – as in “out of business“. For the details, check out “RIM gets handed open letter from disgruntled employee, quickly responds in kind — Engadget“.
The interesting aspect to this “open-letter-from-disgruntled-employee-to-management” case is that the anonymous employee is a senior executive and not a DIC; nor even a manager from a flabby middle borg layer. This fact just about seals the deal – RIM is probably shot.
Another serious piece of evidence that forbears the impending implosion of the RIM corpricracy is the totally predictable and papally infallible response from the corpo spin team:

Of course, as the papal response implies, the open letter writer is a traitorous, agenda-seeking coward and “the senior management team at RIM is fully aware of and aggressively addressing both the company’s challenges and its opportunities“.
But wait! The flood gates have opened and there appear to be several more traitorous, anonymous cowards in the borg that are coming forward. Gee, RIM’s hiring processes must suck to allow all these unethical yellow bellies through the door, no?

Yahoo! Boohoo!
Unless you were born yesterday, you’ve probably heard about the death spiral that former internet great Yahoo! has commenced. In this blarticle from TechCrunch, “Former Yahoo Engineers Shed Light On Why Delicious And Other Acquisitions Failed“, a couple of quotes from former employees brought a tear to my eye.
…it does provide a picture of a company that bogged its acquired-startups down in its company’s administrative BS. As Chad Dickerson, former Yahoo developer evangelist and the current CTO of Etsy comments, “In my experience, entrepreneurs moving into Yahoo! often got stuck doing PowerPoints about “strategy” instead of writing code and shipping products.”
Elliott-McCrea writes: I recently pulled up a worklog I was keeping in 2008-2009, and I found 18 meetings scheduled over a 9 month period discussing why Flickr’s API was poorly designed and when we’d be shutting it down and migrating it to the YOS Web Services Standard.
What I’d like to know is: “Did any of the layers of corpo honchos have any conscious clue that the patriarchical and bureaucratic monster they brought to life was killing the golden goose?” What do you think?

Small, Loose, Big, Tight
This Tom DeMarco slide from his pitch at the Software Executive Summit caused me to stop and think (Uh oh!):

I find it ironic (and true) that when man-made system are composed of “large pieces tightly joined“, they, unlike natural systems of the same ilk, are brittle and fault-intolerant. Look at the man-made financial system and what happened during the financial meltdown. Since the large institutional components were tightly coupled, the system collapsed like dominoes when a problem arose. Injecting the system with capital has ameliorated the problem, but only the future will tell if the problem was dissolved. I suspect not. Since the structure, the players, and the behavior of the monolithic system have remained intact, it’s back to business as usual.
Similarly, as experienced professionals will confirm, man made software systems composed of “large pieces tightly joined” are fragile and fault-intolerant too. These contraptions often disintegrate before being placed into operation. The time is gone, the money is gone, and the damn thing don’t work. I hate when that happens.
On the other hand, look at the glorious human body composed of “large pieces tightly joined“. It’s natural, built-in robustness and tolerance to faults is unmatched by anything man-made. You can survive and still prosper with the loss of an eye, a kidney, a leg, and a host of other (but not all) parts. IMHO, the difference is that in natural systems, the purposes of the parts and the whole are in continuous, cooperative alignment.
When the individual purposes of a system’s parts become unaligned, let alone unaligned with the purpose of the whole as often happens in man made socio-technical systems when everyone is out for themselves, it’s just a matter of time before an internal or external disturbance brings the monstrosity down to its knees. D’oh!
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

