Archive
Milliseconds Since The Epoch 2
Over a year ago, I hoisted some C++ code on the “Milliseconds Since The Epoch” post for those who were looking for a way to generate timestamps for message tagging and/or event logging and/or code performance measurements. That code was based on the Boost.Date_Time library. However, with the addition of the <chrono> library to C++11, the code to generate millisecond (or microsecond or nanosecond) precision timestamps is not only simpler, it’s now standard:
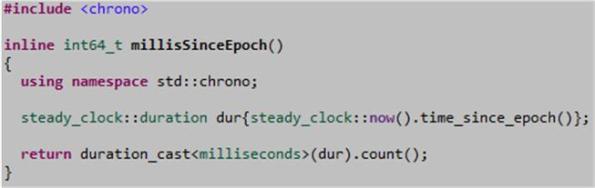
Here’s how it works:
- steady_clock::now() returns a timepoint object relative to the epoch of the steady_clock (which may or may not be the same as the Unix epoch of 1/1/1970).
- steady_clock::timepoint::time_since_epoch() returns a steady_clock::duration object that contains the number of tick-counts that have elapsed between the epoch and the occurrence of the “now” timepoint.
- The duration_cast<T> function template converts the steady_clock::duration tick-counts from whatever internal time units they represent (e.g. seconds, microseconds, nanoseconds, etc) into time units of milliseconds. The millisecond count is then retrieved and returned to the caller via the duration::count() function.
I concocted this code from the excellent tutorial on clocks/timepoints/durations in Nicolai Josuttis’s “The Standard C++ Library (2nd Edition)“. Specifically, “5.7. Clocks and Timers“.
The C++11 standard library provides three clocks:
- system_clock
- high_resolution_clock
- steady_clock
I used the steady_clock in the code because it’s the only clock that’s guaranteed to never be “adjusted” by some external system action (user change, NTP update). Thus, the timepoints obtained from it via the now() member function never decrease as real-time marches forward.
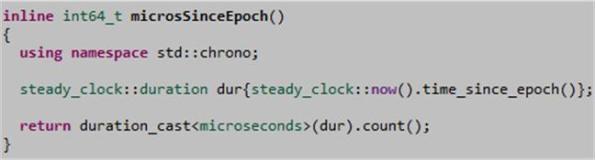
Note: If you need microsecond resolution timestamps, here’s the equivalent code:
So, what about “rollover“, you ask. As the highlight below from Nicolai’s book shows, the number of bits required by C++11 library implementers increases with increased resolution. Assuming each clock ticks along relative to the Unix epoch time, rollover won’t occur for a very, very, very, very long time; no matter which resolution you use.

Of course, the “real” resolution you actually get depends on the underlying hardware of your platform. Nicolai provides source code to discover what these real, platform-specific resolutions and epochs are for each of the three C++11 clock types. Buy the book if you want to build and run that code on your hardware.
Milliseconds Since The Epoch
On a recent project, our team needed a fast and portable C++ way to time stamp messages flowing into our system at high rates – down to the millisecond level of resolution. Here’s the boost-based implementation that I concocted. Notice the classic “midnight, January 1, 1970” epoch and the 64 bits required to preclude multiple rollovers in milliseconds since the epoch. What would your fast and portable C++ solution look like?




Update 1/5/13: Ever since C++11 arrived on the scene, Boost.Date_Time is longer needed for high resolution timing. As the “Milliseconds Since The Epoch 2” post shows, this functionality is now standard in the <chrono> library.
Ammunition Depot
In preparation for a debate, both sides usually spend some time amassing evidence that supports their distorted view of the issue. Well, this post is intended to serve as a repository for my distorted side of an ongoing debate.



All the above snippets were strategically and carefully culled from various discussions posted on the wonderful Joel Spolsky and Jeff Atwood site: Stackoverflow.com.
Dissin’ Boost
To support my yearning for learning, I continuously scan and probe all kinds of forums, books, articles, and blogs for deeper insights into, and mastery of, the C++ programming language. In all my external travels, I’ve never come across anyone in the C++ community that has ever trashed the boost libraries. Au contraire, every single reference that I’ve ever seen has praised boost as a world class open source organization that produces world class, highly efficient code for reuse. Here’s just one example of praise from Scott Meyers‘ classic “Effective C++: 55 Specific Ways To Improve Your Programs And Designs“:

Notice that in the first paragraph, I wrote the word external in bold. Internal, which means “at work” where politics is always involved, is another story. Sooooo, let me tell you one.
Years ago, a smart, highly productive, and dedicated developer who I respect started building a distributed “framework” on top of the ACE library set (not as a formal project – on his own time). There’s no doubt that ACE is a very powerful, robust, and battle-tested platform. However, because it was designed back in the days when C++ compiler technology was immature, I think its API is, let’s say “frumpy“, unconventional, and (dare I say) “obsolete” compared to the more modern Boost APIs. Boost-based code looks like natural C++, whereas ACE-based code looks like a macro derived dialect. In the functional areas where ACE and Boost overlap (which IMHO is large), I think that Boost is head over heels easier to learn and use. But that’s just me, and if you’re a long-time ACE advocate you might be mad at me now because you’re blinded by your bias – just like I am blinded by mine.

Fast forward to the present moment after other groups in the company (essentially, having no choice) have built their one-off applications on top of the homegrown, ACE-based, framework. Of course, you know through experience that “homegrown” means:
- the framework API is poorly documented,
- the build process is poorly documented,
- forks have been spawned because of the lack of a formally funded maintenance team and change process,
- the boundary between user and library code is jagged/blurry,
- example code tutorials are non-existent.
- it is most likely to cost less to build your own, lighter weight framework from scratch than to scale the learning curve by studying tens of 1,000s of lines of framework code to separate the API from the implementation and figure out how to use the dang thing.
Despite the time-proven assertions above, the framework author and a couple of “other” promoters who’ve never even tried to extract/build the framework, let alone learn the basics of the “jagged” API and write a simple sample distributed app on top of it, have naturally auto-assumed that reusing the framework in all new projects will save the company time and money.
Along comes a new project in which the evil Bulldozer00 (BD00) is a team member. Being suspicious of the internal marketing hype, and in response to the “indirect pressure and unspoken coercion” to architect, design, and build on top of the one and only homegrown framework, BD00 investigates the “product“. After spending the better part of a week browsing the code base and frustratingly trying to build the framework so that he could write a little distributed test app, BD00 gives up and concludes that the bulleted list definition above has withstood the test of time….. yet again.
When other members of BD00’s team, including one member who directly used the ACE-based framework on a previous project, investigate the qualities of the framework, they come to the same conclusion: thank you, but for our project, we’ll roll our own lighter weight, more targeted, and more “modern” framework on top of Boost. But of course, BD00 is the only politically incorrect and blatantly over-the-top rejector of the intended one-size-fits-all framework. In predictable cause-effect fashion, the homegrown framework advocates dig their heels in against BD00’s technical criticisms and step up their “cost and time savings” rhetoric – including a diss against Boost in their internal marketing materials. Hmmm.
Since application infrastructure is not a company core competence and certainly not a revenue generator, BD00 “cleverly” suggests releasing the framework into the open source community to test its viability and ability to attract an external following. The suggestion falls on deaf ears – of course. Even though BD00 (who’s deliberately evil foot-in-mouth approach to conflict-handling almost always triggers the classic auto-reject response in others) made the helpful(?) suggestion, the odds are that it would be ignored regardless of who had made it. Based on your personal experience, do you agree?
Note 1: If interested, check out this ACE vs Boost vs Poco libraries discussion on StackOverflow.com.
Note2: There’s a whole ‘nother sensitive socio-technical dimension to this story that may trigger yet another blog post in the future. If you’ve followed this blog, I’ve hinted about this bone of contention in several past posts. The diagram below gives a further hint as to its nature.

Performance Playground
Since I work on real-time software projects where tens of thousands of data samples per second must be filtered, manipulated, and transformed into higher level decision-support information, performance in the main processing pipeline is important. If the software can’t keep up with the unrelenting onslaught of data streaming in from the “real world“, internal buffers/queues will overflow at best and the system will crash at worst. D’oh!
Because of the elevated importance of efficiency in real-time systems, I always keep a simple (one source code file) project named “performance_playground” open in my Eclipse IDE for algorithm/idiom/pattern prototyping and performance measurement. I use it to measure and optimize the performance of “chunks” of critical logic and to pit two or more candidates against each other in performance death matches. For each experiment I “branch” off of the project trunk and then I tag and commit the instantiation to archive the results.
The source code for the performance_playground project is shown below. The program’s sole external dependency is on the boost.date_time library for its platform-independent timestamping. Surely, you have the boost library set installed on all your development platforms, right?

How about you? Do you have something similar? Do you assume that all performance testing and algorithm vetting falls into the dreaded, time-wasting, “premature optimization” anti-pattern?
Measuring Clock Resolution
The Boost.Date_Time C++ library provides an excellent, platform-independent set of interrelated classes for measuring and tracking times and dates during program operation. It is much more capable and, more importantly, accurate than the standard C++ <ctime> library inherited from C. Since we need to benchmark the average and peak latency for our growing distributed, real-time, system infrastructure running on Linux, Solaris and (maybe) Win32 platforms, I decided to use the Boost.Date_Time functionality to measure the clock resolution on a representative of each platform.
The UML activity diagram below shows the simple algorithm that I used to write a small program that estimates the clock resolution of any compiler-CPU-OS platform combo that Boost.Date_Time is available for. The assumption underlying the design is that the program instructions inside the loop execute an order of magnitude faster than a clock tick increments. At CPU speeds on the order of GHz ( nanoseconds) and clock periods of microseconds, this is a pretty decent assumption, no? The algorithm simply spins around in a tight, high speed loop waiting for the clock to change value relative to an initial reference sample. Note that measuring hardware clock accuracy is another story (Does anyone know if clock hardware accuracy can even be estimated in software?).

The function below shows the super secret, proprietary, source code that uses the Boost.Date_Time facilities to implement the clock resolution estimation algorithm. Note that the boost microseconds clock, as opposed to the nanoseconds or seconds clock, is used to grab time samples. The seconds clock is too coarse grained for our needs and typical off-the-shelf servers do not provide hardware clocks with nanosecond resolutions without add on circuitry. The box below the code shows the results that I obtained for three platforms on which I ran the program. Of course, the results aren’t perfect (are any results ever perfect?), but since the Solaris and Linux results provide sub-millisecond resolution and we expect end-to-end system latencies on the order of hundreds of milliseconds, the clocks will satisfy our latency measurement needs. Of course, the Win32 result is crappy. Got any thoughts?

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

