Archive
Stack, Heap, Pool
Update 10/7/15: Because this post lacked a context-setting introduction, I wrote a prequel for it after the fact. Please read the prequel before reading this post.
Three Ways
The figure below shows three ways of allocating memory from within a C++ application: stack, heap, custom written pool.

Comparing Performance
The code below measures the performance of the three allocation methods. It computes and prints the time to allocate 1000, 1MB objects from: the stack, the C++ free store, and a custom-written memory pool (the implementation of Pool appears at the end of this post).
#include <chrono>
#include <iostream>
#include <array>
#include "Pool.h"
class BigObject {
public:
//Each BigObject occupies 1MB of RAM
static const int32_t NUM_BYTES{1000 *1024};
void reset() {} //Required by the Pool class template
void setFirstChar(char c) {byteArray[0] = c;}
private:
std::array<char, NUM_BYTES> byteArray{};
};
//Compare the performance of three types of memory allocation:
//Stack, free store (heap), custom-written pool
int main() {
using namespace std::chrono; //Reduce verbosity of subsequent code
constexpr int32_t NUM_ALLOCS{1000};
void processObj(BigObject* obj);
//Time heap allocations
auto ts = system_clock::now();
for(int32_t i=0; i<NUM_ALLOCS; ++i) {
BigObject* obj{new BigObject{}};
//Do stuff.......
processObj(obj);
}
auto te = system_clock::now();
std::cout << "Heap Allocations took "
<< duration_cast<milliseconds>(te-ts).count()
<< " milliseconds"
<< std::endl;
//Time stack allocations
ts = system_clock::now();
for(int32_t i=0; i<NUM_ALLOCS; ++i) {
BigObject obj{};
//Do stuff.......
processObj(&obj);
} //obj is auto-destroyed here
te = system_clock::now();
std::cout << "Stack Allocations took "
<< duration_cast<milliseconds>(te-ts).count()
<< " milliseconds"
<< std::endl;
//Pool construction time
ts = system_clock::now();
Pool<BigObject, NUM_ALLOCS> objPool;
te = system_clock::now();
std::cout << "Pool construction took "
<< duration_cast<milliseconds>(te-ts).count()
<< " milliseconds"
<< std::endl;
//Time pool allocations
ts = system_clock::now();
for(int32_t i=0; i<NUM_ALLOCS; ++i) {
BigObject* poolObj{objPool.acquire()};
//Do Stuff.......
processObj(poolObj);
}
te = system_clock::now();
std::cout << "Pool Allocations took "
<< duration_cast<milliseconds>(te-ts).count()
<< " milliseconds";
}
void processObj(BigObject* obj) {
obj->setFirstChar('a');
}
The results for a typical program run (gcc 4.9.2, cygwin/Win10, compiler) are shown as follows:

As expected, stack allocation is much faster than heap allocation (3X in this case) because there is no such thing as a “fragmented” stack. The interesting result is how much faster custom pool allocation is than either of the two “standard” out of the box methods. Since each object is 1MB in size, and all of the memory managed by the pool is allocated only once (during construction of the pool object), dynamically acquiring and releasing pointers to the pre-constructed pool objects during runtime is blazingly fast compared to creating a lumbering 1MB object every time the user code needs one.
After you peruse the Pool implementation that follows, I’d love to hear your comments on this post. I’d also appreciate it if you could try to replicate the results I got.
The Pool Class Template – std::array Implementation
Here is my implementation of the Pool class used in the above test code. Note that the Pool class does not use any dynamically resizable STL containers in its implementation. It uses the smarter C++ implementation of the plain ole statically allocated C array. Some safety-critical domains require that no dynamic memory allocation is performed post-initialization – all memory must be allocated either at compile time or upon program initialization.
//Pool.h
#ifndef POOL_H_
#define POOL_H_
#include <array>
#include <algorithm>
#include <memory>
// The OBJ template argument supplied by the user
// must have a publicly defined default ctor and a publicly defined
// OBJ::reset() member function that cleans the object innards so that it
// can be reused again (if needed).
template<typename OBJ, int32_t NUM_OBJS>
class Pool {
public:
//RAII: Fill up the _available array with newly allocated objects.
//Since all objects are available for the user to "acquire"
//on initialization, fill up the _inUse array will nullptrs.
Pool(){
//Fill the _available array with default-constructed objects
std::for_each(std::begin(_available), std::end(_available),
[](OBJ*& mem){mem = new OBJ{};});
//Since no objects are currently in use, fill the _inUse array
//with nullptrs
std::for_each(std::begin(_inUse), std::end(_inUse),
[](OBJ*& mem){mem = nullptr;});
}
//Allows a user to acquire an object to manipulate as she wishes
OBJ* acquire() {
//Try to find an available object
auto iter = std::find_if(std::begin(_available), std::end(_available),
[](OBJ* mem){return (mem not_eq nullptr);});
//Is the pool exhausted?
if(iter == std::end(_available)) {
return nullptr; //Replace this with a "throw" if you need to.
}
else {
//Whoo hoo! An object is available for usage by the user
OBJ* mem{*iter};
//Mark it as in-use in the _available array
*iter = nullptr;
//Find a spot for it in the _inUse list
iter = std::find(std::begin(_inUse), std::end(_inUse), nullptr);
//Insert it into the _inUse list. We don't
//have to check for iter == std::end(_inUse)
//because we are fully in control!
*iter = mem;
//Finally, return the object to the user
return mem;
}
}
//Returns an object to the pool
void release(OBJ* obj) {
//Ensure that the object is indeed in-use. If
//the user gives us an address that we don't own,
//we'll have a leak and bad things can happen when we
//delete the memory during Pool destruction.
auto iter = std::find(std::begin(_inUse), std::end(_inUse), obj);
//Simply return control back to the user
//if we didn't find the object in our
//in-use list
if(iter == std::end(_inUse)) {
return;
}
else {
//Clear out the innards of the object being returned
//so that the next user doesn't have to "remember" to do it.
obj->reset();
//temporarily hold onto the object while we mark it
//as available in the _inUse array
OBJ* mem{*iter};
//Mark it!
*iter = nullptr;
//Find a spot for it in the _available list
iter = std::find(std::begin(_available), std::end(_available), nullptr);
//Insert the object's address into the _available array
*iter = mem;
}
}
~Pool() {
//Cleanup after ourself: RAII
std::for_each(std::begin(_available), std::end(_available),
std::default_delete<OBJ>());
std::for_each(std::begin(_inUse), std::end(_inUse),
std::default_delete<OBJ>());
}
private:
//Keeps track of all objects available to users
std::array<OBJ*, NUM_OBJS> _available;
//Keeps track of all objects in-use by users
std::array<OBJ*, NUM_OBJS> _inUse;
};
#endif /* POOL_H_ */
The Pool Class Template – std::multiset Implementation
For grins, I also implemented the Pool class below using std::multiset to keep track of the available and in-use objects. For large numbers of objects, the acquire()/release() calls will most likely be faster than their peers in the std::array implementation, but the implementation violates the “no post-intialization dynamically allocated memory allowed” requirement – if you have one.
Since the implementation does perform dynamic memory allocation during runtime, it would probably make more sense to pass the size of the pool via the constructor rather than as a template argument. If so, then functionality can be added to allow users to resize the pool during runtime if needed.
//Pool.h
#ifndef POOL_H_
#define POOL_H_
#include <algorithm>
#include <set>
#include <memory>
// The OBJ template argument supplied by the user
// must have a publicly defined default ctor and a publicly defined
// OBJ::reset() member function that cleans the object innards so that it
// can be reused again (if needed).
template<typename OBJ, int32_t NUM_OBJS>
class Pool {
public:
//RAII: Fill up the _available set with newly allocated objects.
//Since all objects are available for the user to "acquire"
//on initialization, fill up the _inUse set will nullptrs.
Pool(){
for(int32_t i=0; i<NUM_OBJS; ++i) {
_available.insert(new OBJ{});
_inUse.insert(nullptr);
}
}
//Allows a user to acquire an object to manipulate as she wishes
OBJ* acquire() {
//Try to find an available object
auto iter = std::find_if(std::begin(_available), std::end(_available),
[](OBJ* mem){return (mem not_eq nullptr);});
//Is the pool exhausted?
if(iter == std::end(_available)) {
return nullptr; //Replace this with a "throw" if you need to.
}
else {
//Whoo hoo! An object is available for usage by the user
OBJ* mem{*iter};
//Mark it as in-use in the _available set
_available.erase(iter);
_available.insert(nullptr);
//Find a spot for it in the _inUse set
iter = std::find(std::begin(_inUse), std::end(_inUse), nullptr);
//Insert it into the _inUse set. We don't
//have to check for iter == std::end(_inUse)
//because we are fully in control!
_inUse.erase(iter);
_inUse.insert(mem);
//Finally, return the object to the user
return mem;
}
}
//Returns an object to the pool
void release(OBJ* obj) {
//Ensure that the object is indeed in-use. If
//the user gives us an address that we don't own,
//we'll have a leak and bad things can happen when we
//delete the memory during Pool destruction.
auto iter = std::find(std::begin(_inUse), std::end(_inUse), obj);
//Simply return control back to the user
//if we didn't find the object in our
//in-use set
if(iter == std::end(_inUse)) {
return;
}
else {
//Clear out the innards of the object being returned
//so that the next user doesn't have to "remember" to do it.
obj->reset();
//temporarily hold onto the object while we mark it
//as available in the _inUse array
OBJ* mem{*iter};
//Mark it!
_inUse.erase(iter);
_inUse.insert(nullptr);
//Find a spot for it in the _available list
iter = std::find(std::begin(_available), std::end(_available), nullptr);
//Insert the object's address into the _available array
_available.erase(iter);
_available.insert(mem);
}
}
~Pool() {
//Cleanup after ourself: RAII
std::for_each(std::begin(_available), std::end(_available),
std::default_delete<OBJ>());
std::for_each(std::begin(_inUse), std::end(_inUse),
std::default_delete<OBJ>());
}
private:
//Keeps track of all objects available to users
std::multiset<OBJ*> _available;
//Keeps track of all objects in-use by users
std::multiset<OBJ*> _inUse;
};
#endif /* POOL_H_ */
Unit Testing
In case you were wondering, I used Phil Nash’s lightweight Catch unit testing framework to verify/validate the behavior of both Pool class implementations:
TEST_CASE( "Allocations/Deallocations", "[Pool]" ) {
constexpr int32_t NUM_ALLOCS{2};
Pool<BigObject, NUM_ALLOCS> objPool;
BigObject* obj1{objPool.acquire()};
REQUIRE(obj1 not_eq nullptr);
BigObject* obj2 = objPool.acquire();
REQUIRE(obj2 not_eq nullptr);
objPool.release(obj1);
BigObject* obj3 = objPool.acquire();
REQUIRE(obj3 == obj1);
BigObject* obj4 = objPool.acquire();
REQUIRE(obj4 == nullptr);
objPool.release(obj2);
BigObject* obj5 = objPool.acquire();
REQUIRE(obj5 == obj2);
}
==============================================
All tests passed (5 assertions in 1 test case)
C++11 Features
For fun, I listed the C++11 features I used in the source code:
- * auto
- * std::array<T, int>
- * std::begin(), std::end()
- * nullptr
- * lambda functions
- * Brace initialization { }
- * std::chrono::system_clock, std::chrono::duration_cast<T>
- * std::default_delete<T>
Did I miss any features/classes? How would the C++03 implementations stack up against these C++11 implementations in terms of readability/understandability?
Easier To Use, And More Expressive
One of the goals for each evolutionary increment in C++ is to decrease the probability of an average programmer from making mistakes by supplanting “old style” features/idioms with new, easier to use, and more expressive alternatives. The following code sample attempts to show an example of this evolution from C++98/03 to C++11 to C++14.

In C++98/03, there were two ways of clearing out the set of inner vectors in the vector-of-vectors-of-doubles data structure encapsulated by MyClass. One could use a plain ole for-loop or the std::for_each() STL algorithm coupled with a remotely defined function object (ClearVecFunctor). I suspect that with the exception of clever language lawyers, blue collar programmers (like me) used the simple for-loop option because of its reduced verbosity and compactness of expression.
With the arrival of C++11 on the scene, two more options became available to programmers: the range-for loop, and the std::for_each() algorithm combined with an inline-defined lambda function. The range-for loop eliminated the chance of “off-by-one” errors and the lambda function eliminated the inconvenience of having to write a remotely located functor class.
The ratification of the C++14 standard brought yet another convenient option to the table: the polymorphic lambda. By using auto in the lambda argument list, the programmer is relieved of the obligation to explicitly write out the full type name of the argument.
This example is just one of many evolutionary improvements incorporated into the language. Hopefully, C++17 will introduce many more.
Note: The code compiles with no warnings under gcc 4.9.2. However, as you can see in the image from the bug placed on line 41, the Eclipse CDT indexer has not caught up yet with the C++14 specification. Because auto is used in place of the explicit type name in the lambda argument list, the indexer cannot resolve the std::vector::clear() member function.
8/26/15 Update – As a result of reader code reviews provided in the comments section of this post, I’ve updated the code as follows:
8/29/15 Update – A Fix to the Line 27 begin-begin bug:

The Move That Wasn’t
While trying to duplicate the results I measured in my “Time To Get Moving!” post, an astute viewer posted this comment:
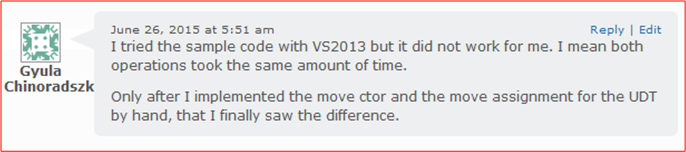
For your convenience, I re-list the code in question here for your inspection:
#include <iostream>
#include <vector>
#include <utility>
#include <chrono>
using namespace std;
struct Msg{
vector<double> vDoubs;
Msg(const int NUM_ELS) : vDoubs(NUM_ELS){
}
};
int main() {
//Construct a big Msg object!
const int NUM_ELS = 10000000;
Msg msg1{NUM_ELS};
//reduce subsequent code verbosity
using std::chrono::steady_clock;
using std::chrono::duration_cast;
using std::chrono::microseconds;
//Measure the performance of
//the "free" copy operations
auto tStart = steady_clock::now();
Msg msg2{msg1}; //copy ctor
msg1 = msg2; //copy assignment
auto tElapsed = steady_clock::now() - tStart;
cout << "Copy ops took "
<< duration_cast<microseconds>(tElapsed).count()
<< " microseconds\n";
//Measure the performance of
//the "free" move operations
tStart = steady_clock::now();
Msg msg3{std::move(msg1)}; //move ctor
msg1 = std::move(msg3); //move assignment
tElapsed = steady_clock::now() - tStart;
cout << "Move ops took "
<< duration_cast<microseconds>(tElapsed).count()
<< " microseconds\n";
cout << "Size of moved-from object = "
<< msg3.vDoubs.size();
} //"free" dtor is executed here for msg1, msg2, msg3
Sure enough, I duplicated what my friend Gyula discovered about the “move” behavior of the VS2013 C++ compiler:
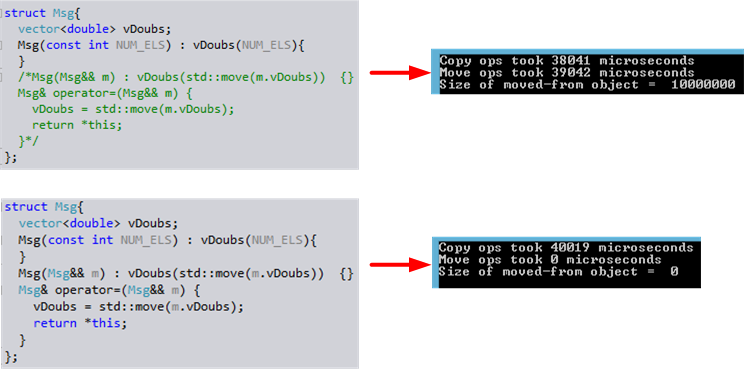
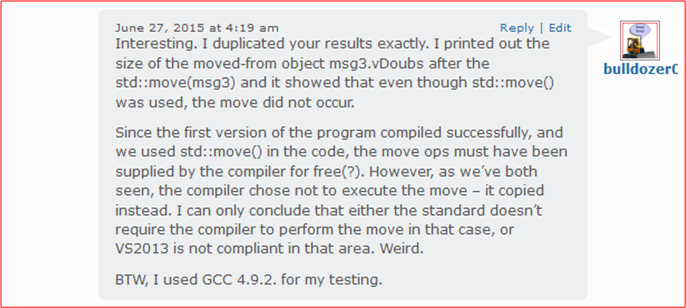
Intrigued by the finding, I dove deeper into the anomaly and dug up these statements in the fourth edition of Bjarne Stroustrup’s “The C++ Programming Language“:

Since the Msg structure in the code listing does not have any copy or move operations manually defined within its definition, the compiler is required to generate them by default. However, since Bjarne doesn’t state that a compiler is required to execute moves when the programmer explicitly directs it to with std::move() expressions, maybe the compiler isn’t required to do so. However, common sense dictates that it should. Hopefully, the next update to the VS2013 compiler will do the right thing – like GCC (and Clang?) currently does.
Time To Get Moving!
Prior to C++11, for every user-defined type we wrote in C++03, all standards-conforming C++ compilers gave us:
- a “free” copy constructor
- a “free” copy assignment operator
- a “free” default constructor
- a “free” destructor
The caveat is that we only got them for free if we didn’t manually override the compiler and write them ourselves. And unless we defined reference or pointer members inside of our type, we didn’t have to manually write them.
Starting from C++11 on, we not only get those operations for free for our user-defined types, we also get these turbo-boosters:
- a “free” move constructor
- a “free” move assignment operator
In addition, all of the C++ standard library containers have been “move enabled“.
When I first learned how move semantics worked and why this new core language feature dramatically improved program performance over copying, I started wondering about user-defined types that wrapped move-enabled, standard library types. For example, check out this simple user-defined Msg structure that encapsulates a move-enabled std::vector.

Logic would dictate that since I get “move” operations from the compiler for free with the Msg type as written, if I manually “moved” a Msg object in some application code, the compiler would “move” the vDoubs member under the covers along with it – for free.
Until now, I didn’t test out that deduction because I heard my bruh Herb Sutter say in a video talk that deep moves came for free with user-defined types as long as each class member in the hierarchical composition is also move-enabled. However, in a more recent video, I saw an excellent C++ teacher explicitly write a move constructor for a class similar to the Msg struct above:
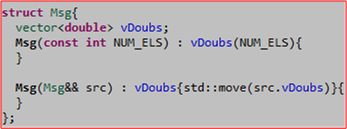
D’oh! So now I was confused – and determined to figure out was was going on. Here is the program that I wrote to not only verify that manually written “move” operations are not required for the Msg struct, but to also measure the performance difference between moving and copying:

First, the program built cleanly as expected because the compiler provided the free “move” operations for the Msg struct. Second, the following, 5-run, output results proved that the compiler did indeed perform the deep, under the covers, “move” that my man Herb promised it would do. If the deep move wasn’t executed, there would have been no noticeable difference in performance between the move and copy operations.
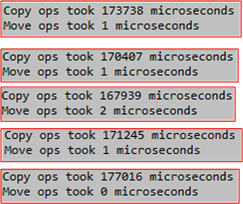
From the eye-popping performance difference shown in the results, we should conclude that it’s time to start replacing copy operations in our code with “move” operations wherever it makes sense. The only thing to watch out for when moving objects from one place to another is that in the scope of the code that performs the move, the internal state of the moved-from object is not needed or used by the code following the move. The following code snippet, which prints out 0, highlights this behavior.

Whence Actors?
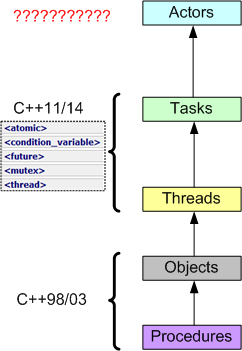
While sketching out the following drawing, I was thinking about the migration from sequential to concurrent programming driven by the rise of multicore machines. Can you find anything wrong with it?
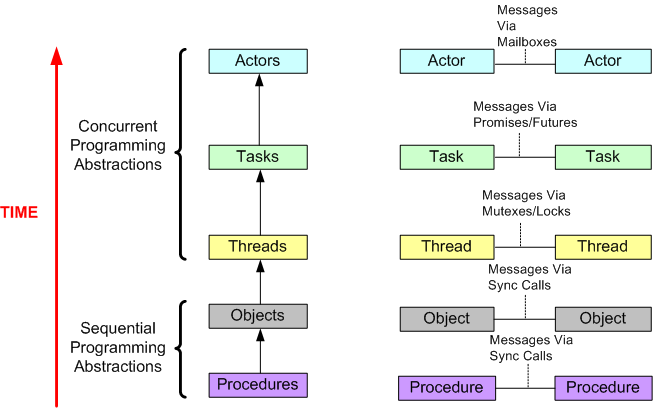
Right out of the box, C++ provided Objects (via classes) and procedures (via free standing functions). With C++11, standardized support for threads and tasks finally arrived to the language in library form. I can’t wait for Actors to appear in….. ?
Make Simple Tasks Simple
In the slide deck that Bjarne Stroustrup presented for his “Make Simple Tasks Simple” CppCon keynote speech, he walked through a progression of refactorings that reduced an (arguably) difficult-to-read, multi-line, C++98 code segment (that searches a container for an element matching a specific pattern) into an expressive, C++11 one liner:
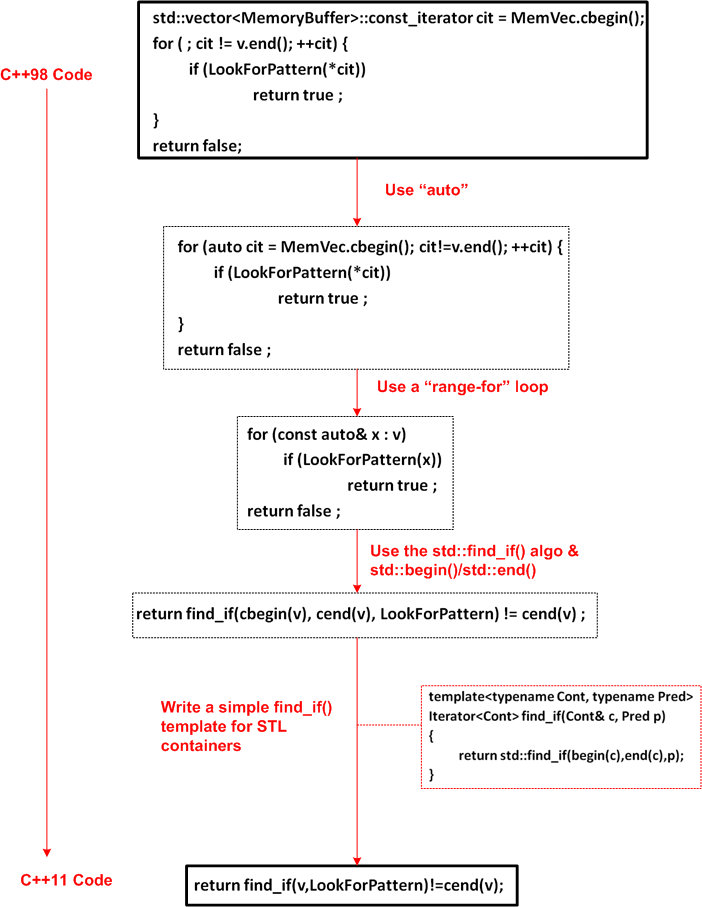
Some people may think the time spent refactoring the original code was a pre-mature optimization and, thus, a waste of time. But that wasn’t the point. The intent of the example was to illustrate several features of C++11 that were specifically added to the language to allow sufficiently proficient programmers to “make simple tasks simple (to program)“.
Note: After the fact, I discovered that “MemVec” should be replaced everywhere with “v” (or vice versa), but I was too lazy to fix the pic :). Can you find any other bugs in the code?
Not Just Expert Friendly
Check out this snippet from one of Bjarne Stroustrup’s CppCon keynote slides:

Now take a glance at one of Herb Sutter’s CppCon talk slides:

Bjarne’s talk was titled “Make Simple Tasks Simple” and Herb’s talk was tiled “Back To The Basics!: Modern C++ Style“. Since I abhor unessential complexity, I absolutely love the fact that these two dedicated gentlemen are spearheading the effort to evolve C++ in two directions simultaneously: increasing both expert-friendliness AND novice-friendliness.
By counterbalancing the introduction of advanced features like variadic templates and forwarding references with simpler features like range-for loops, nullptr, and brace-initialization, I think Bjarne and Herb (and perhaps other community members I don’t know about) are marvelously succeeding at the monumental task of herding cats. To understand what I mean, take a look at another one of Herb’s slides:
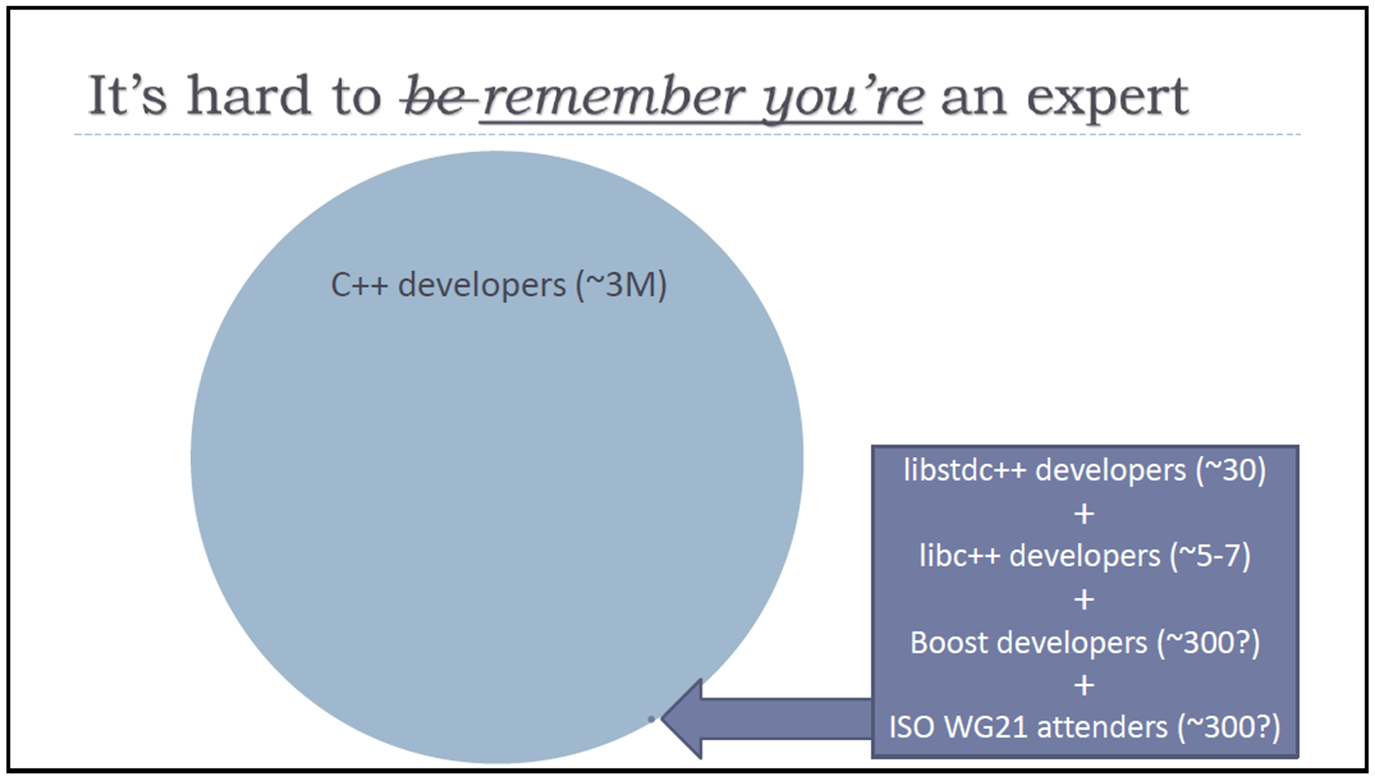
Do you see that teeny tiny dot at the end of the big arrow down on the lower right edge of the circle? Well, I don’t come anywhere close to qualifying for membership with the cats inside that dot… and I’d speculate that most advanced feature proposals and idiom ideas, whether they are understandable/teachable to mere mortals or not, originate from the really smart cats within that dot.

By gently but doggedly communicating the need for lowering the barriers to entry for potentially new C++ users while still navigating the language forward into unchartered waters, I’m grateful to Herb and Bjarne. Because of these men, the ISO C++ committee actually works – and it is indeed amazing for any committee to “work“.
Spike To Learn
As one of the responsibilities on my last project, I had to interface one of our radars to a 10+ year old, legacy, command-and-control system built by another company. My C++11 code was required to receive commands from the control system and send radar data to it via UDP datagrams over a LAN that connects the two systems together.
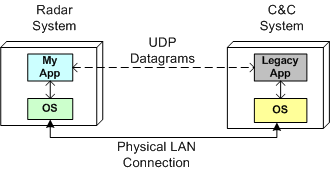
It’s unfortunate, but we won’t get a standard C++ networking library until the next version of the C++ standard gets ratified in 2017. However, instead of using the low-level C sockets API to implement the interface functionality, I chose to use the facilities of the Poco::Net library.

Poco is a portable, well written, and nicely documented set of multi-function, open source C++ libraries. Among other nice, higher level, TCP/IP and http networking functionality, Poco::Net provides a thin wrapper layer around the native OS C-language sockets API.
Since I had never used the Poco::Net API before, I decided to spike off the main trail and write a little test program to learn the API before integrating the API calls directly into my production code. I use the “Spike To Learn” best practice whenever I can.
Here is the finished and prettied-up spike program for your viewing pleasure:
#include <string>
#include <iostream>
#include "Poco/Net/SocketAddress.h"
#include "Poco/Net/DatagramSocket.h"
using Poco::Net::SocketAddress;
using Poco::Net::DatagramSocket;
int main() {
//simulate a UDP legacy app bound to port 15001
SocketAddress legacyNodeAddr{"localhost", 15001};
DatagramSocket legacyApp{legacyNodeAddr}; //create & bind
//simulate my UDP app bound to port 15002
SocketAddress myAddr{"localhost", 15002};
DatagramSocket myApp{myAddr}; //create & bind
//myApp creates & transmits a message
//encapsulated in a UDP datagram to the legacyApp
char myAppTxBuff[]{"Hello legacyApp"};
auto msgSize = sizeof(myAppTxBuff);
myApp.sendTo(myAppTxBuff,
msgSize,
legacyNodeAddr);
//legacyApp receives a message
//from myApp and prints its payload
//to the console
char legacyAppRxBuff[msgSize];
legacyApp.receiveBytes(legacyAppRxBuff, msgSize);
std::cout << std::string{legacyAppRxBuff}
<< std::endl;
//legacyApp creates & transmits a message
//to myApp
char legacyAppTxBuff[]{"Hello myApp!"};
msgSize = sizeof(legacyAppTxBuff);
legacyApp.sendTo(legacyAppTxBuff,
msgSize,
myAddr);
//myApp receives a message
//from legacyApp and prints its payload
//to the console
char myAppRxBuff[msgSize];
myApp.receiveBytes(myAppRxBuff, msgSize);
std::cout << std::string{myAppRxBuff}
<< std::endl;
}
As you can see, I used the Poco::Net::SocketAddress and Poco::Net::DatagramSocket classes to simulate the bi-directional messaging between myApp and the legacyApp on one machine. The code first transmits the text message “Hello legacyApp!” from myApp to the legacyApp; and then it transmits the text message “Hello myApp!” from the legacyApp to myApp.

Lest you think the program doesn’t work 🙂 , here is the console output after the final compile & run cycle:

As a side note, notice that I used C++11 brace-initializers to uniformly initialize every object in the code – except for one: the msgSize object. I had to fallback and use the “=” form of initialization because “auto” does not yet play well with brace-initializers. For who knows why, the type of obj in a statement of the form “auto obj{5};” is deduced to be a std::initializer_list<T> instead of a simple int. I think this strange inconvenience will be fixed in C++17. It may have been fixed already in the recently ratified C++14 standard, but I don’t know for sure. Do you?
Multiple, Independent Sources Of Information On The Same Topic
I can’t rave enough about how great a safaribooksonline.com subscription is for writing code. Take a look at this screenshot:
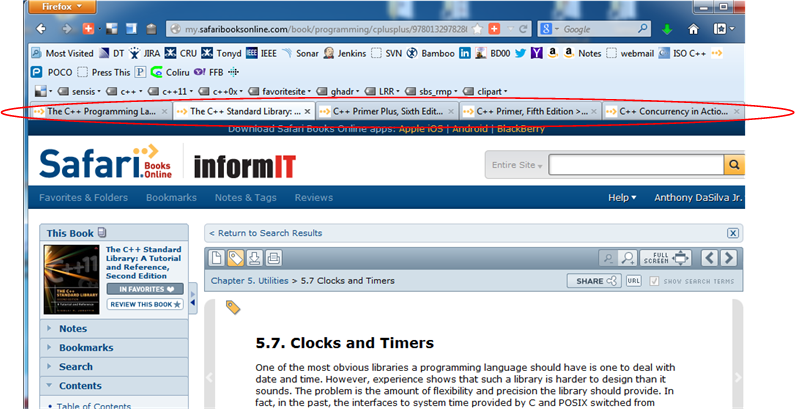
As you can hopefully make out, I have five Firefox tabs open to the following C++11 programming books:
- The C++ Programming Language, 4th Edition – Bjarne Stroustrup
- The C++ Standard Library: A Tutorial and Reference (2nd Edition) – Nicolai M. Josuttis
- C++ Primer Plus (6th Edition) – Stephen Prata
- C++ Primer (5th Edition) – Stanley B. Lippman, Josée Lajoie, Barbara E. Moo
- C++ Concurrency in Action: Practical Multithreading – Anthony Williams
A subscription is a bit pricey, but if you can afford it, I highly recommend buying one. You’ll not only write better code faster, you’ll amplify your learning experience by an order of magnitude from having the capability to effortlessly switch between multiple, independent sources of information on the same topic. W00t!
Game Changer
Even though I’m a huge fan of the man, I was quite skeptical when I heard Bjarne Stroustrup enunciate: “C++ feels like a new language“. Of course, Bjarne was talking about the improvements brought into the language by the C++11 standard.
Well, after writing C++11 production code for almost 2 years now (17 straight sprints to be exact), I’m no longer skeptical. I find myself writing code more fluidly, doing battle with the problem “gotchas” instead of both the problem and the language gotchas. I don’t have to veer off track to look up language technical details and easily forgotten best-practices nearly as often as I did in the pre-C++11 era.
It seems that the authors of the “High Integrity C++” coding standard agree with my assessment. In a white paper summarizing the changes to their coding standard, here is what they have to say:

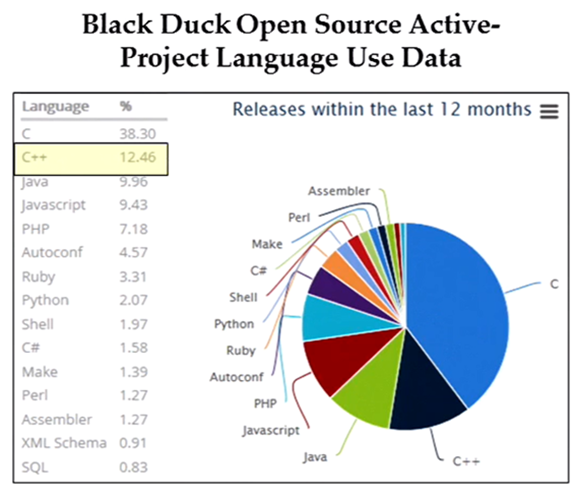
Even though C++’s market niche has shrunk considerably in the 21st century, it is still widely used throughout the industry. The following chart, courtesy of Scott Meyers’ recent talk at Facebook, shows that the old-timer still has legs. The pending C++14 and C++17 updates virtually guarantee its relevance far into the future; just like the venerable paper clip and spring-loaded mouse trap.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

