Archive
Sloppy Coding II
Introduction
In the prequel to this post, “Sloppy Coding“, I showed some rather trivial, small-scoped, examples of antiquated C++ coding style currently present in a hugely successful, widely deployed, open source code base. In this follow up post, I’ll do the same, but at the higher, class level scope.
Hey, I troll often, and this is what trollers do. 🙂

The Class Definition Under Assault
If you’re a young, advancing, C++ programmer, you may want to think about avoiding the bad design decisions that I rag about in the following class definition:
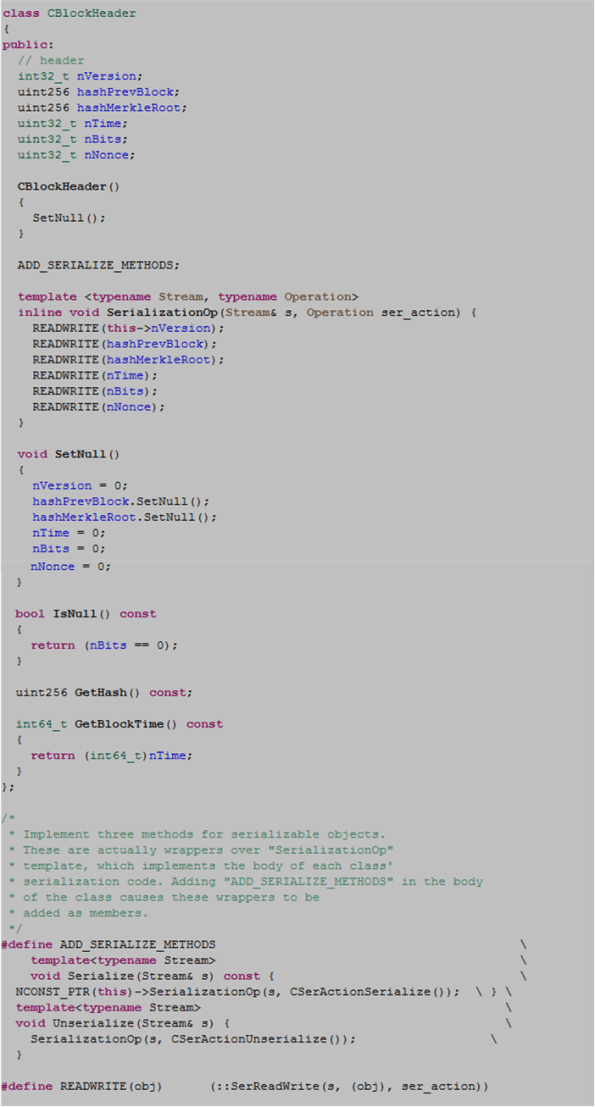
Where Are The Private Members?
After scanning through the class definition for the first time, the most blatantly obvious faux pax I noticed right off the bat was the “everything is public!” violation of the golden rule of encapsulation. If the intent was for CBlockHeader to be a user-defined type with no need to establish and preserve any invariant conditions, then it should have been declared as a less verbose struct .

I know, I know, that’s another nitpick. But there’s more to it than meets the eye. Notice the last three CBlockHeader class member functions are declared const. Since users can directly reach into a skinless CBlockHeader object to mutate its internal state at will, nice users can be unsafely stomped on by cheaters (Jihan Wu? 🙂 ) in between calls.
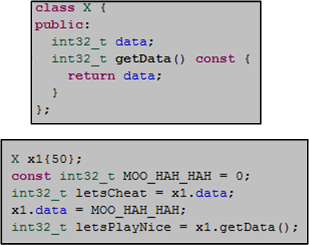
The cheater gets the 50, and the nice guy gets the goose egg.
Where Are The Initializers?
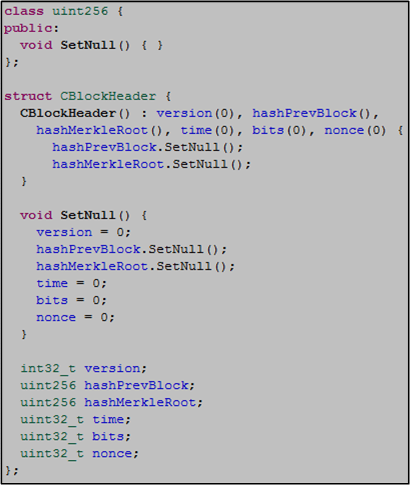
Notice that the CBlockHeader class constructor does not contain an initialization list – all initialization is performed in the constructor body via a call to SetNull().
An initialization explicitly states that initialization, rather than assignment, is done and can be more elegant and efficient (CppCoreGuidelines). It also prevents “use before set” errors. For a slight performance bump upon each CBlockHeader object instantiation and good C++ style, the struct implementation of the CBlockHeader constructor should look like this, no?
Nasty Pre-processor Hackros, Turtles All The Way Down
Ugh, I don’t even know what to say about the dangerous 1980’s C pre-processor macro bombs planted in the class definition: ADD_SERIAL_METHODS, NCONST_PTR (nested within ADD_SERIAL_METHODS) , and READWRITE. Compared to the design flaws pointed out previously, these abominations make the class uncomfortably uninhabitable for a large population of otherwise competent C++ programmers.
Bjarne Stroustrup is the creator of C++ and a long time hero of mine. He’s been passionately evolving the language (C With Classes, C++, C++98, C++11, C++14, C++17) and a leading force in the community since the 80s. Mr. Stroustrup has this to say about Hacros:

A safer, more maintainable, alternative to the current Hack-Horiffic design would be to wrap the required inline functionality in class templates and have CBlockHeader publicly extend those classes. The details are left to the aspiring student.
Fini
Ok, ok. EVERYONE on social media knows that trolls beget trolls. So, troll away at this post. Rip me to shreds. I deserve payback.

The “unsigned” Conundrum
A few weeks ago, CppCon16 conference organizer Jon Kalb gave a great little lightning talk titled “unsigned: A Guideline For Better Code“. Right up front, he asked the audience what they thought this code would print out to the standard console:

Even though -1 is obviously less 1, the program prints out “a is not less than b“. WTF?
The reason for the apparently erroneous result is due to the convoluted type conversion rules inherited from C regarding unsigned/signed types.
Before evaluating the (a < b) expression, the rules dictate that the signed int object, a, gets implicitly converted to an unsigned int type. For an 8 bit CPU, the figure below shows how the bit pattern 0xFF is interpreted differently by C/C++ compilers depending upon how it is declared:
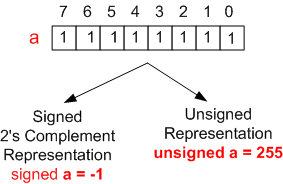
Thus, after the implicit type conversion of a from -1 to 255, the comparison expression becomes (255 < 1) – which produces the “a is not less than b” output.
Since it’s unreasonable to expect most C++ programmers to remember the entire arcane rule set for implicit conversions/promotions, what heuristic should programmers use to prevent nasty unsigned surprises like Mr. Kalb’s example? Here is his list of initial candidates:

If you’re trolling this post and you’re a C++ hater, then the first guideline is undoubtedly your choice :). If you’re a C++ programmer, the second two are pretty much impractical – especially since unsigned (in the form of size_t) is used liberally throughout the C++ standard library. (By the way, I once heard Bjarne Stroustrup say in a video talk that requiring size_t to be unsigned was a mistake). The third and fourth guidelines are reasonable suggestions; and those are the ones I use in writing my own code and reviewing the code of others.
At the end of his interesting talk, Mr. Kalb presented his own guideline:

I think Jon’s guideline is a nice, thoughtful addition to the last two guidelines on the previous chart. I would like to say that “Don’t use “unsigned” for quantities” subsumes those two, but I’m not sure it does. What do you think?
Zero Out Of Ten
In a recent talk at Cambridge University, Bjarne Stroustrup presented this slide to his audience:

Although lots of hard work has been performed by some very smart people over the years in developing these features, Mr. Stroustrup (sadly) went on to say that none of them will be present in the formal C++17 specification. The last sentence on the slide succinctly summarizes why.
The Problem, The Culprits, The Hope
The Problem
Bjarne Stroustrup’s keynote speech at CppCon 2015 was all about writing good C++11/14 code. Although “modern” C++ compilers have been in wide circulation for four years, Bjarne still sees:

I’m not an elite, C++ committee-worthy, programmer, but I can relate to Bjarne’s frustration. Some time ago, I stumbled upon this code during a code review:
class Thing{};
std::vector<Thing> things{};
const int NUM_THINGS{2000};
for(int i=0; i<NUM_THINGS; ++i)
things.push_back(*(new Thing{}));
Upon seeing the naked “new“, I searched for a matching loop of “delete“s. Since I did not find one, I ran valgrind on the executable. Sure enough, valgrind found the memory leak. I flagged the code as having a memory leak and suggested this as a less error-prone substitution:
class Thing{};
std::vector<Thing> things{};
const int NUM_THINGS{2000};
for(int i=0; i<NUM_THINGS; ++i)
things.push_back(Thing{});
Another programmer suggested an even better, loopless, alternative:
class Thing{};
std::vector<Thing> things{};
const int NUM_THINGS{2000};
things.resize(NUM_THINGS);
Sadly, the author blew off the suggestions and said that he would add the loop of “delete“s to plug the memory leak.
The Culprits
A key culprit in keeping the nasty list of bad programming habits alive and kicking is that…
Confused, backwards-looking teaching is (still) a big problem – Bjarne Stroustrup
Perhaps an even more powerful force keeping the status quo in place is that some (many?) companies simply don’t invest in their employees. In the name of fierce competition and the never-ending quest to increase productivity (while keeping wages flat so that executive bonuses can be doled out for meeting arbitrary numbers), these 20th-century-thinking dinosaurs micro-manage their employees into cranking out code 8+ hours a day while expecting the workforce to improve on their own time.
The Hope
In an attempt to sincerely help the C++ community of over 4M programmers overcome these deeply ingrained, unsafe programming habits, Mr. Stroustrup’s whole talk was about introducing and explaining the “CPP Core Guidelines” (CGC) document and the “Guidelines Support Library” (GSL). In a powerful one-two punch, Herb Sutter followed up the next day with another keynote focused on the CGC/GSL.
The CGC is an open source repository currently available on GitHub. And as with all open source projects, it is a work in progress. The guidelines were hoisted onto GitHub to kickstart the transformation from obsolete to modern programming.
The guidelines are focused on relatively higher-level issues, such as interfaces, resource management, memory management, and concurrency. Such rules affect application architecture and library design. Following the rules will lead to code that is statically type safe, has no resource leaks, and catches many more programming logic errors than is common in code today. And it will run fast – you can afford to do things right. We are less concerned with low-level issues, such as naming conventions and indentation style. However, no topic that can help a programmer is out of bounds.
It’s a noble and great goal that Bjarne et al are striving for, but as the old saying goes, “you can lead a horse to water, but you can’t make him drink“. In the worst case, the water is there for the taking, but you can’t even find anyone to lead the horse to the oasis. Nevertheless, with the introduction of the CGC, we at least have a puddle of water in place. Over time, the open source community will grow this puddle into a lake.

The Move That Wasn’t
While trying to duplicate the results I measured in my “Time To Get Moving!” post, an astute viewer posted this comment:
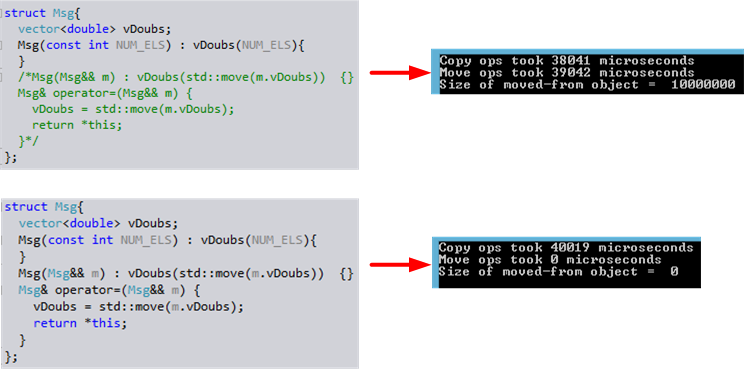
For your convenience, I re-list the code in question here for your inspection:
#include <iostream>
#include <vector>
#include <utility>
#include <chrono>
using namespace std;
struct Msg{
vector<double> vDoubs;
Msg(const int NUM_ELS) : vDoubs(NUM_ELS){
}
};
int main() {
//Construct a big Msg object!
const int NUM_ELS = 10000000;
Msg msg1{NUM_ELS};
//reduce subsequent code verbosity
using std::chrono::steady_clock;
using std::chrono::duration_cast;
using std::chrono::microseconds;
//Measure the performance of
//the "free" copy operations
auto tStart = steady_clock::now();
Msg msg2{msg1}; //copy ctor
msg1 = msg2; //copy assignment
auto tElapsed = steady_clock::now() - tStart;
cout << "Copy ops took "
<< duration_cast<microseconds>(tElapsed).count()
<< " microseconds\n";
//Measure the performance of
//the "free" move operations
tStart = steady_clock::now();
Msg msg3{std::move(msg1)}; //move ctor
msg1 = std::move(msg3); //move assignment
tElapsed = steady_clock::now() - tStart;
cout << "Move ops took "
<< duration_cast<microseconds>(tElapsed).count()
<< " microseconds\n";
cout << "Size of moved-from object = "
<< msg3.vDoubs.size();
} //"free" dtor is executed here for msg1, msg2, msg3
Sure enough, I duplicated what my friend Gyula discovered about the “move” behavior of the VS2013 C++ compiler:
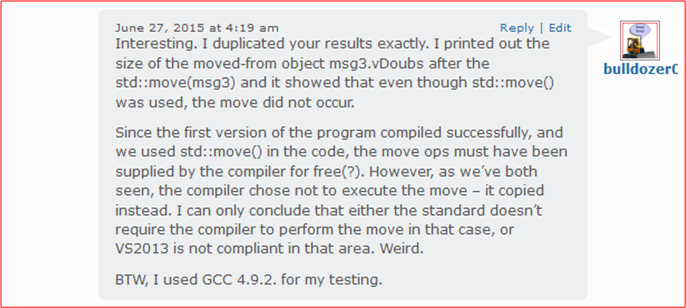
Intrigued by the finding, I dove deeper into the anomaly and dug up these statements in the fourth edition of Bjarne Stroustrup’s “The C++ Programming Language“:

Since the Msg structure in the code listing does not have any copy or move operations manually defined within its definition, the compiler is required to generate them by default. However, since Bjarne doesn’t state that a compiler is required to execute moves when the programmer explicitly directs it to with std::move() expressions, maybe the compiler isn’t required to do so. However, common sense dictates that it should. Hopefully, the next update to the VS2013 compiler will do the right thing – like GCC (and Clang?) currently does.
Holier Than Thou
Since C++ (by deliberate design) does not include a native garbage collector or memory compactor, programs that perform dynamic memory allocation and de-allocation (via explicit or implicit use of the “new” and “delete” operators) cause small “holes” to accumulate in the free store over time. I guess you can say that C++ is “holier than thou“. 😦  Mind you, drilling holes in the free store is not the same as leaking memory. A memory leak is a programming bug that needs to be squashed. A fragmented free store is a “feature“. His holiness can become an issue only for loooong running C++ programs and/or programs that run on hardware with small RAM footprints. For those types of niche systems, the best, and perhaps only, practical options available for preventing any holes from accumulating in your briefs are to eliminate all deletes from the code:
Mind you, drilling holes in the free store is not the same as leaking memory. A memory leak is a programming bug that needs to be squashed. A fragmented free store is a “feature“. His holiness can become an issue only for loooong running C++ programs and/or programs that run on hardware with small RAM footprints. For those types of niche systems, the best, and perhaps only, practical options available for preventing any holes from accumulating in your briefs are to eliminate all deletes from the code:
- Perform all of your dynamic memory allocations at once, during program initialization (global data – D’oh!), and only utilize the CPU stack during runtime for object creation/destruction.
- If your application inherently requires post-initialization dynamic memory usage, then use pre-allocated, fixed size, unfragmentable, pools and stacks to acquire/release data buffers during runtime.
If your system maps into the “holes can freakin’ kill someone” category and you don’t bake those precautions into your software design, then the C++ runtime may toss a big, bad-ass, std::bad_alloc exception into your punch bowl and crash your party if it can’t find a contiguous memory block big enough for your impending new request. For large software systems, refactoring the design to mitigate the risk of a fragmented free store after it’s been coded/tested falls squarely into the expensive and ominous “stuff that’s hard to change” camp. And by saying “stuff that’s hard to change“, I mean that it may be expensive, time consuming, and technically risky to reweave your basket (case). In an attempt to verify that the accumulation of free store holes will indeed crash a program, I wrote this hole-drilling simulator:  Each time through the while loop, the code randomly allocates and deallocates 1000 chunks of memory. Each chunk is comprised of a random number of bytes between 1 and 1MB. Thus, the absolute maximum amount of memory that can be allocated/deallocated during each pass through the loop is 1 GB – half of the 2 GB RAM configured on the linux virtual box I am currently running the code on. The hole-drilling simulator has been running for days – at least 5 straight. I’m patiently waiting for it to exit – and hopefully when it does so, it does so gracefully. Do you know how I can change the code to speed up the time to exit?
Each time through the while loop, the code randomly allocates and deallocates 1000 chunks of memory. Each chunk is comprised of a random number of bytes between 1 and 1MB. Thus, the absolute maximum amount of memory that can be allocated/deallocated during each pass through the loop is 1 GB – half of the 2 GB RAM configured on the linux virtual box I am currently running the code on. The hole-drilling simulator has been running for days – at least 5 straight. I’m patiently waiting for it to exit – and hopefully when it does so, it does so gracefully. Do you know how I can change the code to speed up the time to exit?
Note1: This post doesn’t hold a candle to Bjarne Stroustrup’s thorough explanation of the “holiness” topic in chapter 25 of “Programming: Principles and Practice Using C++, Second Edition“. If you’re a C++ programmer (beginner, intermediate, or advanced) and you haven’t read that book cover-to-cover, then… you should.
Note2: For those of you who would like to run/improve the hole-drilling simulator, here is the non-.png source code listing:
#include
#include
#include
#include
#include
int main() {
//create a functor for generating uniformly
//distributed, contiguous memory chunk sizes between 1 and
//MAX_CHUNK_SIZE bytes
constexpr int32_t MAX_CHUNK_SIZE{1000000};
std::default_random_engine randEng{};
std::uniform_int_distribution distribution{
1, MAX_CHUNK_SIZE};
//load up a vector of NUM_CHUNKS chunks;
//with each chunk randomly sized
//between 1 and MAX_CHUNK_SIZE long
constexpr int32_t NUM_CHUNKS{1000};
std::vector chunkSizes(NUM_CHUNKS); //no init braces!
for(auto& el : chunkSizes) {
el = distribution(randEng);
}
//declare the allocator/deallocator function
//before calling it.
void allocDealloc(std::vector& chunkSizes,
std::default_random_engine& randEng);
//loop until our free store is so "holy"
//that we must bow down to the lord and leave
//the premises!
bool tooManyHoles{};
while(!tooManyHoles) {
try {
allocDealloc(chunkSizes, randEng);
}
catch(const std::bad_alloc&) {
tooManyHoles = true;
}
}
std::cout << "The Free Store Is Too "
<< "Holy to Continue!!!"
<< std::endl;
}
//the function for randomly allocating/deallocating chunks of memory
void allocDealloc(std::vector& chunkSizes,
std::default_random_engine& randEng) {
//create a vector for storing the dynamic pointers
//to each allocated memory block
std::vector<char*> handles{};
//randomize the memory allocations and store each pointer
//returned from the runtime memory allocator
std::shuffle(chunkSizes.begin(), chunkSizes.end(), randEng);
for(const auto& numBytes : chunkSizes) {
handles.emplace_back(new char[numBytes]{}); //array of Bytes
std::cout << "Allocated "
<< numBytes << " Bytes" << std::endl;
}
//randomize the memory deallocations
std::shuffle(handles.begin(), handles.end(), randEng);
for(const auto& elem : handles) {
delete [] elem;
}
}
If you do copy/paste/change the code, please let me know what you did and what you discovered in the process.
Note3: I have an intense love/hate relationship with the C++ posts that I write. I love them because they attract the most traffic into this gawd-forsaken site and I always learn something new about the language when I compose them. I hate my C++ posts because they take for-freakin’-ever to write. The number of create/reflect/correct iterations I execute for a C++ post prior to queuing it up for publication always dwarfs the number of mental iterations I perform for a non-C++ post.
The Annihilation Of Conceptual Integrity
When a large group or committee is tasked with designing a complex system from scratch, or evolving an existing one, I always think of these timeless quotes from Fred Brooks:
“A design flows from a chief designer, supported by a design team, not partitioned among one.” – Fred Brooks
“The entire system also must have conceptual integrity, and that requires a system architect to design it all, from the top down.” – Fred Brooks
“Who advocates … for the product itself—its conceptual integrity, its efficiency, its economy, its robustness? Often, no one.” – Fred Brooks
“A little retrospection shows that although many fine, useful software systems have been designed by committees and built as part of multi-part projects, those software systems that have excited passionate fans are those that are the products of one or a few designing minds, great designers.” – Fred Brooks
Note Fred’s correlation between “conceptual integrity” and the individual (or small group) for success.
C++ is a large, sprawling, complex, programming language. With the next language specification update due to be ratified by the ISO C++ committee in 2017, Bjarne Stroustrup (the original, one-man, creator and curator of C++) felt the need to publish a passionate plea admonishing the committee to “stop the insanity“: Thoughts About C++17.

By reminding the committee members of the essence of what uniquely distinguishes C++ from its peers, Bjarne is warning against the danger of annihilating the language’s conceptual integrity. The center must hold!
It seems to be a popular pastime to condemn C++ for being a filthy mess caused by rampant design-by-committee. This has been suggested repeatedly since before the committee was founded, but I feel it is now far worse. Adding a lot of unrelated features and library components will do much to add complexity to the language, making it scarier to both novices and “mainline programmers”. What I do not want to try to do:
• Turn C++ into a radically different language
• Turn parts of C++ into a much higher-level language by providing a segregated sub-language
• Have C++ compete with every other language by adding as many as possible of their features
• Incrementally modify C++ to support a whole new “paradigm”
• Hamper C++’s use for the most demanding systems programming tasks
• Increase the complexity of C++ use for the 99% for the benefit of the 1% (us and our best friends).
Like all the other C++ committee members, Bjarne is a really, really, smart guy. For the decades that I’ve followed his efforts to evolve and improve the language, Bjarne has always expressed empathy for “the little people“; the 99% (of which I am a card-carrying member).
In a world in which the top 1% doesn’t seem to give a shit about the remaining 99%, it’s always refreshing to encounter a 1 percenter who cares deeply about the other 99 percenters. And THAT, my dear reader, is what has always endeared Mr. Bjarne Stroustrup to me.
I am often asked – often by influential and/or famous people – if I am planning a D&E2 (The Design And Evolution Of C++ version 2). I’m not, I’m too busy using and improving C++. However, should I ever find it convenient to semi-retire, D&E2 would be a great project. However, I could do that if and only if I could honestly write it without condemning the language or my friends. We need to ship something we can be proud of and that we can articulate.
W00t! I didn’t know I was influential and/or famous: And In The Beginning.
Make Simple Tasks Simple
In the slide deck that Bjarne Stroustrup presented for his “Make Simple Tasks Simple” CppCon keynote speech, he walked through a progression of refactorings that reduced an (arguably) difficult-to-read, multi-line, C++98 code segment (that searches a container for an element matching a specific pattern) into an expressive, C++11 one liner:
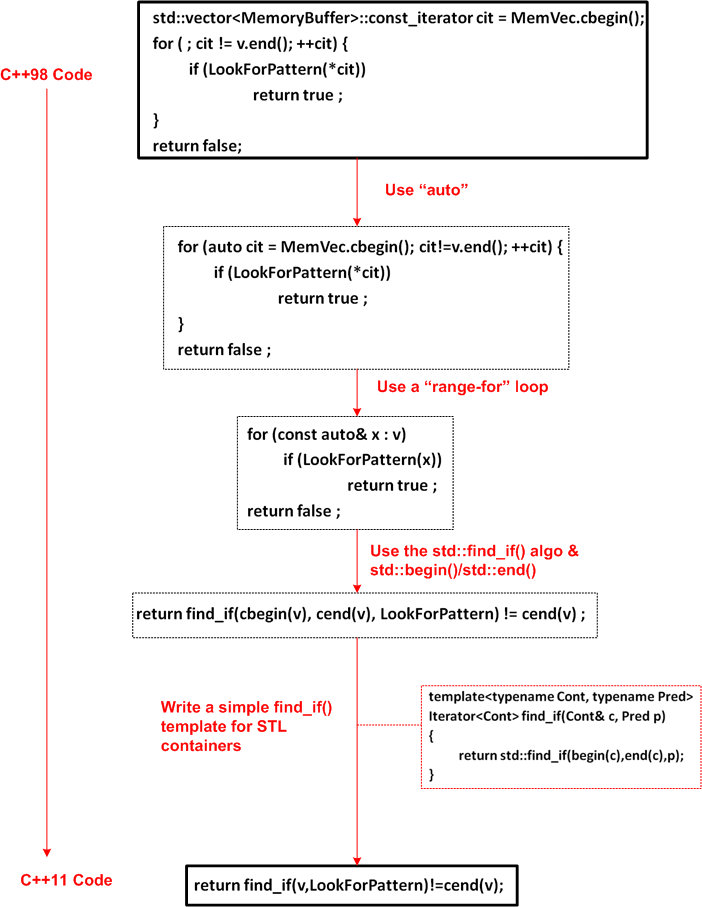
Some people may think the time spent refactoring the original code was a pre-mature optimization and, thus, a waste of time. But that wasn’t the point. The intent of the example was to illustrate several features of C++11 that were specifically added to the language to allow sufficiently proficient programmers to “make simple tasks simple (to program)“.
Note: After the fact, I discovered that “MemVec” should be replaced everywhere with “v” (or vice versa), but I was too lazy to fix the pic :). Can you find any other bugs in the code?
A Fascinating Conversation
“A Conversation with Bjarne Stroustrup, Carl Hewitt, and Dave Ungar” is the most fascinating technical video I’ve seen in years. The primary focus of the discussion was how to write applications that efficiently leverage multicore processors. Because of the diversity of views, the video is so engrossing that I watched it three times. I also downloaded the MP3 podcast of the discussion and saved it to a USB stick for the drive to/from work.
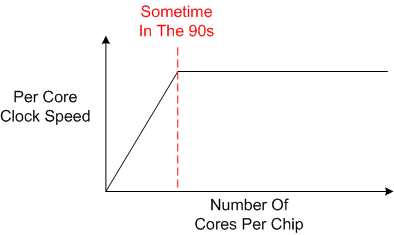
When pure physics started limiting the enormous CPU clock speed gains being achieved in the 90s, vertical scaling came to an abrupt halt and horizontal scaling kicked into gear. The number of cores per processor started going up, and it still is today.
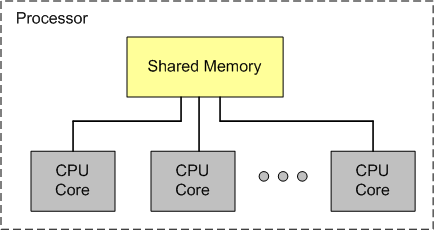
There was much discussion over the difference between a “lock” and “synchronization“. As the figure below illustrates, main memory is physically shared between the cores in a multicore processor. Thus, even if your programming language shields this fact from you by supporting high level, task-based, message passing instead of low-level cooperative threading with locks, some physical form of under-the-hood memory synchronization must be performed in order for the cores to communicate with each other through shared memory without data races.
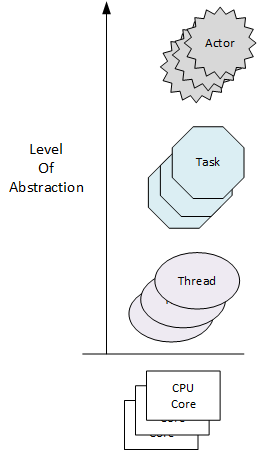
Here is my layman’s take on each participant’s view of the solution to the multicore efficiency issue:
- Hewitt: We need new, revolutionary, actor-based programming languages that abandon the traditional, sequential Von Neumann model. The current crop of languages just don’t cut it as the number of cores per processor keeps steadily increasing.
- Ungar: We need incoherent, unsynchronized hardware memory architectures with background cache error correction. Build a reliable system out of unreliable parts.
- Stroustrup: Revolutions happen much less than people seem to think. We need to build up and experiment with efficient concurrency abstractions in layered libraries that increasingly hide locks and core-to-memory synchronization details from programmers (the C++ threads-to-tasks-to-“next?” approach).
Not Just Expert Friendly
Check out this snippet from one of Bjarne Stroustrup’s CppCon keynote slides:

Now take a glance at one of Herb Sutter’s CppCon talk slides:

Bjarne’s talk was titled “Make Simple Tasks Simple” and Herb’s talk was tiled “Back To The Basics!: Modern C++ Style“. Since I abhor unessential complexity, I absolutely love the fact that these two dedicated gentlemen are spearheading the effort to evolve C++ in two directions simultaneously: increasing both expert-friendliness AND novice-friendliness.
By counterbalancing the introduction of advanced features like variadic templates and forwarding references with simpler features like range-for loops, nullptr, and brace-initialization, I think Bjarne and Herb (and perhaps other community members I don’t know about) are marvelously succeeding at the monumental task of herding cats. To understand what I mean, take a look at another one of Herb’s slides:
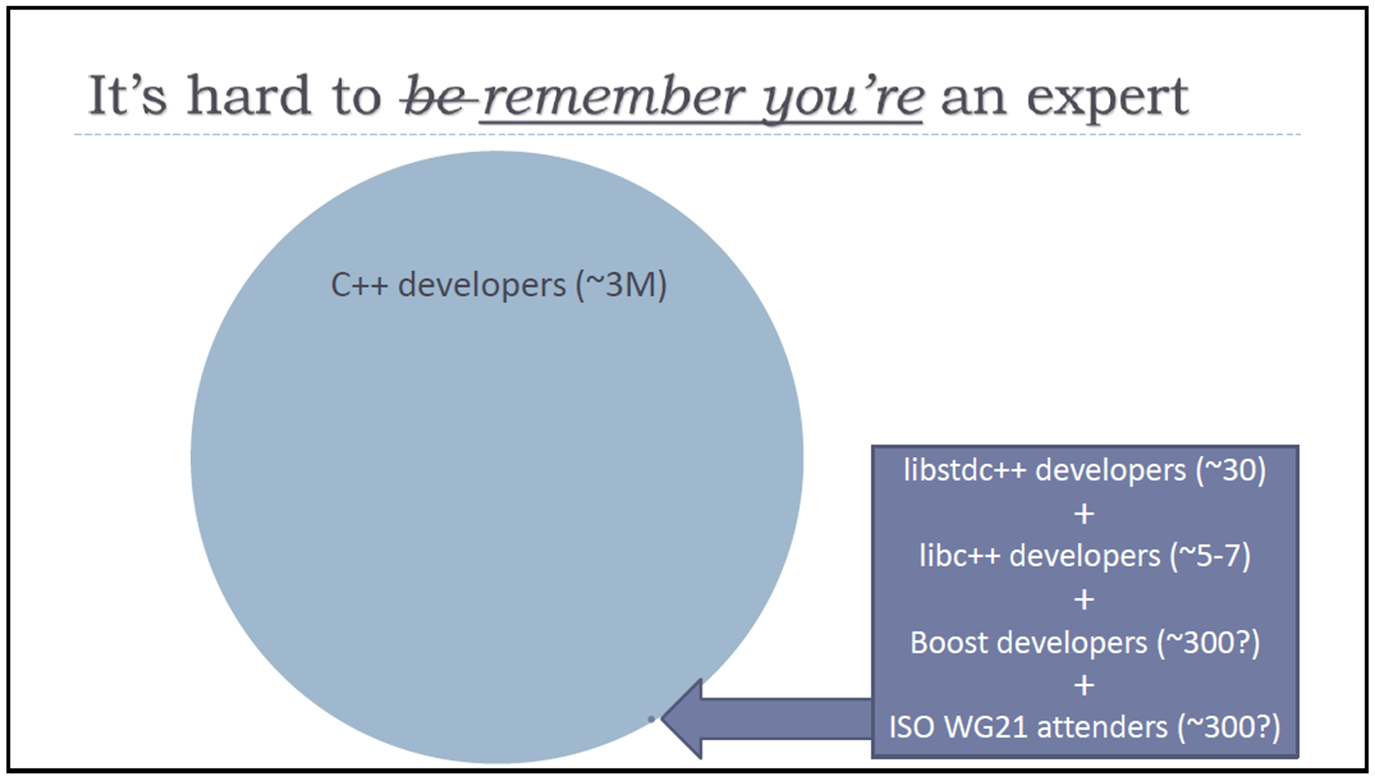
Do you see that teeny tiny dot at the end of the big arrow down on the lower right edge of the circle? Well, I don’t come anywhere close to qualifying for membership with the cats inside that dot… and I’d speculate that most advanced feature proposals and idiom ideas, whether they are understandable/teachable to mere mortals or not, originate from the really smart cats within that dot.

By gently but doggedly communicating the need for lowering the barriers to entry for potentially new C++ users while still navigating the language forward into unchartered waters, I’m grateful to Herb and Bjarne. Because of these men, the ISO C++ committee actually works – and it is indeed amazing for any committee to “work“.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

