Archive
Dude, Let’s Swarm!
Whoo hoo! I just got back from a 3 day, $2,000 training course in “swarm programming.” After struggling to make it though the unforgiving syllabus, I earned my wings along with the unalienable right to practice in this new and exciting way of creating software. Hyper-productive Scrum teams are so yesterday. Turbo-charged swarm teams are the wave of the future!

I found it strangely interesting that not one of my 30 (30 X $2K = 60K) classmates failed the course. But hey, we’re now ready and willing to swarm our way to success. There’s no stoppin’ us.

Easier To Use, And More Expressive
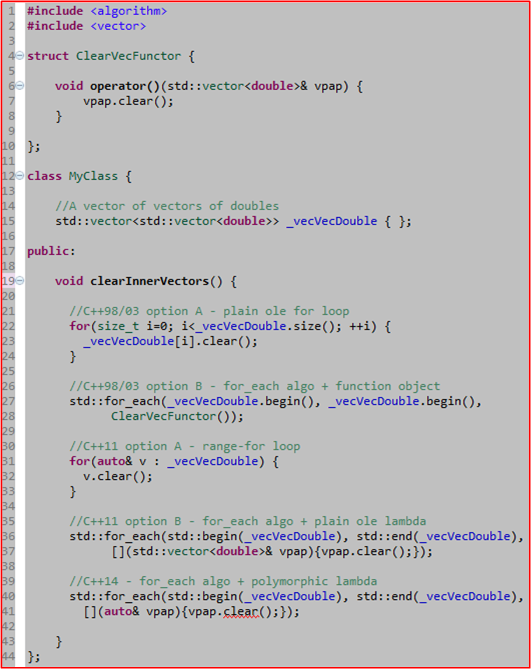
One of the goals for each evolutionary increment in C++ is to decrease the probability of an average programmer from making mistakes by supplanting “old style” features/idioms with new, easier to use, and more expressive alternatives. The following code sample attempts to show an example of this evolution from C++98/03 to C++11 to C++14.

In C++98/03, there were two ways of clearing out the set of inner vectors in the vector-of-vectors-of-doubles data structure encapsulated by MyClass. One could use a plain ole for-loop or the std::for_each() STL algorithm coupled with a remotely defined function object (ClearVecFunctor). I suspect that with the exception of clever language lawyers, blue collar programmers (like me) used the simple for-loop option because of its reduced verbosity and compactness of expression.
With the arrival of C++11 on the scene, two more options became available to programmers: the range-for loop, and the std::for_each() algorithm combined with an inline-defined lambda function. The range-for loop eliminated the chance of “off-by-one” errors and the lambda function eliminated the inconvenience of having to write a remotely located functor class.
The ratification of the C++14 standard brought yet another convenient option to the table: the polymorphic lambda. By using auto in the lambda argument list, the programmer is relieved of the obligation to explicitly write out the full type name of the argument.
This example is just one of many evolutionary improvements incorporated into the language. Hopefully, C++17 will introduce many more.
Note: The code compiles with no warnings under gcc 4.9.2. However, as you can see in the image from the bug placed on line 41, the Eclipse CDT indexer has not caught up yet with the C++14 specification. Because auto is used in place of the explicit type name in the lambda argument list, the indexer cannot resolve the std::vector::clear() member function.
8/26/15 Update – As a result of reader code reviews provided in the comments section of this post, I’ve updated the code as follows:
8/29/15 Update – A Fix to the Line 27 begin-begin bug:

Is It Safe?
Remember this classic torture scene in “Marathon Man“? D’oh!  Now, suppose you had to create the representation of a message that simply aggregates several numerical measures into one data structure:
Now, suppose you had to create the representation of a message that simply aggregates several numerical measures into one data structure:

Given no information other than the fact that some numerical computations must be performed on each individual target track attribute within your code, which implementation would you choose for your internal processing? The binary, type-safe, candidate, or the text, type-unsafe, option? If you chose the type-unsafe option, then you’d impose a performance penalty on your code every time you needed to perform a computation on your tracks. You’d have to deserialize and extract the individual track attribute(s) before implementing the computations:

If your application is required to send/receive track messages over a “wire” between processing nodes, then you’d need to choose some sort of serialization/deserialization protocol along with an over-the-wire message format. Even if you were to choose a text format (JSON, XML) for the wire, be sure to deserialize the input as soon as possible and serialize on output as late as possible. Otherwise you’ll impose an unnecessary performance hit on your code every time you have to numerically manipulate the fields in your message.

More generally….

The Big Ones
Damn, these are the kinds of bugs I keep finding in my code!

Perhaps it’s time to find a new vocation?
Note: Thanks to @RiczWest for pointing this out to me.
PeriodicFunction
In the embedded systems application domain, there is often the need to execute one or more background functions at a periodic rate. Before C++11 rolled onto the scene, a programmer had to use a third party library like ACE/Boost/Poco/Qt to incorporate that functionality into the product. However, with the inclusion of std::thread, std::bind, and std::chrono in C++11, there is no longer the need to include those well-crafted libraries into the code base to achieve that specific functionality.
The following figure shows the interface of a class template that I wrote to provide users with the capability to execute a function object (of type std::function<void()>) at a periodic rate over a fixed length of time.
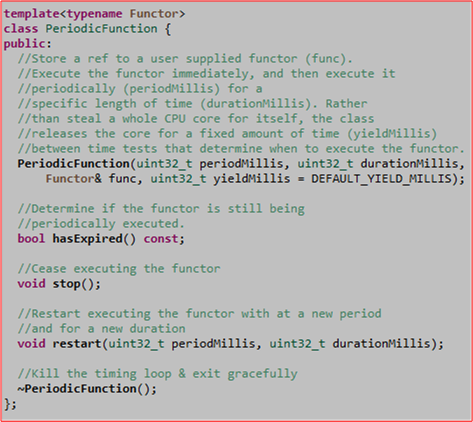
Upon instantiation of a PeriodicFunction object, the class executes the Functor immediately and then re-executes it every periodMillis until expiration at durationMillis. The hasExpired(), stop(), and restart() functions provide users with convenient query/control options after construction.
The figure below depicts the usage of the PeriodicFunction class. In the top block of code, a lambda function is created and placed into execution every 200 milliseconds over a 1 second duration. After waiting for those 5 executions to complete, the code restarts the PeriodicFunction to run the lambda every 500 milliseconds for 1.5 seconds. The last code segment defines a Functor class, creates an object instance of it, and places the functor into execution at 50 millisecond intervals over a duration of 250 milliseconds.

The output of a single run of the program is shown below. Note that the actual output matches what is expected: 5 executions spaced at 200 millisecond intervals; 3 executions spaced at 500millisecond intervals; and 5 executions spaced at 50 millisecond intervals.

In case you want to use, experiment with, or enhance the code, the implementation of the PeriodicFunction class template is provided in copy & paste form as follows:
#ifndef PERIODICFUNCTION_H_
#define PERIODICFUNCTION_H_
#include <cstdint>
#include <thread>
#include <mutex>
#include <chrono>
#include <atomic>
namespace pf {
using std::chrono::steady_clock;
using std::chrono::duration;
using std::chrono::milliseconds;
template<typename Functor>
class PeriodicFunction {
public:
//Initialize the timer state and start the timing loop
PeriodicFunction(uint32_t periodMillis, uint32_t durationMillis,
Functor& callback, int32_t yieldMillis = DEFAULT_YIELD_MILLIS) :
func_(callback),
periodMillis_(periodMillis),
expirationTime_(steady_clock::now()
+ steady_clock::duration(milliseconds(durationMillis))),
nextCallTimeMillis_(steady_clock::now()), yieldMillis_(yieldMillis) {
//Start the timing loop
t_ = std::thread { PeriodicFunction::threadLoop, this };
}
//Command & wait for the threadLoop to stop
//before this object gets de-constructed
~PeriodicFunction() {
stop();
}
bool hasExpired() const {
return hasExpired_;
}
void stop() {
isRunning_ = false;
if (t_.joinable())
t_.join();
}
void restart(uint32_t periodMillis, uint32_t durationMillis) {
std::lock_guard<std::mutex> lg(stateMutex_);
//Stop the current timer if needed
stop();
//What time is it right at this instant?
auto now = steady_clock::now();
//Set the state for the new timer
expirationTime_ = now + milliseconds(durationMillis);
nextCallTimeMillis_ = now;
periodMillis_ = periodMillis;
hasExpired_ = false;
//Start the timing loop
isRunning_ = true;
t_ = std::thread { PeriodicFunction::threadLoop, this };
}
//Since we retain a reference to a Functor object, prevent copying
//and moving
PeriodicFunction(const PeriodicFunction& rhs) = delete;
PeriodicFunction& operator=(const PeriodicFunction& rhs) = delete;
PeriodicFunction(PeriodicFunction&& rhs) = delete;
PeriodicFunction& operator=(PeriodicFunction&& rhs) = delete;
private:
//The function to be executed periodically until we're done
Functor& func_;
//The period at which the function is executed
uint32_t periodMillis_;
//The absolute time at which we declare "done done!"
steady_clock::time_point expirationTime_;
//The next scheduled function execution time
steady_clock::time_point nextCallTimeMillis_;
//The thread sleep duration; the larger the value,
//the more we decrease the periodic execution accuracy;
//allows other sibling threads threads to use the cpu
uint32_t yieldMillis_;
//The default sleep duration of each pass thru
//the timing loop
static constexpr uint32_t DEFAULT_YIELD_MILLIS { 10 };
//Indicates whether the timer has expired or not
std::atomic<bool> hasExpired_ { false };
//Indicates whether the monitoring loop is active
//probably doesn't need to be atomic, but good practice
std::atomic<bool> isRunning_ { true };
//Our precious thread resource!
std::thread t_ { };
//Protects the timer state from data races
//between our private thread and the caller's thread
std::mutex stateMutex_ { };
//The timing loop
void threadLoop() {
while (isRunning_) {
auto now = steady_clock::now();//What time is it right at this instant?
std::lock_guard<std::mutex> lg(stateMutex_);
if (now >= expirationTime_) { //Has the timer expired?
hasExpired_ = true;
return;
}
else if (now > nextCallTimeMillis_) {//Time to execute function?
nextCallTimeMillis_ = now + milliseconds(periodMillis_);
std::bind(&Functor::operator(), std::ref(func_))(); //Execute!
continue; //Skip the sleep
}
//Unselfish sharing; let other threads have the cpu for a bit
std::this_thread::sleep_for(milliseconds(yieldMillis_));
}
}
};
//End of the class definition
}//namespace pf
#endif /* PERIODICFUNCTION_H_ */
One potential improvement that comes to mind is the addition of the capability to periodically execute the user-supplied functor literally “forever” – and not cheating by setting durationMillis to 0xFFFFFFFF (which is not forever). Another improvement might be to support variadic template args (like the std::thread ctor does) to allow any function type to be placed into execution – not just those of type std::function<void()>.
In case you don’t want to type in the test driver code, here it is in copy & paste form:
#include <iostream>
#include <chrono>
#include "PeriodicFunction.h"
int main() {
//Create a lambda and plcae into execution
//every 200 millis over a duration of 1 second
using namespace std::chrono;
steady_clock::time_point startTime { steady_clock::now() };
steady_clock::time_point execTime { startTime };
auto lambda = [&] { //We don't need the ()
using namespace std::chrono;
execTime = steady_clock::now();
std::cout << "lambda executed at T="
<< duration_cast<milliseconds>(execTime - startTime).count()
<< std::endl;
startTime = execTime;
};
pf::PeriodicFunction<decltype(lambda)> pf1 { 200, 1000, lambda };
while (!pf1.hasExpired()) ;
std::cout << std::endl;
//Re-run the lambda every half second for a second
startTime = steady_clock::now();
execTime = startTime;
pf1.restart(500, 1500);
while (!pf1.hasExpired()) ;
std::cout << std::endl;
//Define a stateful Functor class
class Functor {
public:
Functor() :
startTime_ { steady_clock::now() }, execTime_ { startTime_ } {
}
void operator()() {
execTime_ = steady_clock::now();
std::cout << "Functor::operator() executed at T="
<< duration_cast<milliseconds>(execTime_ - startTime_).count()
<< std::endl;
startTime_ = execTime_;
}
private:
steady_clock::time_point startTime_;
steady_clock::time_point execTime_;
};
//Create a Functor object and place into execution
//every 50 millis over a duration of 250 millis
Functor myFunction { };
pf::PeriodicFunction<Functor> pf2 { 50, 250, myFunction, 0 };
while (!pf2.hasExpired()) ;
}
Time To Get Moving!
Prior to C++11, for every user-defined type we wrote in C++03, all standards-conforming C++ compilers gave us:
- a “free” copy constructor
- a “free” copy assignment operator
- a “free” default constructor
- a “free” destructor
The caveat is that we only got them for free if we didn’t manually override the compiler and write them ourselves. And unless we defined reference or pointer members inside of our type, we didn’t have to manually write them.
Starting from C++11 on, we not only get those operations for free for our user-defined types, we also get these turbo-boosters:
- a “free” move constructor
- a “free” move assignment operator
In addition, all of the C++ standard library containers have been “move enabled“.
When I first learned how move semantics worked and why this new core language feature dramatically improved program performance over copying, I started wondering about user-defined types that wrapped move-enabled, standard library types. For example, check out this simple user-defined Msg structure that encapsulates a move-enabled std::vector.

Logic would dictate that since I get “move” operations from the compiler for free with the Msg type as written, if I manually “moved” a Msg object in some application code, the compiler would “move” the vDoubs member under the covers along with it – for free.
Until now, I didn’t test out that deduction because I heard my bruh Herb Sutter say in a video talk that deep moves came for free with user-defined types as long as each class member in the hierarchical composition is also move-enabled. However, in a more recent video, I saw an excellent C++ teacher explicitly write a move constructor for a class similar to the Msg struct above:
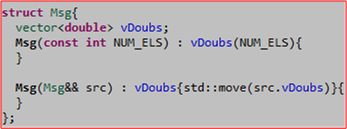
D’oh! So now I was confused – and determined to figure out was was going on. Here is the program that I wrote to not only verify that manually written “move” operations are not required for the Msg struct, but to also measure the performance difference between moving and copying:

First, the program built cleanly as expected because the compiler provided the free “move” operations for the Msg struct. Second, the following, 5-run, output results proved that the compiler did indeed perform the deep, under the covers, “move” that my man Herb promised it would do. If the deep move wasn’t executed, there would have been no noticeable difference in performance between the move and copy operations.
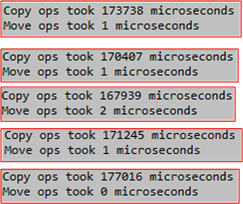
From the eye-popping performance difference shown in the results, we should conclude that it’s time to start replacing copy operations in our code with “move” operations wherever it makes sense. The only thing to watch out for when moving objects from one place to another is that in the scope of the code that performs the move, the internal state of the moved-from object is not needed or used by the code following the move. The following code snippet, which prints out 0, highlights this behavior.

Holier Than Thou
Since C++ (by deliberate design) does not include a native garbage collector or memory compactor, programs that perform dynamic memory allocation and de-allocation (via explicit or implicit use of the “new” and “delete” operators) cause small “holes” to accumulate in the free store over time. I guess you can say that C++ is “holier than thou“. 😦  Mind you, drilling holes in the free store is not the same as leaking memory. A memory leak is a programming bug that needs to be squashed. A fragmented free store is a “feature“. His holiness can become an issue only for loooong running C++ programs and/or programs that run on hardware with small RAM footprints. For those types of niche systems, the best, and perhaps only, practical options available for preventing any holes from accumulating in your briefs are to eliminate all deletes from the code:
Mind you, drilling holes in the free store is not the same as leaking memory. A memory leak is a programming bug that needs to be squashed. A fragmented free store is a “feature“. His holiness can become an issue only for loooong running C++ programs and/or programs that run on hardware with small RAM footprints. For those types of niche systems, the best, and perhaps only, practical options available for preventing any holes from accumulating in your briefs are to eliminate all deletes from the code:
- Perform all of your dynamic memory allocations at once, during program initialization (global data – D’oh!), and only utilize the CPU stack during runtime for object creation/destruction.
- If your application inherently requires post-initialization dynamic memory usage, then use pre-allocated, fixed size, unfragmentable, pools and stacks to acquire/release data buffers during runtime.
If your system maps into the “holes can freakin’ kill someone” category and you don’t bake those precautions into your software design, then the C++ runtime may toss a big, bad-ass, std::bad_alloc exception into your punch bowl and crash your party if it can’t find a contiguous memory block big enough for your impending new request. For large software systems, refactoring the design to mitigate the risk of a fragmented free store after it’s been coded/tested falls squarely into the expensive and ominous “stuff that’s hard to change” camp. And by saying “stuff that’s hard to change“, I mean that it may be expensive, time consuming, and technically risky to reweave your basket (case). In an attempt to verify that the accumulation of free store holes will indeed crash a program, I wrote this hole-drilling simulator:  Each time through the while loop, the code randomly allocates and deallocates 1000 chunks of memory. Each chunk is comprised of a random number of bytes between 1 and 1MB. Thus, the absolute maximum amount of memory that can be allocated/deallocated during each pass through the loop is 1 GB – half of the 2 GB RAM configured on the linux virtual box I am currently running the code on. The hole-drilling simulator has been running for days – at least 5 straight. I’m patiently waiting for it to exit – and hopefully when it does so, it does so gracefully. Do you know how I can change the code to speed up the time to exit?
Each time through the while loop, the code randomly allocates and deallocates 1000 chunks of memory. Each chunk is comprised of a random number of bytes between 1 and 1MB. Thus, the absolute maximum amount of memory that can be allocated/deallocated during each pass through the loop is 1 GB – half of the 2 GB RAM configured on the linux virtual box I am currently running the code on. The hole-drilling simulator has been running for days – at least 5 straight. I’m patiently waiting for it to exit – and hopefully when it does so, it does so gracefully. Do you know how I can change the code to speed up the time to exit?
Note1: This post doesn’t hold a candle to Bjarne Stroustrup’s thorough explanation of the “holiness” topic in chapter 25 of “Programming: Principles and Practice Using C++, Second Edition“. If you’re a C++ programmer (beginner, intermediate, or advanced) and you haven’t read that book cover-to-cover, then… you should.
Note2: For those of you who would like to run/improve the hole-drilling simulator, here is the non-.png source code listing:
#include
#include
#include
#include
#include
int main() {
//create a functor for generating uniformly
//distributed, contiguous memory chunk sizes between 1 and
//MAX_CHUNK_SIZE bytes
constexpr int32_t MAX_CHUNK_SIZE{1000000};
std::default_random_engine randEng{};
std::uniform_int_distribution distribution{
1, MAX_CHUNK_SIZE};
//load up a vector of NUM_CHUNKS chunks;
//with each chunk randomly sized
//between 1 and MAX_CHUNK_SIZE long
constexpr int32_t NUM_CHUNKS{1000};
std::vector chunkSizes(NUM_CHUNKS); //no init braces!
for(auto& el : chunkSizes) {
el = distribution(randEng);
}
//declare the allocator/deallocator function
//before calling it.
void allocDealloc(std::vector& chunkSizes,
std::default_random_engine& randEng);
//loop until our free store is so "holy"
//that we must bow down to the lord and leave
//the premises!
bool tooManyHoles{};
while(!tooManyHoles) {
try {
allocDealloc(chunkSizes, randEng);
}
catch(const std::bad_alloc&) {
tooManyHoles = true;
}
}
std::cout << "The Free Store Is Too "
<< "Holy to Continue!!!"
<< std::endl;
}
//the function for randomly allocating/deallocating chunks of memory
void allocDealloc(std::vector& chunkSizes,
std::default_random_engine& randEng) {
//create a vector for storing the dynamic pointers
//to each allocated memory block
std::vector<char*> handles{};
//randomize the memory allocations and store each pointer
//returned from the runtime memory allocator
std::shuffle(chunkSizes.begin(), chunkSizes.end(), randEng);
for(const auto& numBytes : chunkSizes) {
handles.emplace_back(new char[numBytes]{}); //array of Bytes
std::cout << "Allocated "
<< numBytes << " Bytes" << std::endl;
}
//randomize the memory deallocations
std::shuffle(handles.begin(), handles.end(), randEng);
for(const auto& elem : handles) {
delete [] elem;
}
}
If you do copy/paste/change the code, please let me know what you did and what you discovered in the process.
Note3: I have an intense love/hate relationship with the C++ posts that I write. I love them because they attract the most traffic into this gawd-forsaken site and I always learn something new about the language when I compose them. I hate my C++ posts because they take for-freakin’-ever to write. The number of create/reflect/correct iterations I execute for a C++ post prior to queuing it up for publication always dwarfs the number of mental iterations I perform for a non-C++ post.
Nothing Is Unassailable
I recently posted a tidbit on Twitter which I thought was benignly unassailable:

Of course, Twitter being Twitter, I was wrong – and that’s one of the reasons why I love (and hate) Twitter. When your head gets too inflated, Twitter can deflate it as fast as a pin pops a balloon.

Yes, But You Will Know
In recounting his obsession with quality, I recall an interview where Steve Jobs was telling a reporter about painting a fence with his father when he was a young boy. There was a small section in a corner of the yard, behind a shed and fronted by bushes, that was difficult to lay a brush on. Steve asked his dad: “Do I really have to paint that section? Nobody will know that it’s not painted.” His father simply said: “Yes, but you will know.”
It is pretty much a de-facto standard in the C++ (and Java) world that enum type names start with a capital letter and that enumeration values are all capitalized, with underscores placed between multi-word names:

Now, assume you stumble across some sloppy work like this in code that must be formally shared between two different companies:

Irked by the obvious sloppiness, and remembering the Steve Jobs story, you submit the following change request to the formal configuration control board in charge of ensuring consistency, integrity, and quality of all the inter-company interfaces:

What would you do if your request was met with utter silence – no acknowledgement whatsoever? Pursue it further, or call it quits? Is silence on a small issue like this an indicator of a stinky cultural smell in the air, or is the ROI to effect the change simply not worth it? If the ROI to make the change is indeed negative, could that be an indicator of something awry with the change management process itself?
How hard, and how often, do you poke the beast until you choose to call it quits and move on? Seriously, you surely do poke the beast at least once in a while… err, don’t you?

2000 Lines A Day
I was at a meeting once where a peer boasted: “It’s hard to schedule and convene code reviews when you’re writing 2000 lines of code a day“. Before I could open my big fat mouth, a fellow colleague beat me to the punch: “Maybe you shouldn’t be writing 2000 lines of code per day“.
Unless they run a pure software company (e.g. Google, Microsoft, Facebook), executive management is most likely a fan of cranking out more and more lines of code per day. Because of this, and the fact that cranking out more lines of code than the next guy gives them a warm and fuzzy feeling, I suspect that many developers have a similar mindset as my boastful peer.
Unsurprisingly, the results of cranking out as much code per day as one can, can yield legacy code before it actually becomes legacy code:
- Huge classes and multi-page member functions with deeply nested “if” constructs inter-twined within multiple “for” loops.
- A seemingly random mix of public and private member objects.
- No comments.
- Inconsistent member and function naming.
- No unit tests.
- Loads of hard-coded magic numbers and strings.
- Tens of import statements.
Both I and you know this because because we’ve had to dive into freshly created cesspools with those “qualities” to add new functionality – even though “the code is only a tool” that isn’t a formal deliverable. In fact, we’ve most likely created some pre-legacy, legacy code cesspools ourselves.

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

