Archive
Front And Back
In response to my previous post, Glen Alleman pointed out that for large system development projects, the technical plan must be preceded by a higher level, coarser, activity. Glen is right.
Senior analysts and architects don’t just sit down and start designing the technical plan from scratch. They work with experienced, knowledgeable customers to develop, define, and document the capabilities that the system must satisfy in order to solve their problem. Thus, I’ve augmented my diagram to show this important activity:
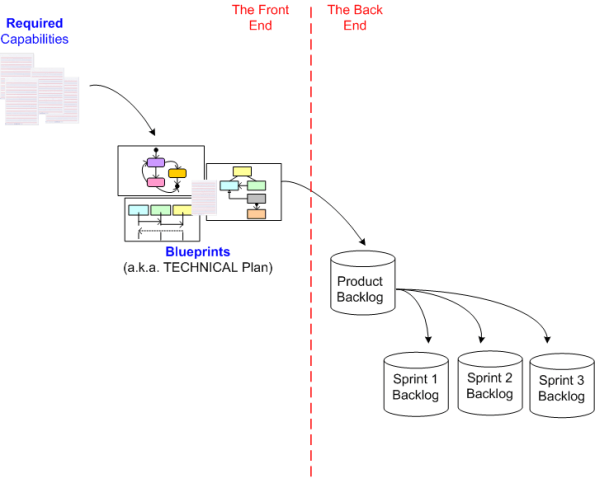
We’re not done yet. There is still (at least) one more front end activity missing from the diagram: the problem definition phase:
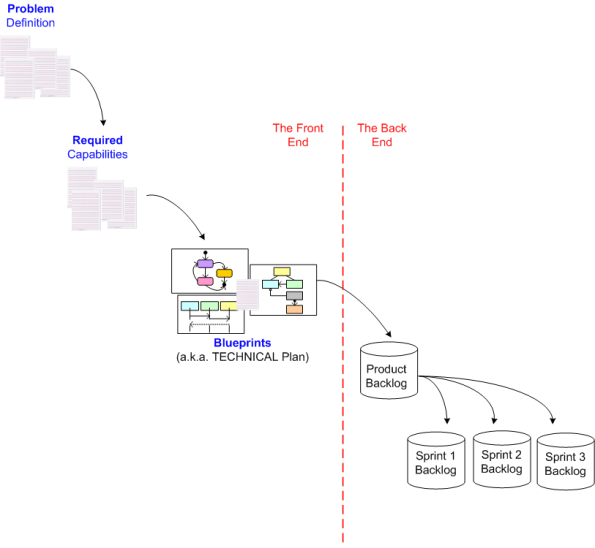
So, what precedes the problem definition phase? The pain of problem discovery….
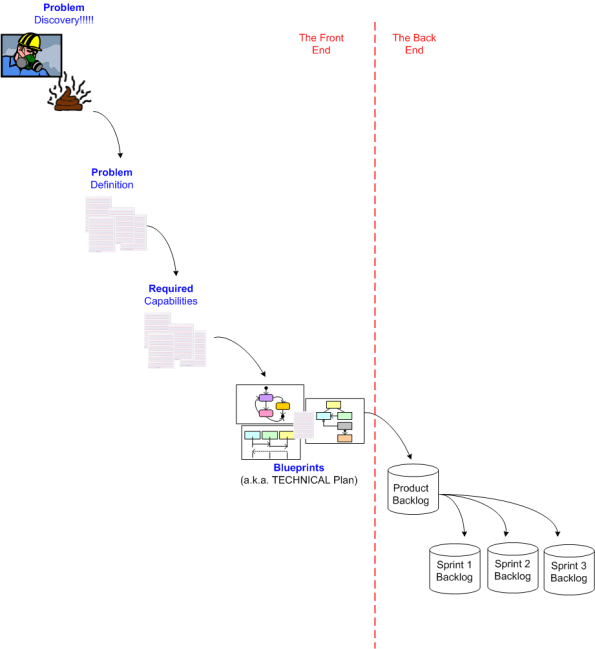
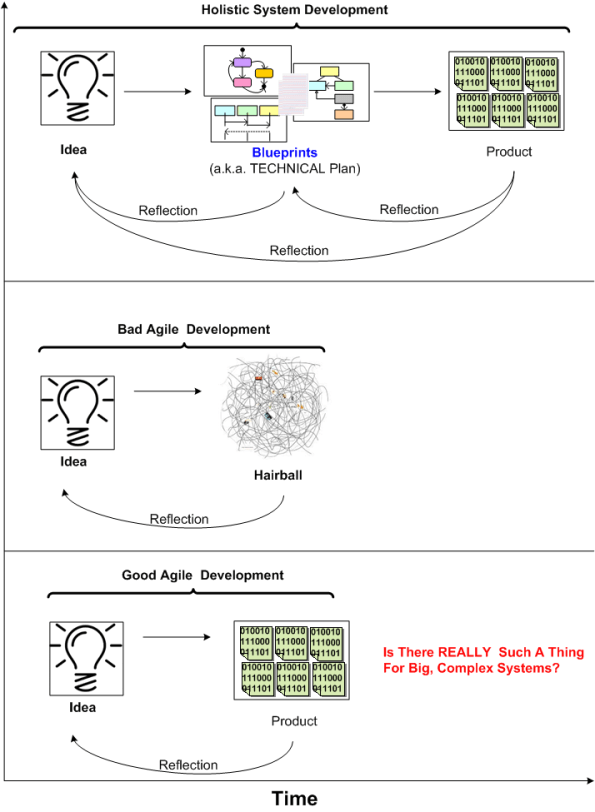
The Agile community does a great job of defining how the back end should be managed for cost-effective product development, but IMO they are mostly silent on the much-more-important, fuzzy, front end.
Is There REALLY Such A Thing?
Design, And THEN Development
First, we have product design:
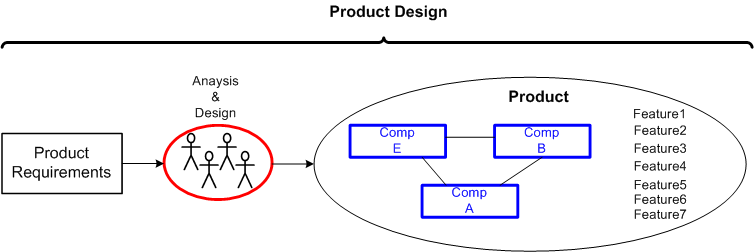
Second, we have product development:
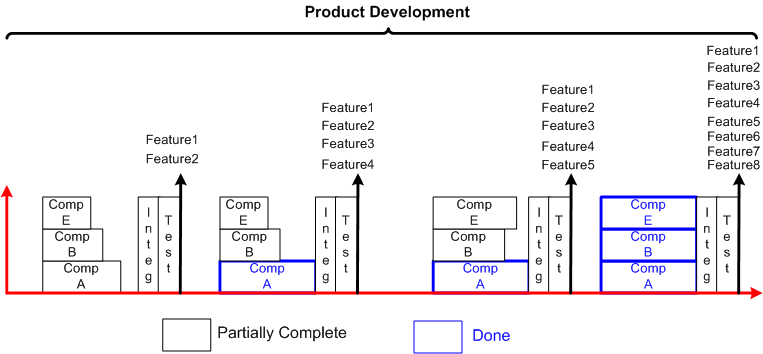
At scale, it’s consciously planned design first, and development second: design driven development. It’s not the other way around, development driven design.
The process must match the product, not the other way around. Given a defined process, whether it’s agile-derived or “traditional“, attempting to jam fit a product development effort into a “fits all” process is a recipe for failure. Err, maybe not?
Flat, Independent, Hierarchical, Inter-Dependent
Flat And Independent
Assume that company ABC develops products for customers in domain XYZ as follows:

To remove the “development process” variable from further consideration in this post (because, thanks to consultants, it seems like everybody and their brother thinks process (traditional, Scrum, XP, LeSS, SAFE, Lean, etc.) is the maker or breaker of success), assume that all the teams use the same development process.
As the figure implies, each product is tailor-made for each customer. Since there are no inter-team dependencies and there is no hierarchy in the organizational structure, each team is an island unto itself and fully responsible for its own success or failure.
The tradeoff for this team independence is that the cost of development for company ABC may be higher than alternative strategies due to the duplication of work inherent in this Flat And Independent (FAIN) approach. For example, the above figure shows that components A and B are developed from scratch 3 times and component 2 is developed twice. What a waste of resources, no? However, assuming that components A and B only need to be developed once and reused across the board requires that component A is identical for all customers and component C is identical for customers 2 and 3. However, even though the products are targeted for the same domain this may not be true. The amount of overlapping functionality for a given component is dependent on the amount of overlap between the customer requirements applicable to that component:

If there is zero requirements overlap, or the amount of overlap is so small that it’s too expensive to gauge, then financing three separate component development efforts is more economically viable and schedule-friendly than trying to ferret out all overlaps and embracing the alternative, Hierarchical And Inter-Dependent (HAID) strategy…..
Hierarchical And Inter-Dependent
Now, assume that company DEF also develops products for customers in domain XYZ, but the org employs the HAID strategy as follows:

In this specific instantiation of the HAID (aka product line) approach:
- Core asset component B is developed once and reused three times
- Core asset components A and C are developed once and reused twice
Beside the obvious downside of core asset components D, E, and F being developed but not reused at all (violating YAGNI in this specific case when it actually applies), there is a less obvious but insidious inefficiency in the two layer hierarchical structure: the product teams are dependent on, and thus, at the mercy of the core assets team. The cost and schedule inefficiencies introduced by this hierarchical dependency can make the HAID approach less economically viable than the traditional, seemingly wasteful, FAIN approach. But wait! It’s worse than that. If you’ve been immersed in the HAID way of life for too long, like a fish in water that has no concept of what the hell water is, you may not even know that you’d be better off if you initially chose, or currently revert to, the FAIN strategy.

Inappropriate application of, or poor execution of, the HAID approach to product development reminds me of the classic framework dilemma in software development. You know the feeling. It’s when you break out into a cold sweat after you choose a development framework (or development process!) and you suddenly realize that you’ve handcuffed yourself into submission after it’s too late to reverse the decision. D’oh!
I guess the moral of this story is nothing new: “just because you changed strategies to become more effective doesn’t make it so.” Well, maybe there is no moral, but I had to end this post some-freakin’-how.
Both Inane And Insane
Let’s start this post off by setting some context. What I’m about to spout concerns the development of large, complex, software systems – not mobile apps or personal web sites. So, let’s rock!
The UML class diagram below depicts a taxonomy of methods for representing and communicating system requirements.
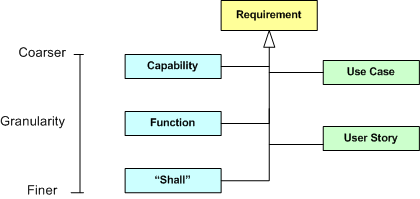
On the left side of the diagram, we have the traditional methods: expressing requirements as system capabilities/functions/”shalls”. On the right side of the diagram, we have the relatively newer artifacts: use cases and user stories.
When recording requirements for a system you’re going to attempt to build, you can choose a combination of methods as you (or your process police) see fit. In the agile world, the preferred method (as evidenced by 100% of the literature) is to exclusively employ fine-grained user stories – classifying all the other, more abstract, overarching, methods as YAGNI or BRUF.
As the following enhanced diagram shows, whichever method you choose to predominantly start recording and communicating requirements to yourself and others, at least some of the artifacts will be inter-coupled. For example, if you choose to start specifying your system as a set of logically cohesive capabilities, then those capabilities will be coupled to some extent – regardless of whether you consciously try to discover and expose those dependencies or not. After all, an operational system is a collection of interacting parts – not a bag of independent parts.
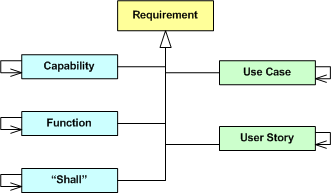
Let’s further enhance our class diagram to progressively connect the levels of granularity as follows:
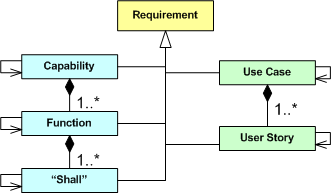
If you start specifying your system as a set of coarse-grained, interacting capabilities, it may be difficult to translate those capabilities directly into code components, packages, and/or classes. Thus, you may want to close the requirements-to-code intellectual gap by thoughtfully decomposing each capability into a set of logically cohesive, but loosely coupled, functions. If that doesn’t bridge the gap to your liking, then you may choose to decompose each function further into a finer set of logically cohesive, but loosely coupled, “shall” statements. The tradeoff is time upfront for time out back:
- Capabilities -> Source Code
- Use Cases – > Source Code
- Capabilities -> Functions -> Source Code
- Use Case -> User Story -> Source Code
- Capabilities -> Functions -> “Shalls” -> Source Code
Note that, taken literally, the last bullet implies that you don’t start writing ANY code until you’ve completed the full, two step, capabilities-to-“shalls” decomposition. Well, that’s a croc o’ crap. You can, and should, start writing code as soon as you understand a capability and/or function well enough so that you can confidently cut at least some skeletal code. Any process that prohibits writing a single line of code until all the i’s are dotted and all the t’s are crossed and five “approval” signatures are secured is, as everyone (not just the agile community) knows, both inane and insane.

Of course, simple projects don’t need no stinkin’ multi-step progression toward source code. They can bypass the Capability, Function, and Use Case levels of abstraction entirely and employ only fine grained “shalls” or User Stories as the method of specification.

On the simplest of projects, you can even go directly from thoughts in your head to code:

The purpose of this post is to assert that there is no one and only “right” path in moving from requirements to code. The “heaviness” of the path you decide to take should match the size, criticality, and complexity of the system you’ll be building. The more the mismatch, the more the waste of time and effort.
A Blast From The Past
One of the first from-scratch products I ever worked on was named “BEXR” (Beacon Extractor & Recorder, pronounced “Beck’s-uhr“). I proposed the name BEVR (Beacon Evaluation & Video Recorder, pronounced “beaver“), but it was shot down by the marketing department immediately for who knows why 🙂
BEXR was a custom hardware and software combo that connected to the raw, low-level, return signals received by FAA secondary surveillance radars from aircraft-based transponders. The product allowed FAA maintenance personnel to observe and evaluate the quality of radar and transponder signals in real-time – much like a specialized oscilloscope. In addition, it supported recording and playback capabilities for off-site analysis.
Despite it’s utility to the FAA, BEXR was politically controversial. Since non-conforming aircraft transponders were relatively expensive to fix and reinstall, owners of small aircraft did not like being “spied upon“. They did not want to know if their equipment was out-of-spec. Thus, BEXR’s mission was limited to troubleshooting only radar issues.
BEXR was comprised of two, custom-designed, 16 bit, PC-AT bus cards. They were packaged in a portable PC that was carted to/from the radar site under investigation. I was the BEXR product manager and the GUI developer. I wrote the GUI Operator Control Software (OCS) in C using Microsoft’s Quick C IDE. The software directly used the Windows 3.1 C APIs to display application-specific windows, dialog boxes, target positions, and control buttons/lists. Compared to today’s GUI tools/API’s, it was the equivalent of writing assembler code for GUIs, but I had a lot of fun writing it. 🙂
The reason I decided to write this post is because I recently ran across a pack of sticky cards that we used to market the product and hand out at trade shows. It was a blast from the past….

Tradagile
Even though hard-core agilistas (since every cause requires an evil enemy) present it as thus:

For large, complex, multi-disciplined, product developments, it should be as thus:

The Goldilocks Dilemma
With increasing product complexity comes the necessity for technical specialization. For example, I help build multi-million dollar air defense and air traffic control radars that require the integration of:
- RF microwave antenna design skills,
- electro-mechanical design skills,
- physical materials design skills,
- analog RF/IF transmitter and receiver design skills,
- digital signal processing hardware design skills,
- secure internet design skills,
- mathematical radar waveform and tracker design skills,
- real-time embedded software design skills,
- web/GUI software design skills,
- database design skills.
Unless you’re incredibly lucky enough to be blessed with a team of Einsteins, it’s impractical, to the point of insanity, to expect people to become proficient across more than one (perhaps two is doable, but rare) of these deep, time-consuming-to-acquire, engineering skill sets.
As the figure below illustrates, one of the biggest challenges in complex product development is the Goldilocks dilemma: deciding how much specialism is “just right” for your product development team.
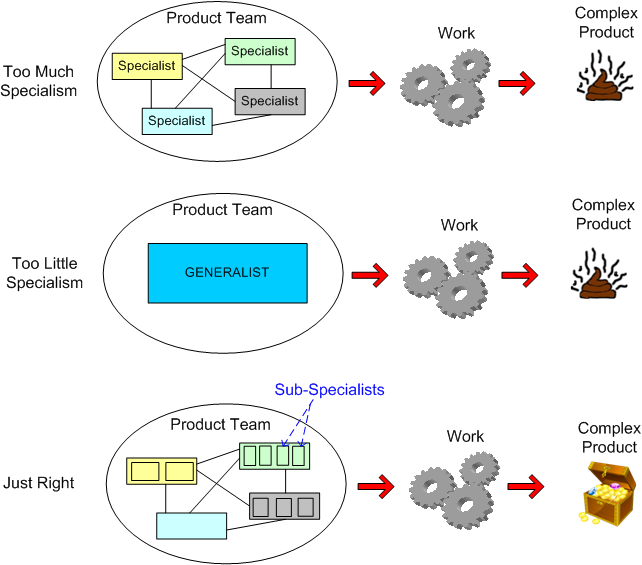
Too much specialism leads to an exponential increase in the number of inter-specialist communication links/languages to manage effectively. Too little specialism leads to the aforementioned “team of Einsteins” syndrome or, in the worst case, the “too many eggs in one basket” risk.
So, is there some magic, plug & play formula that you can crank through to determine the optimal level of specialism required in your product development team? I suspect not, but hey, if you develop one from first principles, lemme know and we’ll start a new consulting LLP to milk that puppy. Hell, even if you pull one out of your ass that people with lots o’ money will buy into, still gimme a call.
Abstract Decomposition And Concrete Composition
On the left we have the process of abstract decomposition, and on the right we have the process of concrete composition:
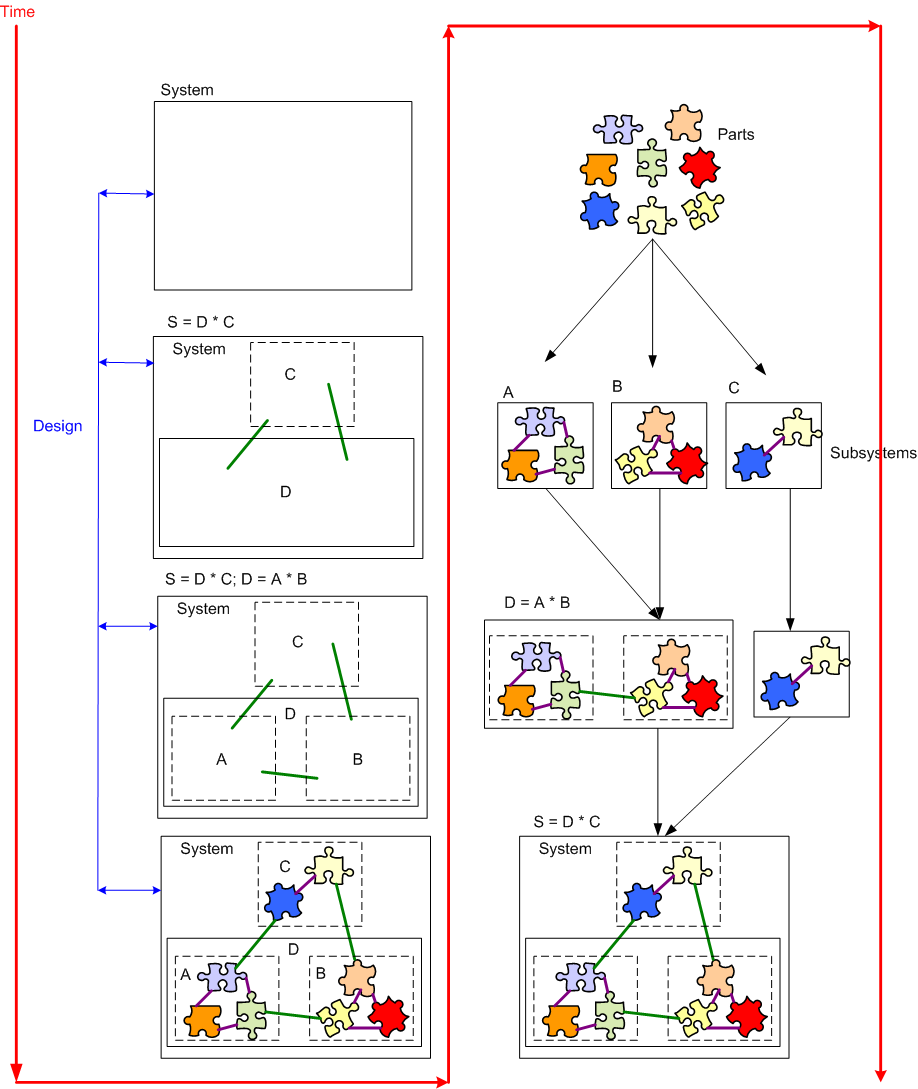
Note that during the concrete composition from parts to final system on the right, we gracefully transition through two stable, intermediate forms. Some people and communities, especially those obsessed with “velocity” and “time-to-market“, would say “bollocks” to all those value-subtracting, intermediate steps. We no need no stinking intermediate forms:
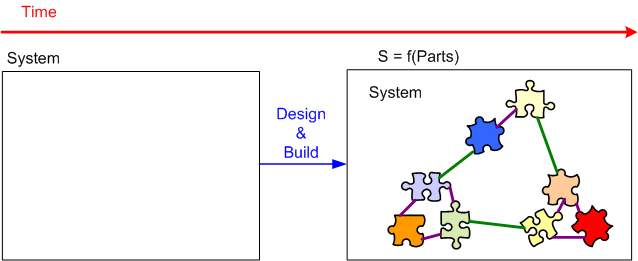
The Trees And The Forest
As a result of an online Twitter exchange with Mr. Jon Quigley, I was able to purchase a copy of his and Kim Pries’s book, “Project Management Of Complex And Embedded Systems“. In exchange for a half-price deal, I promised to blog a review of the book and, thus, this is it.

As indicated by the book title, the subject matter is all about the methods and tools commonly used by program/project managers for orchestrating large, capital-intensive, multi-disciplined, product development endeavors. Specifically, the content focuses on how the automotive industry successfully manages the development and production of products composed of thousands of electro-mechanical parts and hundreds of networked processors, some of which run safety-critical software. Even though we tend to take them for granted, when you think about it, an automobile is an extremely complex distributed system requiring lots of coordinated mental, physical, and automated, labor to produce.
The book provides comprehensive, yet introductory, coverage of the myriad of tools and processes used in the world of big project management. It’s more of a broad, sweeping, reference book than a detailed step-by-step prescription for executing a specific set of processes. It’s jam packed with lots of useful lists, figures, tables, and graphs. The end of each chapter even includes a specific “war story” experienced by one or both of the authors over their long careers.
As a long time software developer of complex embedded systems in the aerospace and defense industry, much of the book’s subject matter is familiar to me. RFPs, SOWs, WBSs, EVM, BOMs, V&V, SRRs, PDRs, CDRs, TRRs, FMEA, staged-gate phases, prime-subcontractor relationships, master schedules, multi-level approvals, quality metrics, docu-centric information exchanges, etc, are amongst the methods used to facilitate, focus, constrain, and guide end-to-end system development. Many of the chapter-ending war stories tickled my funny bone too!
For the types of projects Mssrs. Pries and Quigley target in the book, kicking off a project at sprint 0 with a self-organizing team of eight cross-functional developers and a primed product backlog of user stories just doesn’t cut it. So, if you’re a young, naive, cloistered software developer or scrum master or product owner who belittles all “traditional“, rigorous, non-agile processes, I highly recommend this book. It will give you a glimpse into a whole different world and broaden your horizons – perhaps allowing you to see both the trees and the forest.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

