Archive
Whence Actors?
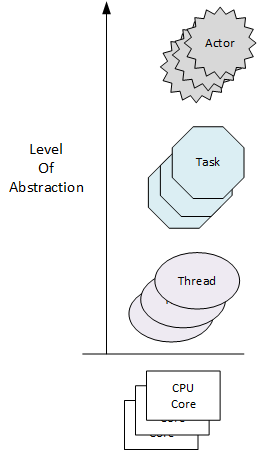
While sketching out the following drawing, I was thinking about the migration from sequential to concurrent programming driven by the rise of multicore machines. Can you find anything wrong with it?
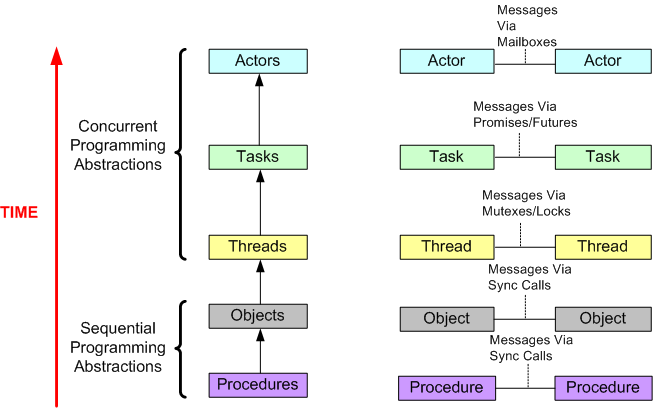
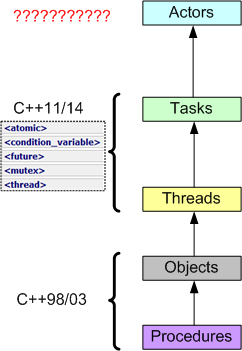
Right out of the box, C++ provided Objects (via classes) and procedures (via free standing functions). With C++11, standardized support for threads and tasks finally arrived to the language in library form. I can’t wait for Actors to appear in….. ?
A Fascinating Conversation
“A Conversation with Bjarne Stroustrup, Carl Hewitt, and Dave Ungar” is the most fascinating technical video I’ve seen in years. The primary focus of the discussion was how to write applications that efficiently leverage multicore processors. Because of the diversity of views, the video is so engrossing that I watched it three times. I also downloaded the MP3 podcast of the discussion and saved it to a USB stick for the drive to/from work.
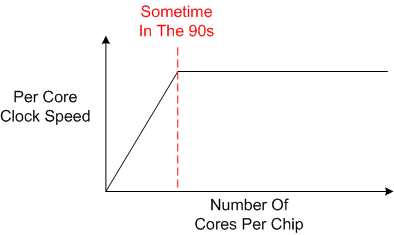
When pure physics started limiting the enormous CPU clock speed gains being achieved in the 90s, vertical scaling came to an abrupt halt and horizontal scaling kicked into gear. The number of cores per processor started going up, and it still is today.
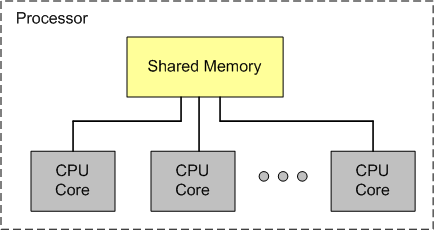
There was much discussion over the difference between a “lock” and “synchronization“. As the figure below illustrates, main memory is physically shared between the cores in a multicore processor. Thus, even if your programming language shields this fact from you by supporting high level, task-based, message passing instead of low-level cooperative threading with locks, some physical form of under-the-hood memory synchronization must be performed in order for the cores to communicate with each other through shared memory without data races.
Here is my layman’s take on each participant’s view of the solution to the multicore efficiency issue:
- Hewitt: We need new, revolutionary, actor-based programming languages that abandon the traditional, sequential Von Neumann model. The current crop of languages just don’t cut it as the number of cores per processor keeps steadily increasing.
- Ungar: We need incoherent, unsynchronized hardware memory architectures with background cache error correction. Build a reliable system out of unreliable parts.
- Stroustrup: Revolutions happen much less than people seem to think. We need to build up and experiment with efficient concurrency abstractions in layered libraries that increasingly hide locks and core-to-memory synchronization details from programmers (the C++ threads-to-tasks-to-“next?” approach).
Parallelism And Concurrency
In the beginning of Robert Virding’s brilliant InfoQ talk on Erlang, he distinguishes between parallelism and concurrency. Parallelism is “physical“, having to do with the static number of cores and processors in a system. Concurrency is “abstract“, having to do with the number of dynamic application processes and threads running in the system. To relate the physical with the abstract, I felt compelled to draw this physical-multi-core, physical-multi-node, abstract-multi-process, abstract-multi-thread diagram:
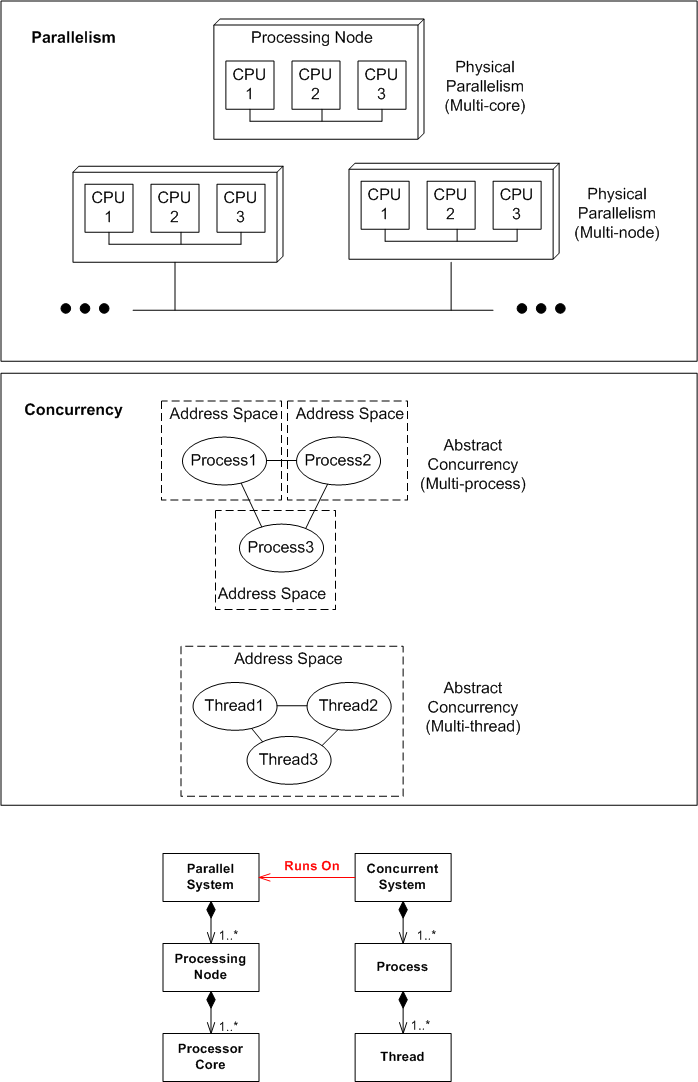
It’s not much different than the pic in this four year old post: PTCPN. It’s simply a less detailed, alternative point of view.
Beginner, Intermediate, Expert
Check out this insightful quote from Couchbase CTO Damien Katz:

Threads are hard because, despite being extremely careful, it’s ridiculously easy to code in hard to find, undeterministic, data races and/or deadlocks. That’s why I always model my multi-threaded programs (using the MML, of course) to some extent before I dive into code:

Note that even though I created and evolved (using paygo, of course) the above, one page “agile model” for a program I wrote, I still ended up with an infrequently occurring data race that took months, yes months, to freakin’ find. The culprit ended up being a data race on the (supposedly) thread-safe DB2 data structure accessed by the AT4, AT6, and AT7 threads. D’oh!
Two Plus Months
Race conditions are one of the worst plagues of concurrent code: They can cause disastrous effects all the way up to undefined behavior and random code execution, yet they’re hard to discover reliably during testing, hard to reproduce when they do occur, and the icing on the cake is that we have immature and inadequate race detection and prevention tool support available today. – Herb Sutter (DrDobbs.com)
With this opening paragraph in mind, observe the figure below. If you don’t lock-protect a stateful object that’s accessed by more than one thread, you’re guaranteed to fall into the dastardly trap that Herb describes. D’oh!

Now, look at the two object figure below. Unless you protect each of the two objects in the execution path with a lock, you’re hosed!

To improve performance at the expense of higher risk, you can use one lock for the two object example like on the left side of this graphic:

Alas, if you do choose to use one lock in a two object configuration like the example above, you better be sure that you don’t come in through the side with another thread to use the thread-unsafe object2. You also better be sure that a future maintainer of your code doesn’t do the same. But wait… How can you ensure that a maintainer won’t do that? You can’t. So stick with the more conservative, lower performance, one-lock-per-object approach.
Don’t ask me why I wrote this post cuz I ain’t answering. Well, Ok, ask. I wrote this post because I was burned by the left-hand side of the second graphic in this post. It took quite awhile, actually two plus months, to finally localize and squash the bugger in production code. As usual, Herb was right.
And please, don’t tell me that lock-free programming is the answer:
…replacing locks wholesale by writing your own lock-free code is not the answer. Lock-free code has two major drawbacks. First, it’s not broadly useful for solving typical problems—lots of basic data structures, even doubly linked lists, still have no known lock-free implementations. Second, it’s hard even for experts. It’s easy to write lock-free code that appears to work, but it’s very difficult to write lock-free code that is correct and performs well. Even good magazines and refereed journals have published a substantial amount of lock-free code that was actually broken in subtle ways and needed correction. – Herb Sutter (Dr. Dobbs).
Highly Available Systems == Scalable Systems
In this QCon talk: “Building Highly Available Systems In Erlang“, Erlang programming language creator and highly-entertaining speaker Joe Armstrong asserts that if you build a highly available software system, then scalability comes along for “free” with that system. Say what? At first, I wanted to ask Joe what he was smoking, but after reflecting on his assertion and his supporting evidence, I think he’s right.
In his inimitable presentation, Joe postulates that there are 6 properties of Highly Available (HA) systems:
- Isolation (of modules from each other – a module crash can’t crash other modules).
- Concurrency (need at least two computers in the system so that when one crashes, you can fix it while the redundant one keeps on truckin’).
- Failure Detection (in order to fix a failure at its point of origin, you gotta be able to detect it first)
- Fault Identification (need post-failure info that allows you to zero-in on the cause and fix it quickly)
- Live Code Upgrade (for zero downtime, need to be able to hot-swap in code for either evolution or bug fixes)
- Stable Storage (multiple copies of data; distribution to avoid a single point of failure)
By design, all 6 HA rules are directly supported within the Erlang language. No, not in external libraries/frameworks/toolkits, but in the language itself:
- Isolation: Erlang processes are isolated from each other by the VM (Virtual Machine); one process cannot damage another and processes have no shared memory (look, no locks mom!).
- Concurrency: All spawned Erlang processes run in parallel – either virtually on one CPU, or really, on multiple cores and processor nodes.
- Failure Detection: Erlang processes can tell the VM that it wants to detect failures in those processes it spawns. When a parent process spawns a child process, in one line of code it can “link” to the child and be auto-notified by the VM of a crash.
- Fault Identification: In Erlang (out of band) error signals containing error descriptors are propagated to linked parent processes during runtime.
- Live Code Upgrade: Erlang application code can be modified in real-time as it runs (no, it’s not magic!)
- Stable Storage: Erlang contains a highly configurable, comically named database called “mnesia” .
The punch line is that systems composed of entities that are isolated (property 1) and concurrently runnable (property 2) are automatically scalable. Agree?

Standard, Portable C++ Concurrency
Recently, I downloaded the Microsoft Visual Studio 11 IDE Beta in order to start experimenting with some C++11 features. Lo and behold, standard and portable concurrency is now supported:

At least on Windows, there’s no need to use the Win API, Boost.Thread or ACE or any other third party library in the future to write multi-core friendly, multi-threaded C++ apps. I don’t know when GCC and/or CLANG will ship with the standard C++11 concurrency libs. Do you?
By the way, a series of quick tests verified that lambdas, strictly typed enums, auto, nullptr, std::array, std::regex, and std::atomic work. Initializer lists, raw string literals, “using” as typedef, and range-based for loops don’t work yet.
Concurrency Support
Assuming that I remain a lowly, banana-eating programmer and I don’t catch the wanna-be-uh-manager-supervisor-director-executive fever, I’m excited about the new features and library additions provided in the C++11 standard.

Specifically, I’m thrilled by the support for “dangerous” multi-threaded programming that C++11 serves up.

For more info on the what, why, and how of these features and library additions, check out Scott Meyers’ pre-book training package, Anthony Williams’ new book, and Bjarne’s C++11 FAQ page.

Persistent Discomfort
As part of the infrastructure of the distributed, multi-process, multi-threaded system that my team is developing, a parameterized, mutex protected, inter-thread message queue class has been written and dropped into a general purpose library. To unburden application component developers from having to do it, the library-based queue class manages a reusable pool of message buffers that functionally “flow” from one thread to the next.

On the “push” side of the queue, usage is as follows:
- Thread acquires a handle to the next empty Message buffer
- Thread fills Message buffer
- Thread returns handle to the queue (push)
On the “pop” side of the queue, usage is as follows:
- Thread acquires a handle to the next full Message buffer (pop)
- Thread processes the Message content
- Thread returns handle to the queue
So far, so good, right? I thought so too – at the beginning of the project. But as I’ve moved forward during the development of my application component, I’ve been experiencing a growing and persistent discomfort. D’oh!
Using the figure below, I’m gonna share the cause of my “inner thread” discomfort with you.

In order to functionally process an input message and propagate it forward, the inner thread must do the following work:
- Acquire a handle to the next input Message buffer from queue 1 (pop)
- Acquire a handle to the next empty output Message buffer from queue 2
- Utilize the content of the Message from queue 1 to compute/fill in the Message to queue 2
- Return the handle of the input message to queue 1
- Return the handle of the output message to queue 2 (push)
For small messages and/or when the messages are of different types, I don’t see much wrong with this inter-thread message passing approach. However, when the messages are big and of the same type, my discomfort surfaces. In this case (as we shall see), the “utilize” bullet amounts to an unnecessary copy. The more “inner” threads there are in the pipeline, the more performance degradation there is from unnecessary copies.
So, how can the copies be eliminated and system performance increased? One way, as the figure below shows, is to move message buffer management responsibility out of the local queue class and into a global, shared message pool class.

In this memory-less queue design, the two pipeline end point threads explicitly assume the responsibility of acquiring and releasing the Message buffer handles from the mutex protected, shared message pool. The first thread “acquires” and the last thread “releases” message buffer handles. Each inner thread, i, in the pipeline performs the following work:
- Pop the handle to the next input Message buffer from queue i-1
- Process the message
- Push the Message buffer handle to queue i
The key to avoiding unessential inner thread copies is that the messages must be intentionally designed to be of the same type.
As soon as I get some schedule breathing room (which may be never), I’m gonna refactor my application infrastructure design and rewrite the code to implement the memoryless queue + global message pool approach. That is, unless someone points out a fatal flaw in my reasoning and/or presents a superior inter-thread message communication pattern.
The Parallel Patterns Library
Kate Gregory doesn’t work for Microsoft, but she’s a certified MVP for C++. In her talk at Tech Ed North America, “Modern Native C++ Development for Maximum Productivity”, she introduced the Parallel Patterns Library (PPL) and the concurrency runtime provided in Microsoft Visual C++ 2010.
The graphic below shows how a C++ developer interfaces with the concurrency runtime via the facilities provided in the PPL. Casting aside the fact that the stack only runs on Windows platforms, it’s the best of both worlds – parallelism and concurrency.

Note that although they are provided via the “synchronization types” facilities in the PPL, writing multi-threaded programs doesn’t require programmers to use error-prone locks. The messaging primitives (for inter-process communication) and concurrent collections (for intra-process communication) provide easy-to-use abstractions over sockets and locks programming. The messy, high-maintenance details are buried out of programmer sight inside the concurrency runtime.
I don’t develop for Microsoft platforms, but if I did, it would be cool to use the PPL. It would be nice if the PPL + runtime stack was platform independent. But the way Microsoft does business, I don’t think we’ll ever see linux or RTOS versions of the stack. Bummer.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

