Archive
Subtle And Quirky, But Still Lovable
I’m a long time C++ programmer who’s going to expose something embarrassing about myself. As a starting point, please take a look at the code below:

The first std::cout statement prints out the letter A and the second one prints out B. Here comes the embarrassing part… I erroneously thought that both the map::insert() and map::operator[] functions expressed the same semantics:
If the map object already contains an entry for the key being supplied by the user in the function call, the value supplied by the user will not be copied into the map.
Applied to the specific example above, before running the program I thought both std::cout statements would print the letter A.
Of course, as any experienced C++ programmer knows (or, in my case, should know), this behavior is only true for the map::insert() function. The map::operator[] function combined with the assignment operator will always copy the value into the map – regardless of whether or not an entry for the key is already present in the map. It makes sense that the two functions behave differently because sometimes you want an unconditional copy and sometimes you don’t.
The reason I wrote this post is because I very recently got burned by my incorrect assumption. To make a long story short, there was a bug in my large program that eventually was traced, with the help of the simple code example above, to the bad line of code that I wrote using map::operator[]. A simple change to map::insert() fixed the bug. It was critical to the application that an existing value in the map not be overwritten.
One of the dings against C++ is that it contains a lot of subtle, quirky semantics that are difficult for mere humans to remember. Despite agreeing with this, I still love the ole language that keeps on chugging forward like the little train that could (direct mapping to the hardware and zero overhead abstraction), despite the chagrin of many in the software industry:
I consider C++ the most significant technical hazard to the survival of your project and do so without apologies – Alistair Cockburn
Plugging Those Leaks
It’s been 5 years since modern C++ arrived on the scene in the form of the C++11 standard. Prior to the arrival, C++ was notorious for memory leaks and segmentation faults due to the lack of standardized smart pointers (although third party library and home grown smart pointers have existed for decades). Dangerous, naked news and deletes could be found sprinkled across large code bases everywhere – hidden bombs waiting to explode at any moment during runtime.
I don’t know how many over-confident C++ programmers are still using the old new/delete pattern in new code bases, but if your team is one of them please consider hoisting this terrific poster on the walls of your office:

ISO WG-21 C++ committee convener Herb Sutter, a tireless and passionate C++ advocate for decades, presented this poster in his CppCon 2016 talk “Leak Freedom In C++: By Default“. Go watch it now.
Move In, Move Out
In many application domains, the Producer-Queue-Consumer pattern is used to transport data from input to output within a multi-threaded program:
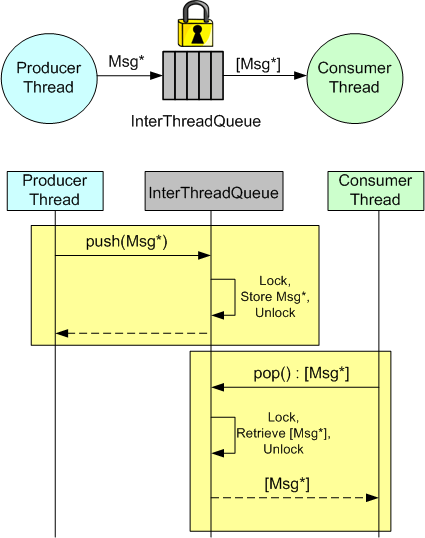
The ProducerThread creates Messages in accordance with the application’s requirements and pushes pointers to them into a lock-protected queue. The ConsumerThread, running asynchronous to the ProducerThread, pops sequences of Message pointers from the queue and processes them accordingly. The ConsumerThread may be notified by the ProducerThread when one or more Messages are available for processing or it can periodically poll the queue.
Instead of passing Message pointers, Message copies can be passed between the threads. However, copying the content can be expensive for large messages.
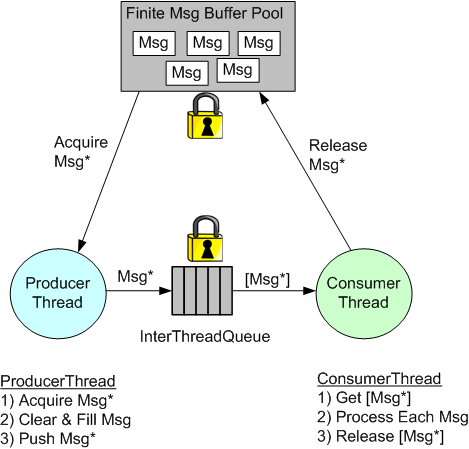
When using pointers to pass messages between threads, the memory to hold the data content must come from somewhere. One way to provide this memory is to use a Message buffer pool allocated on startup.
Another, simpler way that avoids the complexity of managing a Message buffer pool, is to manually “new” up the memory in the ProducerThread and then manually “delete” memory in the ConsumerThread.
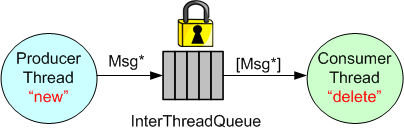
Since the introduction of smart pointers in C++11, a third way of communicating messages between threads is to “move” std::unique_ptrs into and out of the InterThreadQueue:

The advantage of using smart pointers is that no “deletes” need to be manually written in the ConsumerThread code.
The following code shows the implementation and usage of a simple InterThreadQueue that moves std::unique_ptrs into and out of a lock protected std::deque.
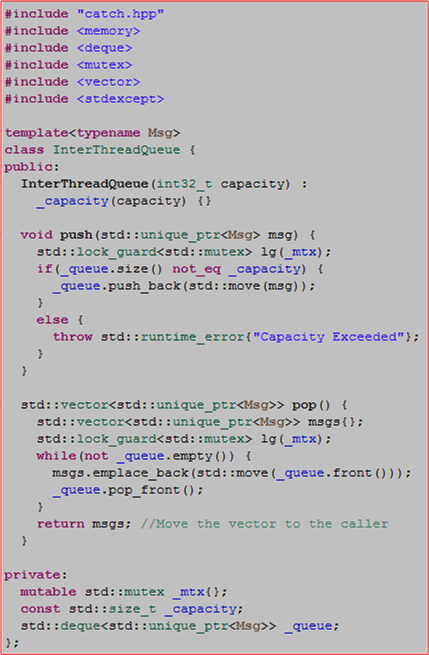

#include "catch.hpp"
#include <memory>
#include <deque>
#include <mutex>
#include <vector>
#include <stdexcept>
template<typename Msg>
class InterThreadQueue {
public:
InterThreadQueue(int32_t capacity) :
_capacity(capacity) {}
void push(std::unique_ptr<Msg> msg) {
std::lock_guard<std::mutex> lg(_mtx);
if(_queue.size() not_eq _capacity) {
_queue.push_back(std::move(msg));
}
else {
throw std::runtime_error{"Capacity Exceeded"};
}
}
std::vector<std::unique_ptr<Msg>> pop() {
std::vector<std::unique_ptr<Msg>> msgs{};
std::lock_guard<std::mutex> lg(_mtx);
while(not _queue.empty()) {
msgs.emplace_back(std::move(_queue.front()));
_queue.pop_front();
}
return msgs; //Move the vector to the caller
}
private:
mutable std::mutex _mtx{};
const std::size_t _capacity;
std::deque<std::unique_ptr<Msg>> _queue;
};
TEST_CASE( "InterThreadQueue" ) {
//Create our object under test
InterThreadQueue<int32_t> itq{2};
//Note: my compiler version doesn't have std::make_unique<T>()
std::unique_ptr<int32_t> dataIn{new int32_t{5}};
itq.push(std::move(dataIn));
dataIn = std::unique_ptr<int32_t>{new int32_t{10}};
itq.push(std::move(dataIn));
dataIn = std::unique_ptr<int32_t>{new int32_t{15}};
//Queue capacity is only 2
REQUIRE_THROWS(itq.push(std::move(dataIn)));
auto dataOut = itq.pop();
REQUIRE(2 == dataOut.size());
REQUIRE(5 == *dataOut[0]);
REQUIRE(10 == *dataOut[1]);
REQUIRE(0 == itq.pop().size());
}
M Of N Fault Detection
Let’s say that, for safety reasons, you need to monitor the voltage (or some other dynamically changing physical attribute) of a safety-critical piece of equipment and either shut it down automatically and/or notify someone in the event of a “fault“.
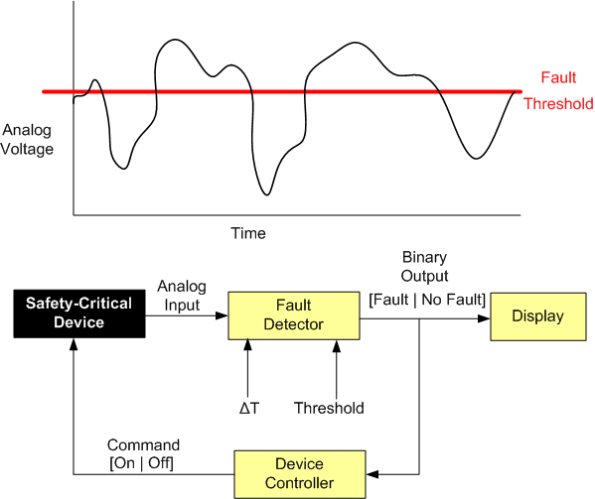
The figure below drills into the next level of detail of the Fault Detector. First, the analog input signal is digitized every ΔT seconds and then the samples are processed by an “M of N Detector”.
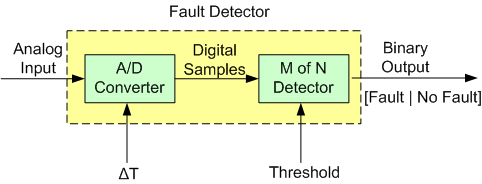
The logic implemented in the Detector is as follows:

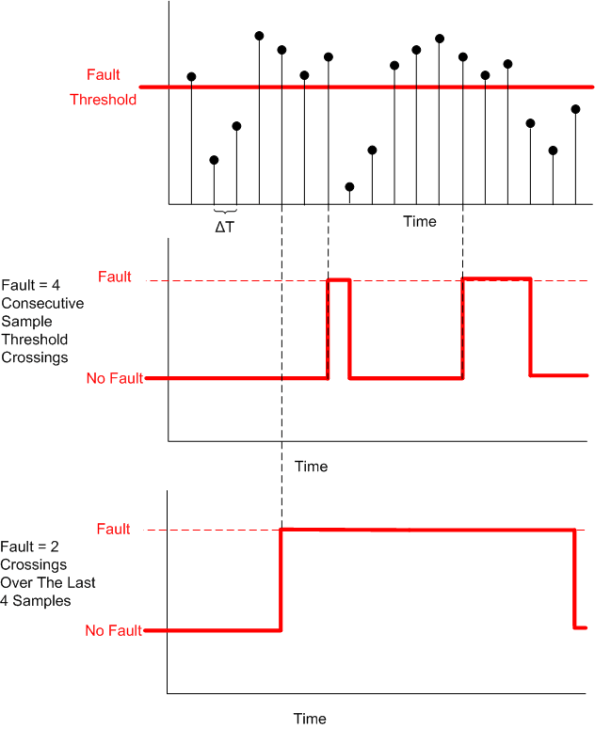
Instead of “crying wolf” and declaring a fault each time the threshold is crossed (M == N == 1), the detector, by providing the user with the ability to choose the values of M and N, provides the capability to smooth out spurious threshold crossings.
The next figure shows an example input sequence and the detector output for two configurations: (M == N == 4) and (M == 2, N == 4).
Finally, here’s a c++ implementation of an M of N Detector:
#ifndef MOFNDETECTOR_H_
#define MOFNDETECTOR_H_
#include <cstdint>
#include <deque>
class MofNDetector {
public:
MofNDetector(double threshold, int32_t M, int32_t N) :
_threshold(threshold), _M(M), _N(N) {
reset();
}
bool detectFault(double sample) {
if (sample > _threshold)
++_numCrossings;
//Add our newest sample to the history
if(sample > _threshold)
_lastNSamples.push_back(true);
else
_lastNSamples.push_back(false);
//Do we have enough history yet?
if(static_cast<int32_t>(_lastNSamples.size()) < _N) {
return false;
}
bool retVal{};
if(_numCrossings >= _M)
retVal = true;
//Get rid of the oldest sample
//to make room for the next one
if(_lastNSamples.front() == true)
--_numCrossings;
_lastNSamples.pop_front();
return retVal;
}
void reset() {
_lastNSamples.clear();
_numCrossings =0;
}
private:
int32_t _numCrossings;
double _threshold;
int32_t _M;
int32_t _N;
std::deque<bool> _lastNSamples{};
};
#endif /* MOFNDETECTOR_H_ */
Linear Interpolation In C++
In scientific programming and embedded sensor systems applications, linear interpolation is often used to estimate a value from a series of discrete data points. The problem is stated and the solution is given as follows:
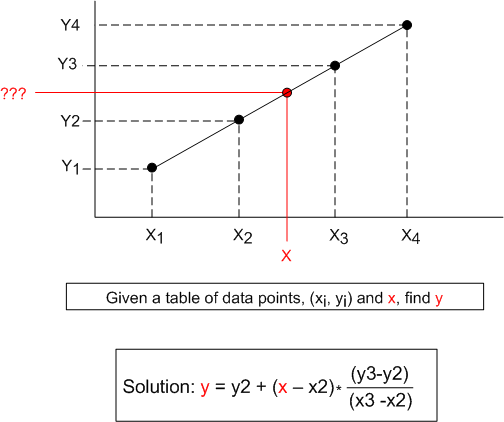
The solution assumes that any two points in a set of given data points represents a straight line. Hence, it takes the form of the classic textbook equation for a line, y = b + mx, where b is the y intercept and m is the slope of the line.
If the set of data points does not represent a linear underlying phenomenon, more sophisticated polynomial interpolation techniques that use additional data points around the point of interest can be utilized to get a more accurate estimate.
The code snippets below give the definition and implementation of a C++ functor class that performs linear interpolation. I chose to use a vector of pairs to represent the set of data points. What would’ve you used?
Interpolator.h
#ifndef INTERPOLATOR_H_
#define INTERPOLATOR_H_
#include <utility>
#include <vector>
class Interpolator {
public:
//On construction, we take in a vector of data point pairs
//that represent the line we will use to interpolate
Interpolator(const std::vector<std::pair<double, double>>& points);
//Computes the corresponding Y value
//for X using linear interpolation
double findValue(double x) const;
private:
//Our container of (x,y) data points
//std::pair::<double, double>.first = x value
//std::pair::<double, double>.second = y value
std::vector<std::pair<double, double>> _points;
};
#endif /* INTERPOLATOR_H_ */
Interpolator.cpp
#include "Interpolator.h"
#include <algorithm>
#include <stdexcept>
Interpolator::Interpolator(const std::vector<std::pair<double, double>>& points)
: _points(points) {
//Defensive programming. Assume the caller has not sorted the table in
//in ascending order
std::sort(_points.begin(), _points.end());
//Ensure that no 2 adjacent x values are equal,
//lest we try to divide by zero when we interpolate.
const double EPSILON{1.0E-8};
for(std::size_t i=1; i<_points.size(); ++i) {
double deltaX{std::abs(_points[i].first - _points[i-1].first)};
if(deltaX < EPSILON ) {
std::string err{"Potential Divide By Zero: Points " +
std::to_string(i-1) + " And " +
std::to_string(i) + " Are Too Close In Value"};
throw std::range_error(err);
}
}
}
double Interpolator::findValue(double x) const {
//Define a lambda that returns true if the x value
//of a point pair is < the caller's x value
auto lessThan =
[](const std::pair<double, double>& point, double x)
{return point.first < x;};
//Find the first table entry whose value is >= caller's x value
auto iter =
std::lower_bound(_points.cbegin(), _points.cend(), x, lessThan);
//If the caller's X value is greater than the largest
//X value in the table, we can't interpolate.
if(iter == _points.cend()) {
return (_points.cend() - 1)->second;
}
//If the caller's X value is less than the smallest X value in the table,
//we can't interpolate.
if(iter == _points.cbegin() and x <= _points.cbegin()->first) {
return _points.cbegin()->second;
}
//We can interpolate!
double upperX{iter->first};
double upperY{iter->second};
double lowerX{(iter - 1)->first};
double lowerY{(iter - 1)->second};
double deltaY{upperY - lowerY};
double deltaX{upperX - lowerX};
return lowerY + ((x - lowerX)/ deltaX) * deltaY;
}
In the constructor, the code attempts to establish the invariant conditions required before any post-construction interpolation can be attempted:
- It sorts the data points in ascending X order – just in case the caller “forgot” to do it.
- It ensures that no two adjacent X values have the same value – which could cause a divide-by-zero during the interpolation computation. If this constraint is not satisfied, an exception is thrown.
Here are the unit tests I ran on the implementation:
#include "catch.hpp"
#include "Interpolator.h"
TEST_CASE( "Test", "[Interpolator]" ) {
//Construct with an unsorted set of data points
Interpolator interp1{
{
//{X(i),Y(i)
{7.5, 32.0},
{1.5, 20.0},
{0.5, 10.0},
{3.5, 28.0},
}
};
//X value too low
REQUIRE(10.0 == interp1.findValue(.2));
//X value too high
REQUIRE(32.0 == interp1.findValue(8.5));
//X value in 1st sorted slot
REQUIRE(15.0 == interp1.findValue(1.0));
//X value in last sorted slot
REQUIRE(30.0 == interp1.findValue(5.5));
//X value in second sorted slot
REQUIRE(24.0 == interp1.findValue(2.5));
//Two points have the same X value
std::vector<std::pair<double, double>> badData{
{.5, 32.0},
{1.5, 20.0},
{3.5, 28.0},
{1.5, 10.0},
};
REQUIRE_THROWS(Interpolator interp2{badData});
}
How can this code be improved?
Bidirectionally Speaking
Given a design that requires a bidirectional association between two peer classes:
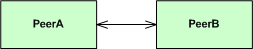
here is how it can be implemented in C++:

Note: I’m using structs here instead of classes to keep the code in this post less verbose
The key to implementing a bidirectional association in C++ is including a forward struct declaration statement in each of the header files. If you try to code the bidirectional relationship with #include directives instead of forward declarations:

you’ll have unknowingly caused a downstream problem because you’ve introduced a circular dependency into the compiler’s path. To show this, let’s implement the following larger design:
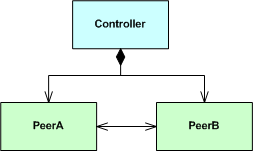
as:

Now, if we try to create a Controller object in a .cpp file like this:

the compiler will be happy with the forward class declarations implementation. However, it will barf on the circularly dependent #include directives implementation. The compiler will produce a set of confusing errors akin to this:
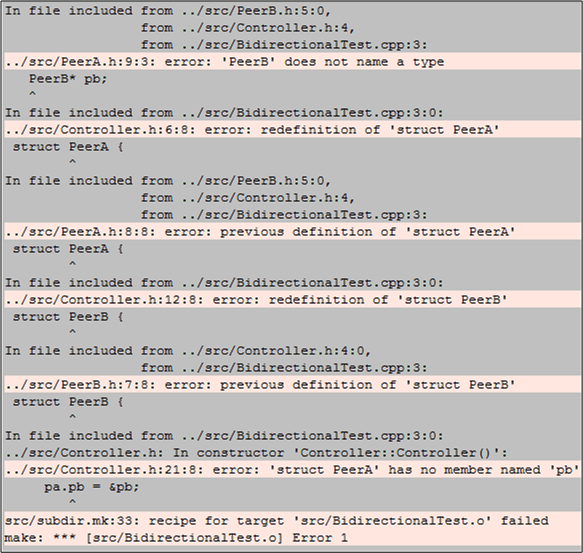
I can’t remember the exact details of the last time I tried coding up a design that had a bidirectional relationship between two classes, but I do remember creating an alternative design that did not require one.
Out With The Old, In With The New
In “old” C++, object factories had little choice but to return unsafe naked pointers to users. In “new” C++, factories can return safe smart pointers. The code snippet below contrasts the old with new.
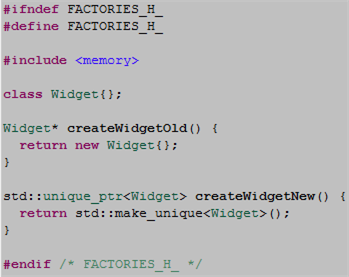
The next code snippet highlights the difference in safety between the old and the new.
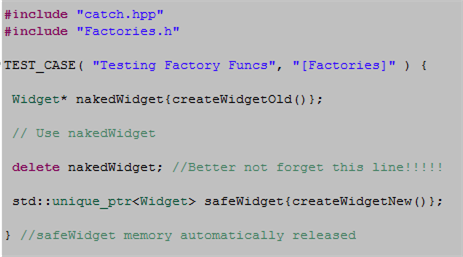
When a caller uses the old factory technique, safety may be compromised in two ways:
- If an exception is thrown in the caller’s code after the object is created but before the delete statement is executed, we have a leak.
- If the user “forgets” to write the delete statement, we have a leak.
Returning a smart pointer from a factory relegates these risks to the dust bin of history.
Politics And C++
Some Twitter parody accounts are just so brilliantly creative..
Ain’t Gonna Do It – Ever
Straight from the Bitcoin Core source code, which is written in C++ (of course!) and is observable for all the world to see (including federal reserve bankstas and other corrupt government fiat currency debasers), we have….
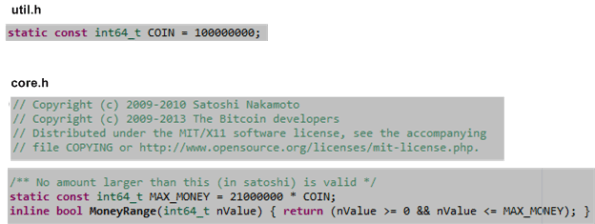
That’s it: no more than 21.0E14 “satoshis” will ever be minted in the Bitcoin world.
Well, you might smugly say, anybody could change the source code to jack up the “MAX_MONEY” and/or “COIN” compile-time constants and release the next update. Uh, yeah, but unless the thousands of BTC miners with peta-flops of hashing power invested in the bitcoin economy voluntarily choose to run the new “inflationary” code, tain’t gonna happen. And, since it would clearly be against their best interests to do so (because it is their money they’re dealing with and not “other people’s money” that they can leach off of) they ain’t gonna do it – ever.
Stack, Heap, Pool: The Prequel
Out of the 1600+ posts I’ve written for this blog over the past 6 years, the “Stack, Heap, Pool” C++ post has gotten the most views out of the bunch. However, since I did not state my motive for writing the post, I think it caused some people to misinterpret the post’s intent. Thus, the purpose of this post is to close that gap of understanding by writing the intro to that post that I should have written. So, here goes…
The figure below shows a “target” entering, traversing, and exiting a pre-defined sensor coverage volume.
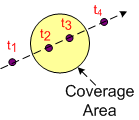
From a software perspective:
- A track data block that represents the real world target must be created upon detection and entry into the coverage volume.
- The track’s data must be maintained in memory and updated during its journey through the coverage volume. (Thus, the system is stateful at the application layer by necessity.)
- Since the data becomes stale and useless to system users after the target it represents leaves the coverage volume, the track data block must be destroyed upon exit (or some time thereafter).
Now imagine a system operating 24 X 7 with thousands of targets traversing through the coverage volume over time. If the third processing step (controlled garbage collection) is not performed continuously during runtime, then the system has a memory leak. At some point after bootup, the system will eventually come to a crawl as the software consumes all the internal RAM and starts thrashing from swapping virtual memory to/from off-processor, mechanical, disk storage.
In C++, there are two ways of dynamically creating/destroying objects during runtime:
- Allocating/deallocating objects directly from the heap using standard language facilities (new+delete (don’t do this unless you’re stuck in C++98/03 land!!!), std::make_shared, or, preferably, std::make_unique)
- Acquiring/releasing objects indirectly from the heap using a pool of memory that is pre-allocated from said heap every time the system boots up.
Since the object’s data fields must be initialized in both techniques, initialization time isn’t a factor in determining which method is “faster“. Finding a block of memory the size of a track object is the determining factor.
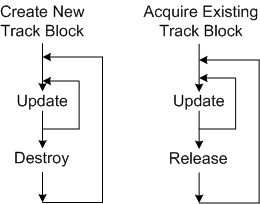
As the measurements I made in the “Stack, Heap, Pool” post have demonstrated, the pool “won” the performance duel over direct heap allocation in this case because it has the advantage that all of its entries are the exact same size of a track object. Since the heap is more general purpose than a pool, the use of an explicit or implicit “new” will generally make finding an appropriately sized chunk of memory in a potentially fragmented heap more time consuming than finding one in a finite, fixed-object-size, pool. However, the increased allocation speed that a pool provides over direct heap access comes with a cost. If the number of track objects pre-allocated on startup is less than the peak number of targets expected to be simultaneously present in the coverage volume at any one instant, then newly detected targets will be discarded because they can’t “fit” into the system – and that’s a really bad event when users are observing and directing traffic in the coverage volume. There is no such thing as a free lunch.

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

