Archive
Mind-To-Code-To-Mind And Mind-To-Model-To-Code
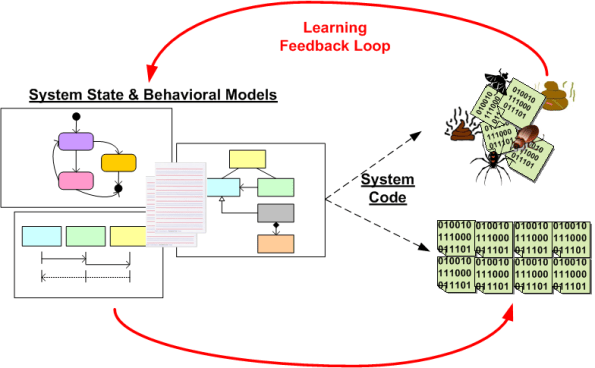
Since my previous post, I’ve been thinking in more detail about how we manage to move an integrated set of static structures and dynamic behaviors out of our heads and into a tree of associated source code files. A friend of mine, Bill Livingston, coined this creative process as “bridging the gap” across the “Gulf Of Human Intellect” (GOHI).
The figure below shows two methods of transcending the GOHI: direct mind-to-code (M2C), and indirect mind-to-model-to-source (M2M2C). The difference is that M2M2C is scale-able where as M2C is not. Note that both methods are iterative adventures.
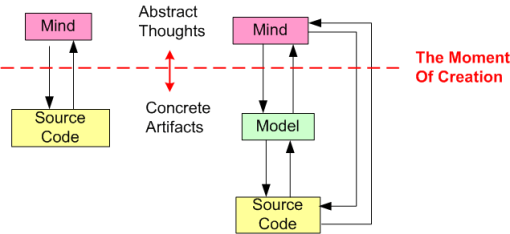
Past a certain system size (7 +/- 2 interconnected chunks?), no one can naturally fit a big system model entirely within their head without experiencing mental duress. By employing a concrete model as a “cache” between the mind and the code, M2M2C can give large performance and confidence boosts to the mind. But, one has to want to actively learn how to model ideas in order to achieve these benefits.
From Mind-To-Code (M2C)
How do we grow from a freshly minted programmer into a well-rounded, experienced, software engineer? Do we start learning from the top-down about abstract systems, architecture, design, and/or software development processes? Or do we start learning from the bottom up about concrete languages, compilers, linkers, build systems, version control systems?
It’s natural to start from the bottom-up; learning how to program “hands on“. Thus, after learning our first language-specific constructs, we write our first “Hello World” program. We use M2C to dump our mind’s abstract content directly into a concrete main.cpp file via an automatic, effortless, Vulcan mind-meld process.

Next, we learn, apply, and remember over time a growing set of language and library features, idioms, semantics, and syntax. With the addition of these language technical details into to our mind space, we gain confidence and we can tackle bigger programming problems. We can now hold a fairly detailed vision of bigger programs in our minds – all at once.
From Mind-To-Model-To-Code (M2M2C)
However, as we continue to grow, we start to yearn of building even bigger, more useful, valuable systems that we know we can’t hold together in our minds – all at once. We turn “upward“, stretching our intellectual capabilities toward the abstract stuff in the clouds. We learn how to apply heuristics and patterns to create and capture design and architecture artifacts.
Thus, unless we want to go down the language lawyer/teacher route, we learn how to think outside of the low level “language space“. We start thinking in terms of “design space“, creating cohesive functional units of structure/behavior and the mechanisms of loosely connecting them together for inter-program and intra-program communication.
We learn how to capture these designs via a modeling tool(s) so we can use the concrete design artifacts as a memory aid and personal navigational map to code up, integrate, and test the program(s). The design artifacts also serve double duty as communication aid for others. Since our fragile minds are unreliable, and they don’t scale linearly, the larger the system (in terms of number of units, types of units, size of units, and number of unit-to-unit interfaces), the more imperative it is to capture these artifacts and keep them somewhat in synch with the fleeting images we are continuously munching on in our mind.
We don’t want to record too much detail in our model because the overhead burden would be too great if we had to update the concrete model artifacts every time we changed a previous decision. On the other hand, we don’t want to be too miserly. If we don’t record “just enough” detail, we won’t be able mentally trace back from the artifacts to the “why?” design decisions we made in our head. That’s the “I don’t know why that’s in the code base or how we got here” syndrome.
A Useful Design Tool
For a modeling tool, we can use plain ole paper sketches that use undecipherable “my own personal notation“, or we can use something more rigorous like basic UML diagrams.
For example, take the static structural model of a simple 3 class design in this UML class diagram:
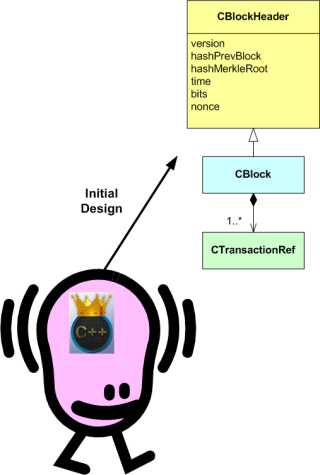
I reverse-engineered this model out of a small section of the code base in an open source software project. If you know UML, you know that the diagram reads as:
- A CBlock “is a” CBlockHeader.
- A CBlock “has” one or more CTransactionRef objects that it creates, owns, and manages during runtime
- A CBlockHeader “has” several data members that it creates, owns, and manages during runtime.
Using this graphic artifact, we can get to a well structured skeleton code base better than trying to hold the entire design in our head at once and then doing that Vulcan mind meld thingy directly to code again.
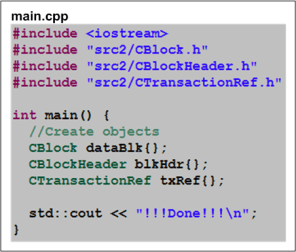
Using the UML class diagram, I coded up the skeletal structure of the program as three pairs of .h + .cpp files. Some UML tools can auto-generate the code skeletons at the push of a button after the model(s) have been manually entered into the tool’s database. But that would be a huge overkill here.

As a sanity-test, I wrote a main.cpp file that simply creates and destroys an object of each type:
From Mind-To-Model-To-Code: Repeat And Rise
For really big systems, the ephemeral, qualitative, “ilities” and “itys” tend to ominously pop up out of the shadows during the tail end of a lengthy development effort (during the dreaded system integration & testing phases). They suddenly, but understandably, become as important to success as the visible, “functional feature set“. After all, if your system is dirt slow (low respons-ivity), and/or crashes often (low reliab-ility ), and/or only accommodates half the number of users as desired (low scala-bility), no one may buy it.
So, in summary, we start out as a junior programmer with limited skills:
Then, assuming we don’t stop learning because “we either know it all already or we’ll figure it out on the fly” we start transforming into a more skilled software engineer.
Advice That Transcends Time
Please take a moment to temporarily push all you’ve learned about large-system software development on the stack in your brain and imbibe some timeless advice from this thoughtful, 1992, NASA report: “Recommended Approach To Software Development“:

Ok, now that you’re done processing what you’ve just seen, you can pop the stack.
What Happened Before The First Product Backlog?
Some people like to ask: “What happened before the big bang?“. Being a geeko-nerd, I like to ask: “What happened before the first product backlog?”.
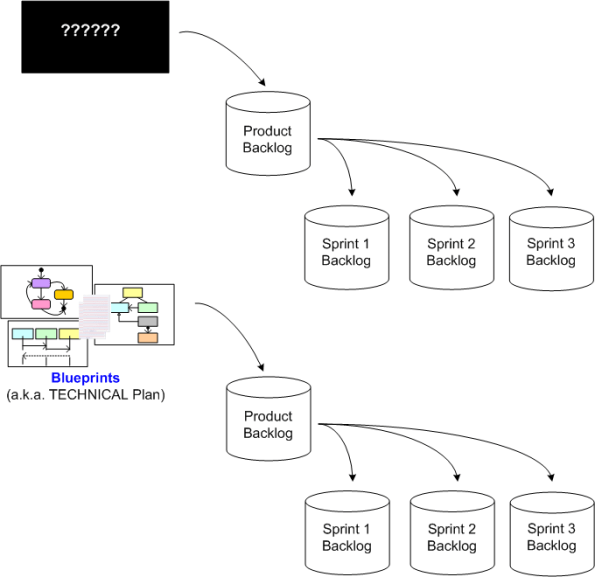
Regarding agile framework definitions, IMO, Scrum has the most well-documented and coherent definition of the bunch. However, since it remains silent on the issue, I still wonder: “WTF happens before the first product backlog?”.
For innately complex systems requiring a large amount of coordinated effort, here’s what I think should happen:
- A small group of senior domain analysts and system architects should spend a fair amount of un-pressured time to develop and document the high level, technical blueprints (structures + behaviors) for what needs to be built.
- The authoring group should disseminate and educate the rest of the development team on the technical vision.
- The team should populate and iterate on the first version of the product backlog.
- The team should decide on, and put in place, the development toolset and infrastructure that will be used to develop and test the system throughout the effort.
- The team, including the technical authors, should start incrementally and iteratively building the system – revisiting/updating the plans/product backlog frequently when new knowledge is discovered as the project moves forward.
What do YOU think should happen before the first product backlog?
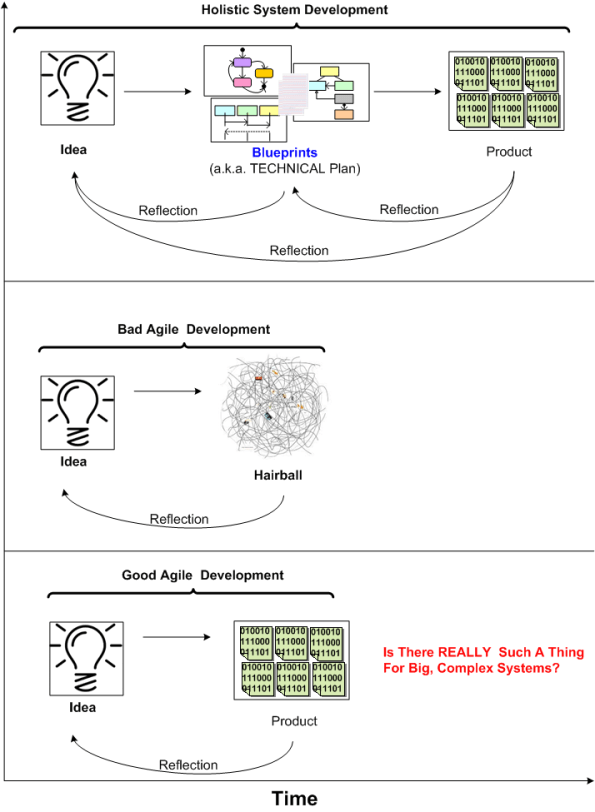
Is There REALLY Such A Thing?
M Of N Fault Detection
Let’s say that, for safety reasons, you need to monitor the voltage (or some other dynamically changing physical attribute) of a safety-critical piece of equipment and either shut it down automatically and/or notify someone in the event of a “fault“.
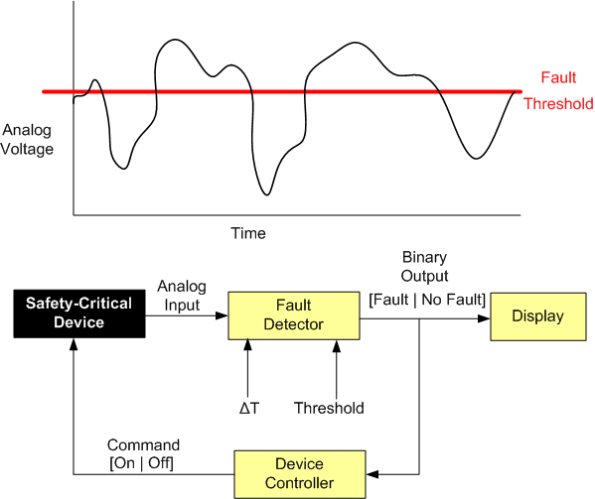
The figure below drills into the next level of detail of the Fault Detector. First, the analog input signal is digitized every ΔT seconds and then the samples are processed by an “M of N Detector”.
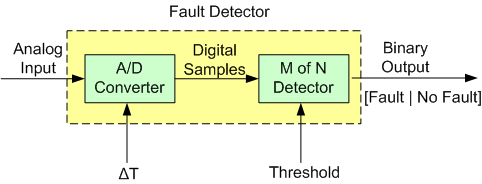
The logic implemented in the Detector is as follows:

Instead of “crying wolf” and declaring a fault each time the threshold is crossed (M == N == 1), the detector, by providing the user with the ability to choose the values of M and N, provides the capability to smooth out spurious threshold crossings.
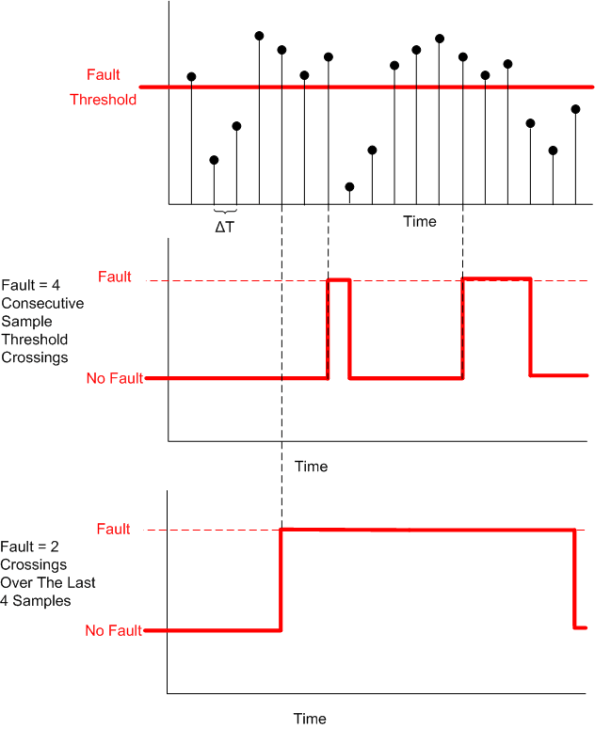
The next figure shows an example input sequence and the detector output for two configurations: (M == N == 4) and (M == 2, N == 4).
Finally, here’s a c++ implementation of an M of N Detector:
#ifndef MOFNDETECTOR_H_
#define MOFNDETECTOR_H_
#include <cstdint>
#include <deque>
class MofNDetector {
public:
MofNDetector(double threshold, int32_t M, int32_t N) :
_threshold(threshold), _M(M), _N(N) {
reset();
}
bool detectFault(double sample) {
if (sample > _threshold)
++_numCrossings;
//Add our newest sample to the history
if(sample > _threshold)
_lastNSamples.push_back(true);
else
_lastNSamples.push_back(false);
//Do we have enough history yet?
if(static_cast<int32_t>(_lastNSamples.size()) < _N) {
return false;
}
bool retVal{};
if(_numCrossings >= _M)
retVal = true;
//Get rid of the oldest sample
//to make room for the next one
if(_lastNSamples.front() == true)
--_numCrossings;
_lastNSamples.pop_front();
return retVal;
}
void reset() {
_lastNSamples.clear();
_numCrossings =0;
}
private:
int32_t _numCrossings;
double _threshold;
int32_t _M;
int32_t _N;
std::deque<bool> _lastNSamples{};
};
#endif /* MOFNDETECTOR_H_ */
The What Before The How
While paging through my portfolio of dorky sketches and e-doodles, I stumbled upon one that I whipped up a long time ago when I was learning about Linux shells:

Unless I’m forced to rush, I always bootstrap my learning experience for new subjects by drawing simplistic, abstract pictures like the above as I study the subject matter. Sometimes I’ll spend several hours drawing contextual pix from the lightweight intro chapter(s) of a skill-acquisition book before diving into the nitty gritty details. It works for me because I’m not smart enough to learn by skimming over the “what” and immediately diving into the “how“.
Whenever I feel forced to bypass the “what” and bellyflop into the “how” (via pressure to produce “Twice The Software In Half The Time“), I make way more mistakes. Not only does it degrade the quality of my work, it propagates downstream and degrades the quality of the receivers/users of that work.
QIQO, GIGO
QIQO == Quality In, Quality Out
GIGO == Garbage In, Garbage Out
In the world of software development, virtually everyone knows what GIGO means. But in case you don’t, lemme ‘splain it to you Lucy. First, let’s look at what QIQO means.
If a domain-specific expert creates a coherent, precise, unambiguous, description of what’s required to be mapped into a software design and enshrined in code, a software developer has a fighting chance to actually create and build what’s required. Hence, Quality In, Quality Out. Of course, QI doesn’t guarantee QO. However, whenever the QI prerequisite is satisfied, the attainment of QO is achievable.

On the other hand, if a domain-specific expert creates a hairball description of what’s required and answers every question aimed at untangling the hairball with sound bytes, a scornful look, or the classic “it’s an implementation detail” response, we get….. GIGO.

Note that the GIGO vs QIQO phenomenon operates not only at the local level of design as pictured above, it operates at the higher, architectural level too; but with much more costly downstream consequences. Also note that the GIGO vs QIQO conundrum is process-agnostic. Its manifestation as the imposing elephant in the room applies equally within the scope of traditional, lean, scrum, kanban, and/or any other wiz-bang agile processes.
Customers, Features, Components
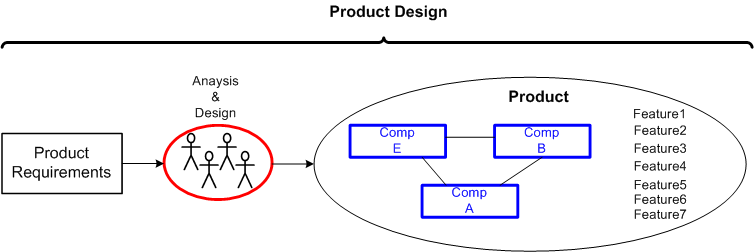
Umm, let’s see. Customers interact with features. Features are implemented across components. Components are designed/coded/tested/integrated by developers. Well, duh!

Design, And THEN Development
First, we have product design:
Second, we have product development:
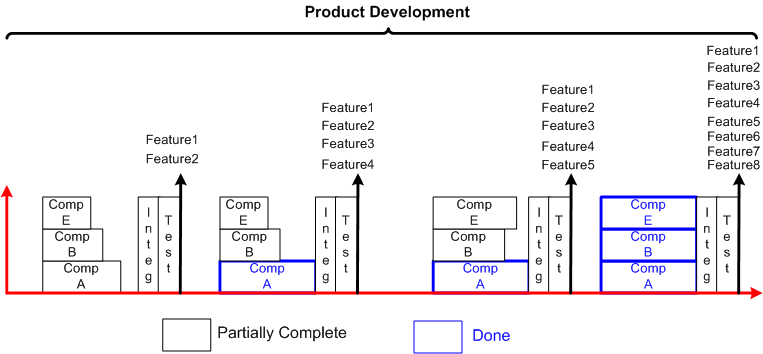
At scale, it’s consciously planned design first, and development second: design driven development. It’s not the other way around, development driven design.
The process must match the product, not the other way around. Given a defined process, whether it’s agile-derived or “traditional“, attempting to jam fit a product development effort into a “fits all” process is a recipe for failure. Err, maybe not?
Turkey Dog
Oh boy oh boy! Turkey, mashed potatoes, sweet potatoes, and stuffing for me!

Burp!!!

ZZZZZZZ!

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

