Archive
Mind-To-Code-To-Mind And Mind-To-Model-To-Code
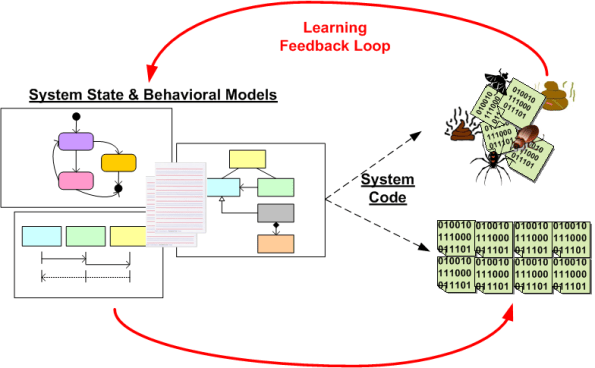
Since my previous post, I’ve been thinking in more detail about how we manage to move an integrated set of static structures and dynamic behaviors out of our heads and into a tree of associated source code files. A friend of mine, Bill Livingston, coined this creative process as “bridging the gap” across the “Gulf Of Human Intellect” (GOHI).
The figure below shows two methods of transcending the GOHI: direct mind-to-code (M2C), and indirect mind-to-model-to-source (M2M2C). The difference is that M2M2C is scale-able where as M2C is not. Note that both methods are iterative adventures.
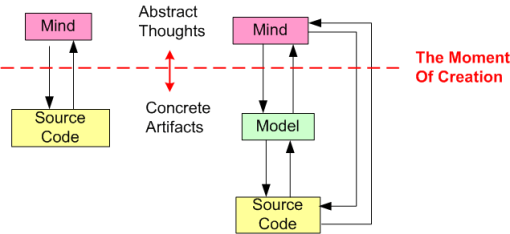
Past a certain system size (7 +/- 2 interconnected chunks?), no one can naturally fit a big system model entirely within their head without experiencing mental duress. By employing a concrete model as a “cache” between the mind and the code, M2M2C can give large performance and confidence boosts to the mind. But, one has to want to actively learn how to model ideas in order to achieve these benefits.
From Mind-To-Code (M2C)
How do we grow from a freshly minted programmer into a well-rounded, experienced, software engineer? Do we start learning from the top-down about abstract systems, architecture, design, and/or software development processes? Or do we start learning from the bottom up about concrete languages, compilers, linkers, build systems, version control systems?
It’s natural to start from the bottom-up; learning how to program “hands on“. Thus, after learning our first language-specific constructs, we write our first “Hello World” program. We use M2C to dump our mind’s abstract content directly into a concrete main.cpp file via an automatic, effortless, Vulcan mind-meld process.

Next, we learn, apply, and remember over time a growing set of language and library features, idioms, semantics, and syntax. With the addition of these language technical details into to our mind space, we gain confidence and we can tackle bigger programming problems. We can now hold a fairly detailed vision of bigger programs in our minds – all at once.
From Mind-To-Model-To-Code (M2M2C)
However, as we continue to grow, we start to yearn of building even bigger, more useful, valuable systems that we know we can’t hold together in our minds – all at once. We turn “upward“, stretching our intellectual capabilities toward the abstract stuff in the clouds. We learn how to apply heuristics and patterns to create and capture design and architecture artifacts.
Thus, unless we want to go down the language lawyer/teacher route, we learn how to think outside of the low level “language space“. We start thinking in terms of “design space“, creating cohesive functional units of structure/behavior and the mechanisms of loosely connecting them together for inter-program and intra-program communication.
We learn how to capture these designs via a modeling tool(s) so we can use the concrete design artifacts as a memory aid and personal navigational map to code up, integrate, and test the program(s). The design artifacts also serve double duty as communication aid for others. Since our fragile minds are unreliable, and they don’t scale linearly, the larger the system (in terms of number of units, types of units, size of units, and number of unit-to-unit interfaces), the more imperative it is to capture these artifacts and keep them somewhat in synch with the fleeting images we are continuously munching on in our mind.
We don’t want to record too much detail in our model because the overhead burden would be too great if we had to update the concrete model artifacts every time we changed a previous decision. On the other hand, we don’t want to be too miserly. If we don’t record “just enough” detail, we won’t be able mentally trace back from the artifacts to the “why?” design decisions we made in our head. That’s the “I don’t know why that’s in the code base or how we got here” syndrome.
A Useful Design Tool
For a modeling tool, we can use plain ole paper sketches that use undecipherable “my own personal notation“, or we can use something more rigorous like basic UML diagrams.
For example, take the static structural model of a simple 3 class design in this UML class diagram:
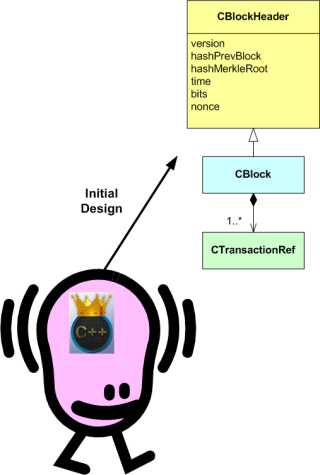
I reverse-engineered this model out of a small section of the code base in an open source software project. If you know UML, you know that the diagram reads as:
- A CBlock “is a” CBlockHeader.
- A CBlock “has” one or more CTransactionRef objects that it creates, owns, and manages during runtime
- A CBlockHeader “has” several data members that it creates, owns, and manages during runtime.
Using this graphic artifact, we can get to a well structured skeleton code base better than trying to hold the entire design in our head at once and then doing that Vulcan mind meld thingy directly to code again.
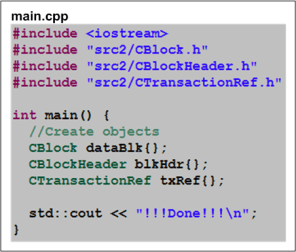
Using the UML class diagram, I coded up the skeletal structure of the program as three pairs of .h + .cpp files. Some UML tools can auto-generate the code skeletons at the push of a button after the model(s) have been manually entered into the tool’s database. But that would be a huge overkill here.

As a sanity-test, I wrote a main.cpp file that simply creates and destroys an object of each type:
From Mind-To-Model-To-Code: Repeat And Rise
For really big systems, the ephemeral, qualitative, “ilities” and “itys” tend to ominously pop up out of the shadows during the tail end of a lengthy development effort (during the dreaded system integration & testing phases). They suddenly, but understandably, become as important to success as the visible, “functional feature set“. After all, if your system is dirt slow (low respons-ivity), and/or crashes often (low reliab-ility ), and/or only accommodates half the number of users as desired (low scala-bility), no one may buy it.
So, in summary, we start out as a junior programmer with limited skills:
Then, assuming we don’t stop learning because “we either know it all already or we’ll figure it out on the fly” we start transforming into a more skilled software engineer.
QIQO, GIGO
QIQO == Quality In, Quality Out
GIGO == Garbage In, Garbage Out
In the world of software development, virtually everyone knows what GIGO means. But in case you don’t, lemme ‘splain it to you Lucy. First, let’s look at what QIQO means.
If a domain-specific expert creates a coherent, precise, unambiguous, description of what’s required to be mapped into a software design and enshrined in code, a software developer has a fighting chance to actually create and build what’s required. Hence, Quality In, Quality Out. Of course, QI doesn’t guarantee QO. However, whenever the QI prerequisite is satisfied, the attainment of QO is achievable.

On the other hand, if a domain-specific expert creates a hairball description of what’s required and answers every question aimed at untangling the hairball with sound bytes, a scornful look, or the classic “it’s an implementation detail” response, we get….. GIGO.

Note that the GIGO vs QIQO phenomenon operates not only at the local level of design as pictured above, it operates at the higher, architectural level too; but with much more costly downstream consequences. Also note that the GIGO vs QIQO conundrum is process-agnostic. Its manifestation as the imposing elephant in the room applies equally within the scope of traditional, lean, scrum, kanban, and/or any other wiz-bang agile processes.
Design, And THEN Development
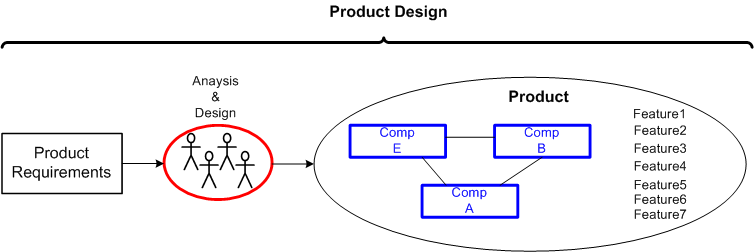
First, we have product design:
Second, we have product development:
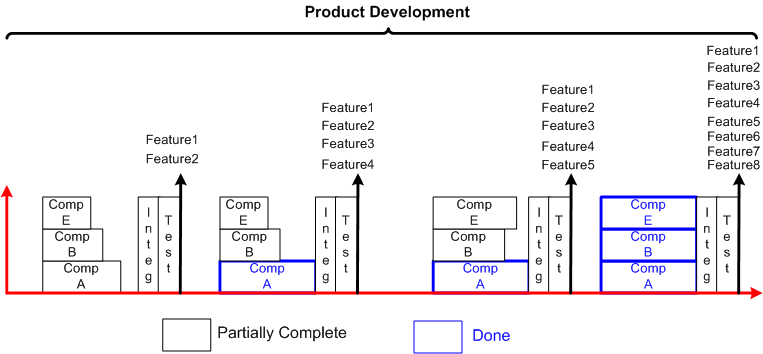
At scale, it’s consciously planned design first, and development second: design driven development. It’s not the other way around, development driven design.
The process must match the product, not the other way around. Given a defined process, whether it’s agile-derived or “traditional“, attempting to jam fit a product development effort into a “fits all” process is a recipe for failure. Err, maybe not?
Is It Safe?
Remember this classic torture scene in “Marathon Man“? D’oh!  Now, suppose you had to create the representation of a message that simply aggregates several numerical measures into one data structure:
Now, suppose you had to create the representation of a message that simply aggregates several numerical measures into one data structure:

Given no information other than the fact that some numerical computations must be performed on each individual target track attribute within your code, which implementation would you choose for your internal processing? The binary, type-safe, candidate, or the text, type-unsafe, option? If you chose the type-unsafe option, then you’d impose a performance penalty on your code every time you needed to perform a computation on your tracks. You’d have to deserialize and extract the individual track attribute(s) before implementing the computations:

If your application is required to send/receive track messages over a “wire” between processing nodes, then you’d need to choose some sort of serialization/deserialization protocol along with an over-the-wire message format. Even if you were to choose a text format (JSON, XML) for the wire, be sure to deserialize the input as soon as possible and serialize on output as late as possible. Otherwise you’ll impose an unnecessary performance hit on your code every time you have to numerically manipulate the fields in your message.

More generally….

Who Dun It?
Assume that the figure below faithfully represents two platform infrastructures developed by two different teams for the same application domain. Secondly, assume that both the JAD and UAS designs provide the exact same functionality to their developer users. Thirdly, assume that the JAD design was more expensive to develop (relative depth) and is more frustrating for developers to use (relative jaggy-ness) than the UAS design.
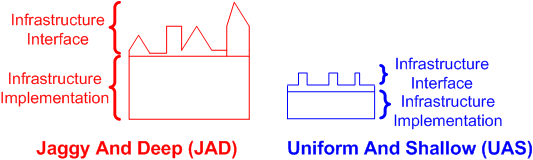
Fourthly, assume that you know that an agile team created one of the platforms and a traditional team produced the other – but you don’t know which team created which platform.
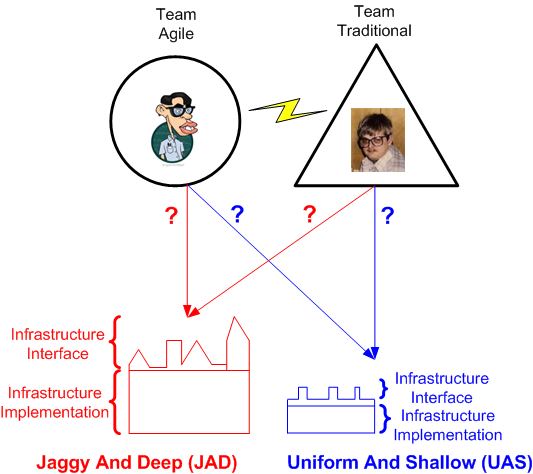
Now that our four assumptions have been espoused, can you confidently state, and make a compelling case for, which team hatched the JAD monstrosity and which team produced the elegant UAS foundation? I can’t.
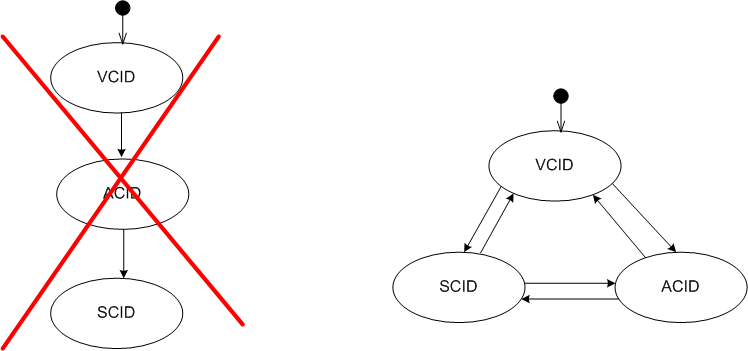
VCID, ACID, SCID
First, we have VCID:
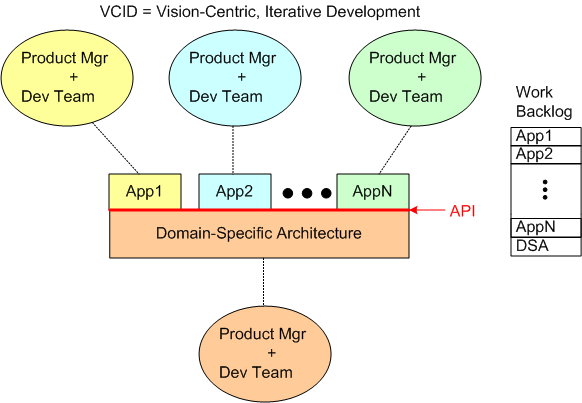
In VCID mode, we iteratively define, at a coarse level of granularity, what the Domain-Specific Architecture (DSA) is and what the revenue-generating portfolio of Apps that we’ll be developing are.
Next up, we have ACID:
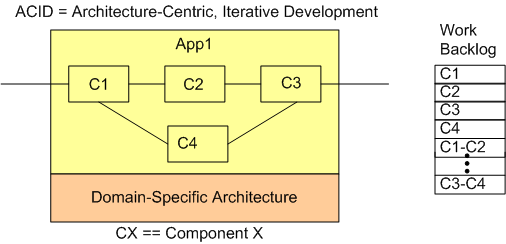
In ACID mode, we’ll iteratively define, at at finer level of detail, what each of our Apps will do for our customers and the components that will comprise each App.
Then, we have SCID, where we iteratively cut real App & DSA code and implement per-App stories/use cases/functions:
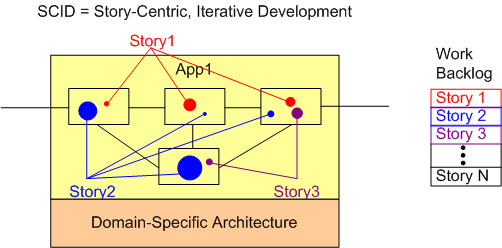
But STOP! Unlike the previous paragraphs imply, the “CID”s shouldn’t be managed as a sequential, three step, waterfall execution from the abstract world of concepts to the real world of concrete code. If so, your work is perhaps doomed. The CIDs should inform each other. When work in one CID exposes an error(s) in another CID, a transition into the flawed CID state should be executed to repair the error(s).
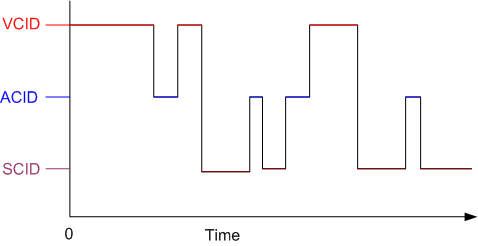
Managed correctly, your product development system becomes a dynamically executing, inter-coupled, set of operating states with error-correcting feedback loops that steer the system toward its goal of providing value to your customers and profits to your coffers.
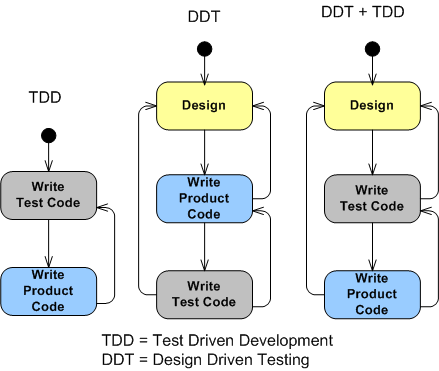
Beware Of Micro-Fragmentation
While watching Neal Ford’s terrific “Agile Engineering Practices” video series, I paid close attention to the segment in which he interactively demonstrated the technique of Test Driven Development (TDD). At the end of his well-orchestrated example, which was to design/write/test code that determines whether an integer is a perfect number, Mr. Ford presented the following side-by-side summary comparison of the resulting “traditional” Code Before Test (CBT) and “agile” TDD designs.
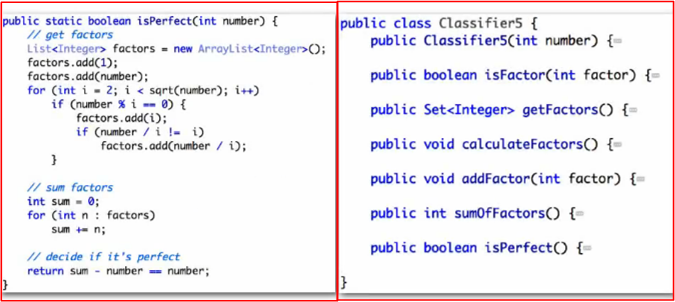
As expected from any good agilista soldier, Mr. Ford extolled the virtues of the TDD derived design on the right without mentioning any downside whatsoever. However, right off the bat, I judged (and still do) that the compact, cohesive, code-all-in-close-proximity CBT design on the left is more readable, understandable, and maintainable than the micro-fragmented TDD design on the right. If the atomic code in the CBT isPerfect() method on the left ended up spanning much more space than shown, I may have ended up agreeing with Neal’s final assessment that the TDD result is better – in this specific case. But I (and hopefully you) don’t subscribe to this, typical-of-agile-zealots, 100% true, assertion:

The downside of TDD (to which there are, amazingly, none according to those who dwell in the TDD cathedral), is eloquently put by Jim Coplien in his classic “Why Most Unit Testing Is Waste” paper:
If you find your testers (or yourself) splitting up functions to support the testing process, you’re destroying your system architecture and code comprehension along with it. Test at a coarser level of granularity. – Jim Coplien
As best I can, I try to avoid being an absolutist. Thus, if you think the TDD generated code structure on the right is “better” than the integrated code on the left, then kudos to you, my friend. The only point I’m trying to make, especially to younger and less experienced software engineers, is this: every decision is a tradeoff. When it comes to your intimate, personal, work habits, don’t blindly accept what any expert says at face value – especially “agile” experts.
Inside-Out, Outside-In
There are two common perspectives on the process of architectural design, whether it be for buildings or for software. The first is that a designer starts with nothing—a blank slate, whiteboard, or drawing board—and builds-up an architecture from familiar components until it satisfies the needs of the intended system. The second is that a designer starts with the system needs as a whole, without constraints, and then incrementally identifies and applies constraints to elements of the system in order to differentiate the design space and allow the forces that influence system behavior to flow naturally, in harmony with the system. Where the first emphasizes creativity and unbounded vision, the second emphasizes restraint and understanding of the system context. – “RESTful” Roy Fielding
It might not be a correct interpretation, but BD00 associates Mr. Fielding’s two alternatives with “inside-out” and “outside-in” design.
The figure below illustrates the process of inside-out design. The designer iteratively composes a structure and “hopes” it will integrate smoothly downstream into the context for which it is intended. During the inside-out design process, the parts are king and the system context is secondary.

The figure below depicts an outside-in design process. The designer iteratively composes a structure within the bounded constraints of the context (the “whole“) for which it is intended. During the outside-in design process, system context is king and the parts are secondary.
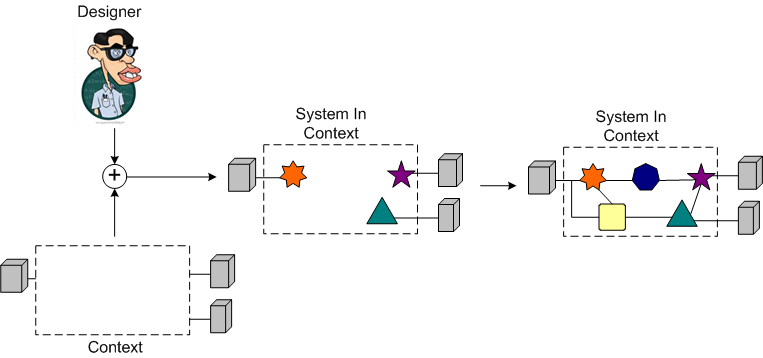
Because system contexts can vary widely from system to system and they’re usually vaguely defined, messy, and underspecified, designers often opt for the faster inside-out approach. BD00 uses the outside-in design process. What process do you use?
Slice By Slice Over Layer By Layer
Assume that your team was tasked with developing a large software system in any application domain of your choice. Also, assume that in order to manage the functional complexity of the system, your team iteratively applied the “separation of concerns” heuristic during the design process and settled on a cleanly layered system as such:

So, how are you gonna manifest your elegant paper design as a working system running on real, tangible hardware? Should you build it from the bottom up like you make a cake, one layer at a time?
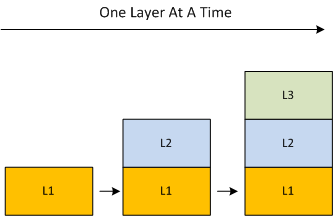
Or, should you build it like you eat a cake, one slice at a time?

The problem with growing the system layer-by-layer is that you can end up developing functionality in a lower layer that may not ever be needed in the higher layers (an error of commission). You may also miss coding up some lower layer functionality that is indeed required by higher layers because you didn’t know it was needed during the upfront design phase (an error of omission). By employing the incremental slice-by-slice method, you’ll mitigate these commission/omission errors and you’ll have a partially working system at the end of each development step – instead of waiting until layers 1 and 2 are solid enough to start adding layer 3 domain functionality into the mix.
In the context of organizational growth, Russell Ackoff once stated something like: “it is better to grow horizontally than vertically“. Applying Russ’s wisdom to the growth of a large software system:
It’s better to grow a software system horizontally, one slice at a time, than vertically, one layer at a time.
The above quote is not some profound, original, BD00 quote. It’s been stated over and over again by multitudes of smart people over the years. BD00 just put his own spin on it.
Abstract Decomposition And Concrete Composition
On the left we have the process of abstract decomposition, and on the right we have the process of concrete composition:
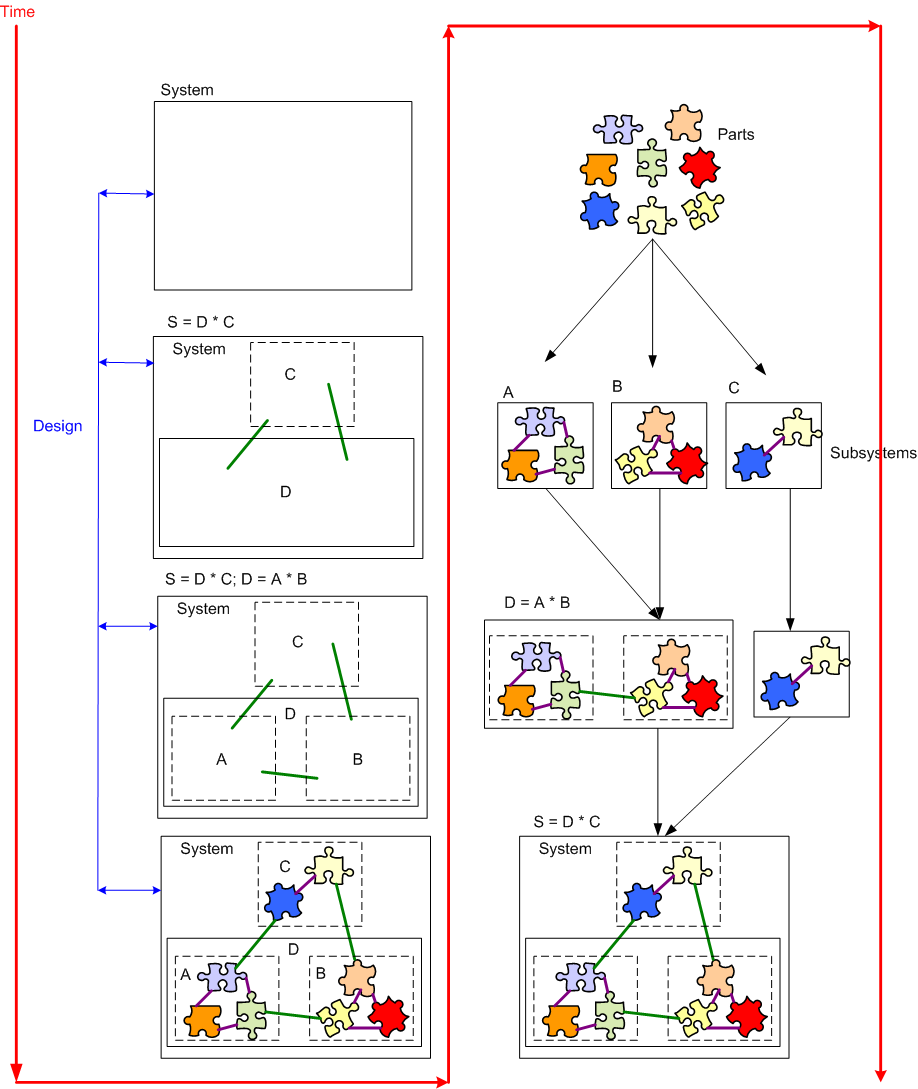
Note that during the concrete composition from parts to final system on the right, we gracefully transition through two stable, intermediate forms. Some people and communities, especially those obsessed with “velocity” and “time-to-market“, would say “bollocks” to all those value-subtracting, intermediate steps. We no need no stinking intermediate forms:
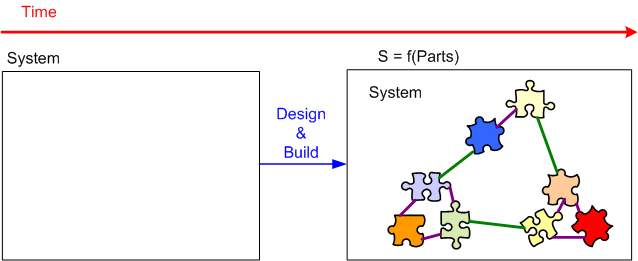
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

