Archive
The Ability To Steer And Stabilize
A few weeks ago I noticed an abrupt deterioration in my ability to steer and stabilize my right leg. Since the leg has been devolving steadily (but relatively slowly) ever since I was diagnosed with metastases to the brain, I was alarmed at suddenly waking up to my extra–numb, tight-as-a-drum, painful and crampy leg. It may be tough to imagine, but please believe me when I say that you can have both a painful AND numb leg at the same time. The pain comes from frequent pop-up cramps (where muscles get so tight the ligaments feel like they’re detaching from bone) up and down the entire leg/foot whereas the numbness comes from a loss of tactile feeling and control.
After dueling with competing thoughts on whether to walk around the block or not, I decided to give it a go since one of my goals is to do the daily waddle until the fit hits the shan. When I embarked on the journey, I detected my leg getting more numb and heavy with just about every step. I felt like I was playing darts, just randomly throwing my leg out in front of me on each step and hoping it would land close to where I intended it to go. It got to the point where I had to turn around and hastily go back home. I was concerned (um, I was actually scared) that my leg might go completely jello, buckle beneath me, and leave me stranded on the side of the road calling out for help like the “I’ve fallen and I can’t get up!” lady.

When I made it back home safely, another frightful thought (there’s never just one scary thought, it’s always a cancerous cluster) came to mind: perhaps the brain tumor camping out on the motor strip that controls my right leg started growing, or, in cancer-speak, progressing, again. After the now-familiar wave of “uh oh, the descent has finally commenced and I’m on my way out” terror washed over me, I hastily checked to see when my next brain MRI was scheduled for. When I saw that it was almost a month away I decided to call my neurosurgeon and ask about moving it up. To my great relief, he accommodated my request. I had the scan done last week and the result showed no tumor progression. Hallelujer!
Since the shackled tumor isn’t the cause of the encroaching electro-mechanical deterioration, my neurosurgeon and oncologist both think it may be long term cumulative nerve damage due to the multiple cyberknife radiation hits I absorbed. The toxic nuclear bombardment may be melting away the myelin sheathing that protects nerves from external threats. Yuk, and D’oh!
Every time the ever-vigilant Emperor Of All Maladies detects he’s losing thought-share and being nudged out of mind, the evil bastid reasserts himself and takes back his rightful place at the front of the line with jolting thoughts of despair and death. At this point in my 5 year tango with the devil’s disciple, the psychological battle has become more taxing than the physical battle. I just hope I don’t have to add anymore chemicals to my gabapentin, klonopin, lamotrigine, and weed regimen. With all that shite sloshing around upstairs it’s amazing I can even think at all. The only thing I remember about my former life as a C++ programmer is that this compiles: void main(){}

Ploddingly Slow, But Thorough
I cracked open one of my C++ programming books recently and started leafing through it in the hope of stirring up some warm memories of my use of the language to wrestle embedded systems problems into submission. Instead, I immediately experienced a moment of existential horror! My cherished language of choice all of a sudden looked like an intimidating, unfathomable, encrypted mess. I thought for a moment that I was having my second stroke.
It’s scary at how one can forget so much so fast unless one arduously burns calories to maintain a high level of competence in an area crucial for putting food on the table.
After regaining my bearings, I realized that most programmers who know other languages but don’t know C++ experience an instance of the same abject terror when they scrutinize C++ code for the first time. It’s too bad, but it is what it is.

Before my life was abruptly upended by the Emperor, I used to be a ploddingly slow, but thorough, C++ programmer. But as anyone who has read this blog quickly discovered, I ain’t never been no genius. I had to work much harder and longer than most to become a C++ craftsman. Malcolm Gladwell’s “10,000 hours to become a subject matter expert” threshold to prosperity is too low of a bar to apply to dumschitts like me. I needed 2X the time to become internally confident that I was an excellent C++ programmer. It was a difficult but satisfying road to travel because my mind was richly rewarded with the excitement of learning something new whenever I danced with C++’s exquisitely rich feature set and its “std::” (affectionately pronounced as “stood” 🙂 ) libraries in my head.

While coding away on problems, I was always thinking in the background about what I could do to help future maintainers understand the code ASAP so they could get something done without getting frustratingly stuck. I’m embarrassed and sad to admit it, but it was more of a classic, fear-based, ego-driven mission than an altruistic one. I was afraid of feeling like schitt whenever I envisioned colleagues reading my code. I yearned for everyone who read the code to say “Wow, I wish I knew this maestro!“, instead of “WTF!” after every few lines.

To drill deeper into what I’m exposing here about my dark passenger, I was firmly in the clutches of the “impostor syndrome” for most of my undecorated career. But hey, despite the fact that Stroustrup, Sutter, Meyers, Josuttis, Kalb, Lavavej, Lakos, Williams, Carruth, Niebler, Boehm, Alexandrescu, Gregory, Davidson caused my cancer ( <– just joking), it was a fun, multi-decade, journey down the C++ rabbit hole. I’m extremely gratefuI that all of those wonderful teachers took me along for the adventure.

In closing out this post, I remembered the need to blatantly include some Bitcoin propaganda in it. So, say ‘ello to my leetle friend…

I wish the tat was orange instead of black, but the artist didn’t have any orange ink in her pallet. I’ll make sure my upcoming neck tat is full Satoshi orange though.
Encrypting/Decrypting For Confidentiality
Depending on how they’re designed, there are up to 5 services that a cryptographic system can provide to its users:

In my last post, “Hashing For Integrity“, we used the Poco.Crypto library to demonstrate how one-way hash functions can provide for message integrity over unsecured communication channels. In this post, we’ll use the library to “Encrypt/Decrypt For Confidentiality“.
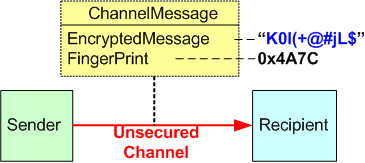
The figure below shows how a matched symmetric key/cipher pair provides the service of “confidentiality” to system users. Since they are “symmetric“, the encryption key is the same as the decryption key. Anyone with the key and matching cipher can decrypt a message (or file) that was encrypted with the same key/cipher pair.
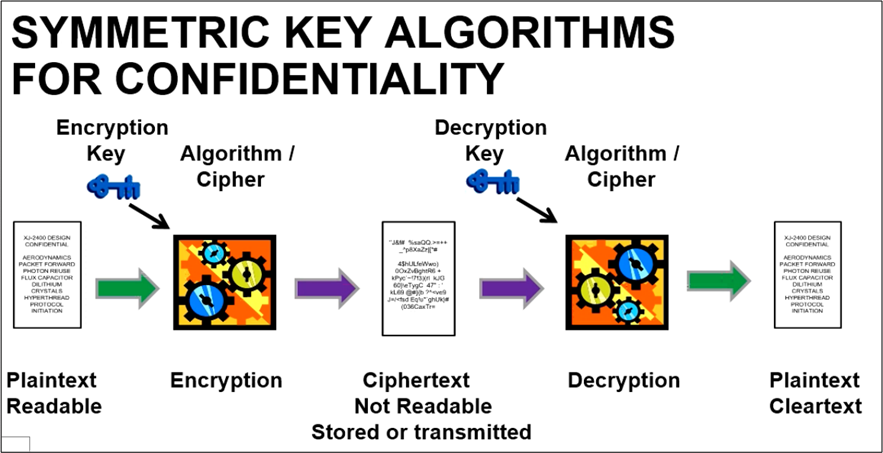
The gnarly issue with symmetric key cryptographic sytems is how to securely distribute copies of the key to those, and only those, users who should get the key. Even out-of-band key transfers (via e-mail, snail mail, telephone call, etc) are vulnerable to being intercepted by “bad guys“. The solution to the “secure key distribution” problem is to use asymmetric key cryptography in conjunction with symmetric key cryptography, but that is for a future blog post.
To experiment with symmetric key encryption/decryption using the Poco.Crypto library, we have added a MyCrypto class to the bulldozer00/PocoCryptoExample GitHub repository.

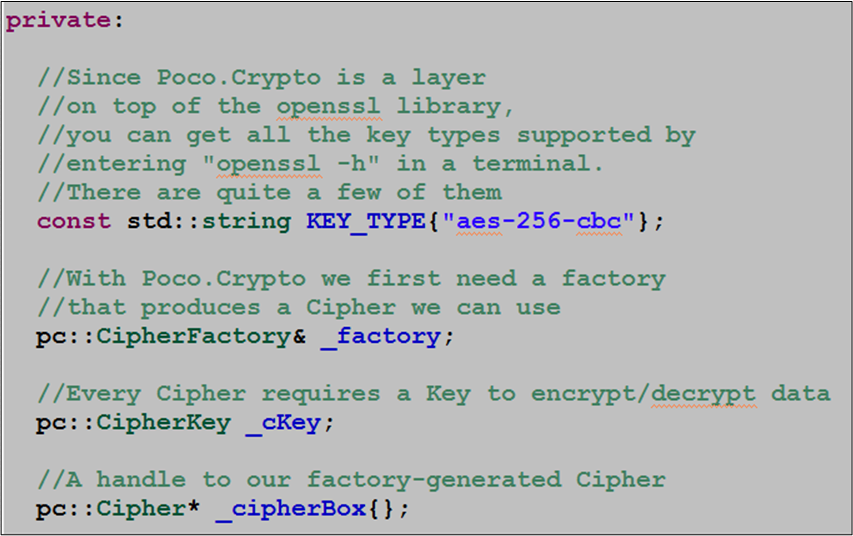
The design of the Poco.Crypto library requires users to create a CipherKey object directly, and then load the key into a Cipher acquired through a CipherFactory singleton.
The MyCipher class data members and associated constructor code are shown below:
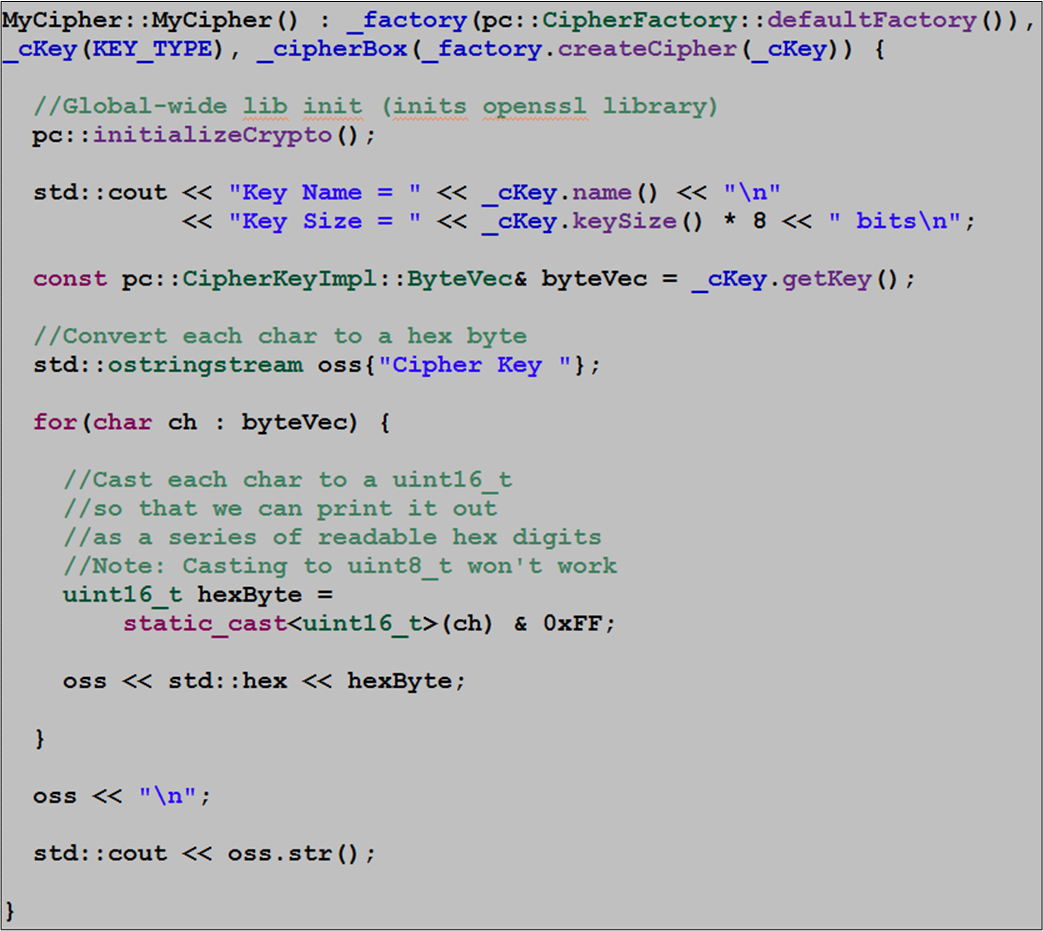
After the MyCipher constructor has finished executing, the following CipherKey characteristics appear in the console:

Note that for human readability, the 256 bit key value is printed out as a series of 64, 4 bit hex nibbles.
So, where did we get the “aes-256-cbc” key name from, and are there different key generation algorithms that we could’ve used instead? We got the key name from the openssl library by entering “openssh -h” at the command line:
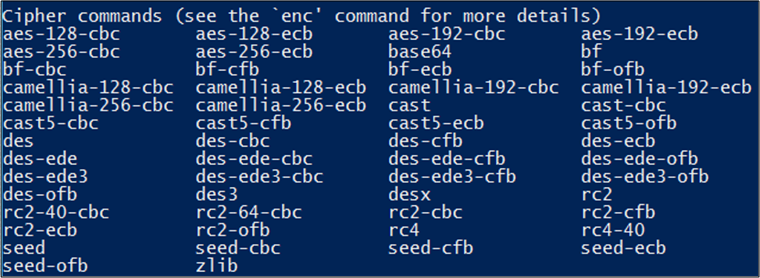
Using “des-ede” as the key name, we get the following console output after the constructor has finished executing:

The number of bits in a CipherKey is important. The larger the number of bits, the harder it is for the bad guys to crack the system.
So, now that we have a matched CipherKey and Cipher object pair, let’s put them to use to encrypt/decrypt a ClearText message. As you can see below, the Poco.Crypto library makes the implementation of the MyCipher::encryptClearTextMsg() and MyCipher::decryptCipherTextMsg() member functions trivially simple.
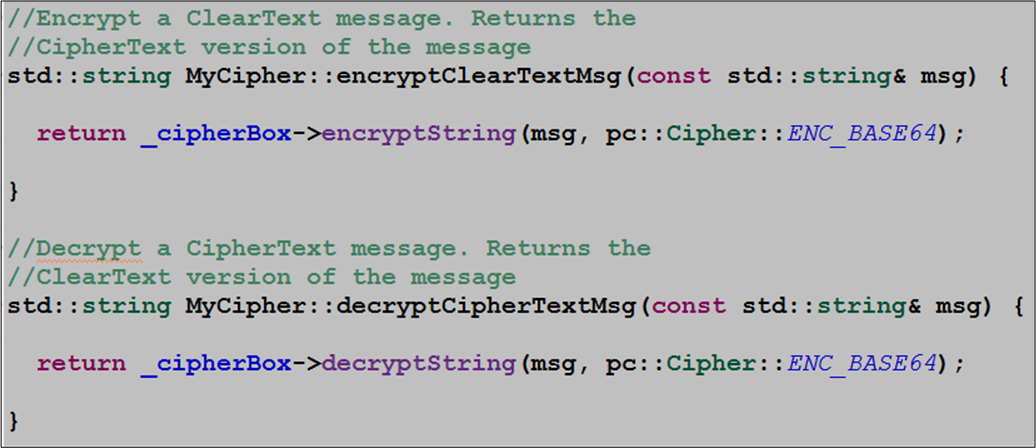
The unit test code that ensures that the ClearText message can be encrypted/decrypted is present in the MyCipherTest.cpp file:
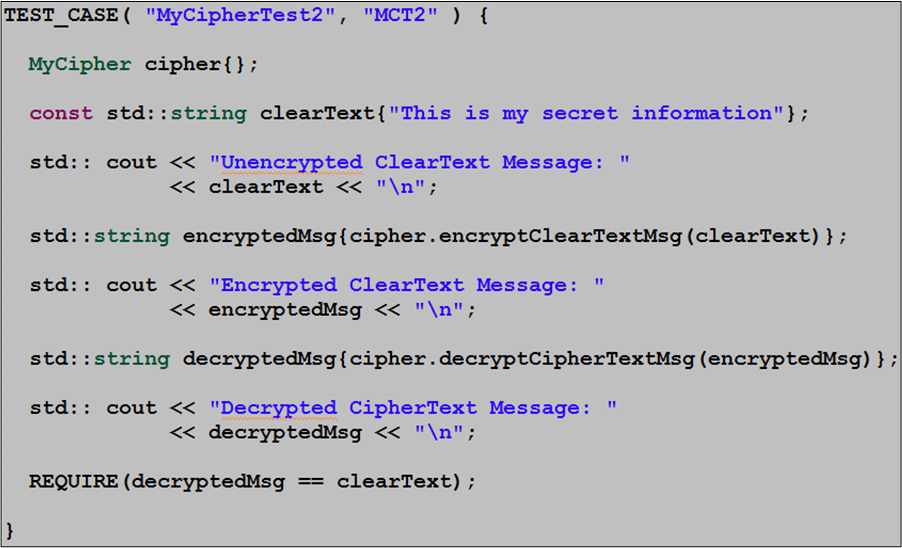
The console output after running the test is as anticipated:

So, there you have it. In this post we employed the Poco.Crypto library to learn how to use and test the facilities provided by the library to simulate a crypto system that provides its users with confidentiality using encryption/decryption. I hope this post was useful to those C++ programmers who are interested in cryptographic systems and want to get started coding with the Poco.Crypto library.
Hashing For Integrity
Introduction
Before I discovered the wild and wacky world of Bitcoin, I didn’t pay much attention to cryptography or system security. Those intertwined subject areas, though important, seemed boring to me. Plus, the field is loaded with all kinds of rich, complex, terminology and deep, bit-wise, computationally-intensive, mathematical computations:
Symmetric/Asymmetric key generation algorithms, secure key distribution, private/public key pairs, block and bitstream cipher algorithms: DES, 3DES, AES, Blowfish, encryption by substitution/translation, hashing algorithms for integrity: MD5, RSA, SHA1, SHA2, RIPEMD-160, digital signatures, message digests, confidentiality, authentication, non-repudiation.
But now that I’m a “Bitcoiner“, all these topics suddenly seem interesting to me. Thus, I decided to look for a C++ Crypto library and write some buggy, exploratory, code to learn what the hell is going on.
Out of the gate, I didn’t want to get bogged down or overwhelmed by interfacing directly with the bedrock openssl C library API which underpins most higher level Crypto libraries. I wanted an easier-to-use, abstraction-oriented wrapper library on top of it that would shield me from all of the low level details in openssl.
I didn’t have to look far for a nice C++ Crypto library. Poco has a Crypto library. Poco is a well-known, highly polished, set of general purpose, open source libraries/frameworks that is widely deployed across the globe.
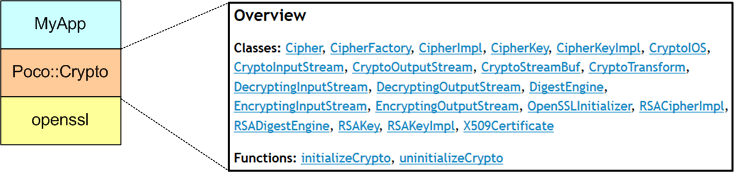
The next thing I needed to do was to narrow down the scope of the project. Instead of hacking together some big complicated application, I decided to learn how “hashing achieves message integrity“.
Hashing For Integrity
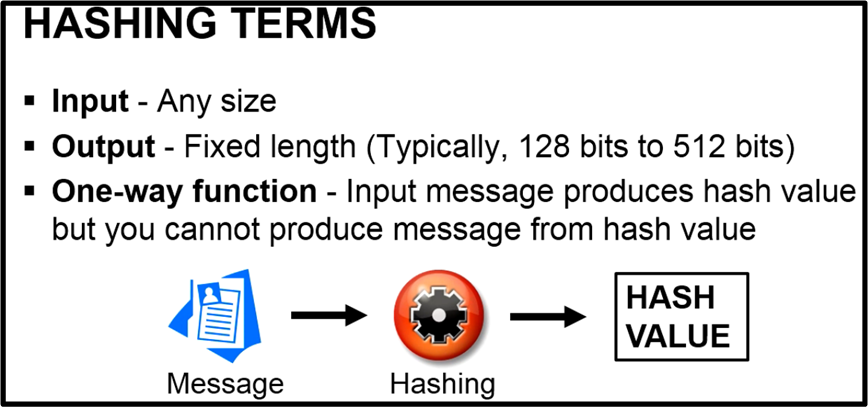
A hash is a one-way function. When a message, large or small, is sent through a hashing algorithm, the resulting output is NOT an encrypted message that can be decrypted further downstream. It’s a simple, fixed size (in terms of number of bits) value also known as a message “fingerprint“, or “digest“.
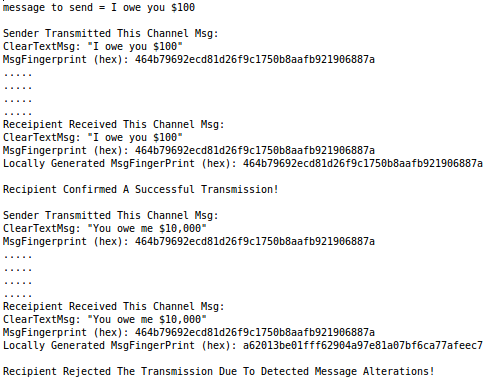
Let’s say “I owe you $100” and you want an acknowledgment from me of that fact. I could write it down on paper, sign the note, and give it to you. My signature conveys the fact that I authorized the IOU and it gives the message a degree of integrity.
If you received the note without my signature, I could deny the IOU and I could deny ever sending the note to you. I can even say that you made it up out of thin air to scam $100 from me.
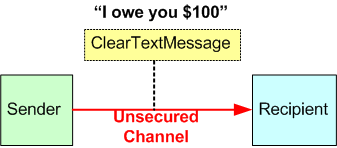
By providing you with an electronic version of the “I owe you $100” note AND a fingerprint in the form of a hash value derived from the content of the note, you could at least verify that the note content is legit and hasn’t been tampered with.
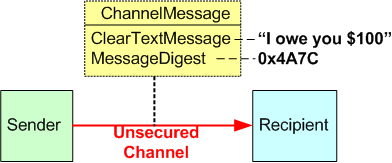
You would do this verification by locally running the note content through the exact same hash function I did, and then comparing your hash value with the fingerprint/digest supplied directly with the note. If they match, then the note is legit. Otherwise, it means that the note was “altered” sometime after I generated the first hash value. Any little change, even a one bit mutation to the message, invalidates the fingerprint derived from the unaltered message. That’s the nature of hashing.
Using Poco::Crypto::SHA1Engine For Hashing
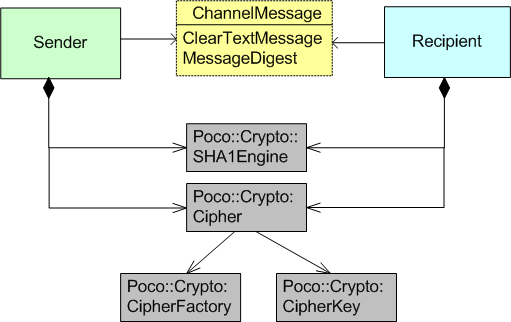
The class diagram in the figure below shows what I needed from the Poco.Crypto library in order to code up and simulate the behavior of a hashing system.
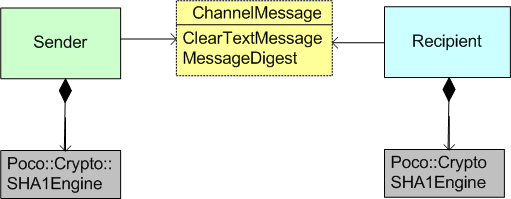
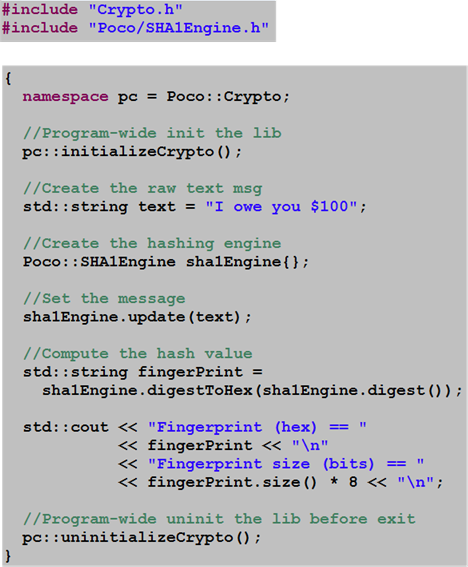
The Poco::Crypto:SHA1Engine class implements the SHA-1 message digest algorithm. (FIPS 180-1, see (http://www.itl.nist.gov/fipspubs/fip180-1.htm) ). Here’s a simple code usage example in which: an engine is created, a message is sent to it, and a hash value is returned:
The following console output from the code shows that the SH1Engine, in its default configuration, generates 160 bit hash values. The SH1Engine::digestToHex() converts the bit pattern into 40, 4bit, nibbles and returns a human-readable hexidecimal string:
![]()
The PocoCryptoExample Project
Using the Eclipse CDT, I coded up the design in the class diagram from the previous section. The PocoCryptoExample source tree is available on GitHub here: https://github.com/bulldozer00/PocoCryptoExample. All you have to do is download the source tree, import it into Eclipse as “an existing Eclipse project“, and build the executable using the internal CDT builder (see README.md).
The test driver code that exercises the design (in MessageIntegrityTest.cpp) is as follows:
- Initializes the Poco Crypto library (which in turn initializes the openssl library).
- Creates the Sender, Recipient, and the “I owe you $100” message.
- Invokes the Sender to compute the message fingerprint, set the message and fingerprint within a ChannelMessage, and transmit the result to the Recipient.
- Upon receipt of the transaction status (success/failure) back from the Recipient, the test driver prints the result to the console.
The test driver then:
- Commands the Sender to simulate a man-in-the-middle attack by maliciously changing the message content to “You owe me $10,000” and sending a new ChannelMessage to the Recipient without changing the fingerprint from the prior ChannelMessage.
- Upon receipt of the transaction status (success/failure), the test driver prints the result to the console.
- Uninitializes the Poco Crypto library (which in turn uninitializes the openssl library) and exits.
Here is the console output produced by the program:
 What’s Next?
What’s Next?
A next step in the learning process can be to integrate a Poco::Crypto::Cipher class into the design so that message encryption/decryption capability can be added. As you can see from the example code on the Poco Cipher API page, it’s not as easy as adding the SHA1Engine. It is more difficult to create/use a Cipher object because the class depends on the CipherFactory and CipherKey classes.
With those additions, we can simulate sending an encrypted and fingerprinted (integrity AND confidentiality) message to “matched” Recipients who have the same Poco.Crypto objects in their code. A Recipient would then use the SH1Engine to first check that the fingerprint belongs to the message. If the message passes that test, the recipient would then use the Cipher to decrypt the message content.
You know what would be great? If the ISO C++ standards committee added a <crypto> library to the C++ standard library to complement the impressive random number generation and probability distribution functionality available in <random>.
Sloppy Coding II
Introduction
In the prequel to this post, “Sloppy Coding“, I showed some rather trivial, small-scoped, examples of antiquated C++ coding style currently present in a hugely successful, widely deployed, open source code base. In this follow up post, I’ll do the same, but at the higher, class level scope.
Hey, I troll often, and this is what trollers do. 🙂

The Class Definition Under Assault
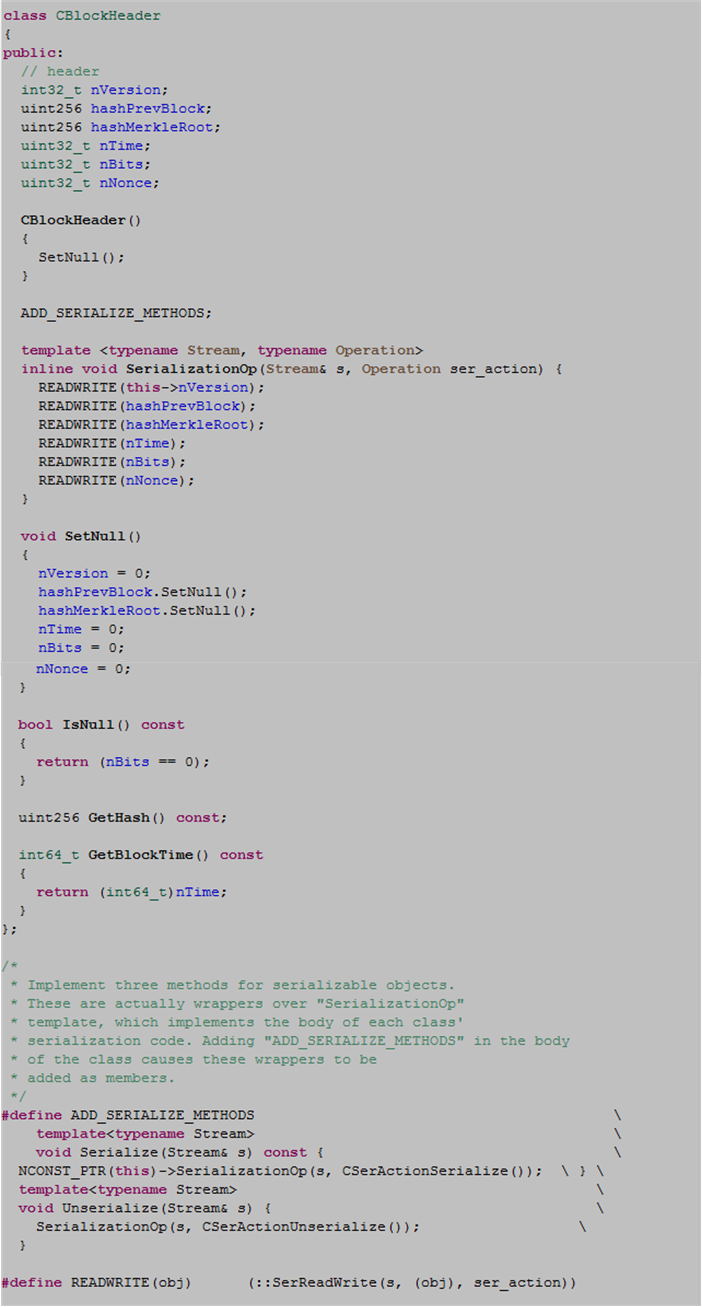
If you’re a young, advancing, C++ programmer, you may want to think about avoiding the bad design decisions that I rag about in the following class definition:
Where Are The Private Members?
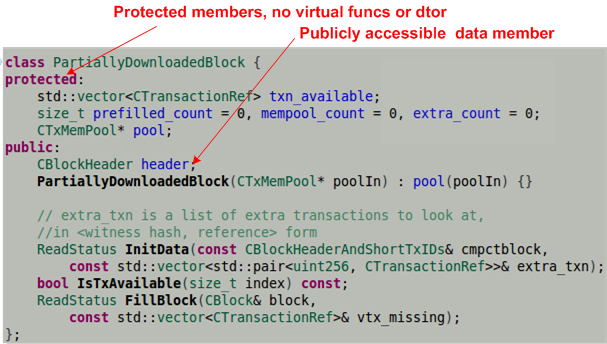
After scanning through the class definition for the first time, the most blatantly obvious faux pax I noticed right off the bat was the “everything is public!” violation of the golden rule of encapsulation. If the intent was for CBlockHeader to be a user-defined type with no need to establish and preserve any invariant conditions, then it should have been declared as a less verbose struct .
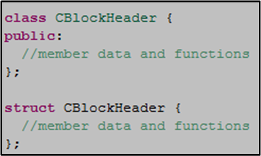
I know, I know, that’s another nitpick. But there’s more to it than meets the eye. Notice the last three CBlockHeader class member functions are declared const. Since users can directly reach into a skinless CBlockHeader object to mutate its internal state at will, nice users can be unsafely stomped on by cheaters (Jihan Wu? 🙂 ) in between calls.
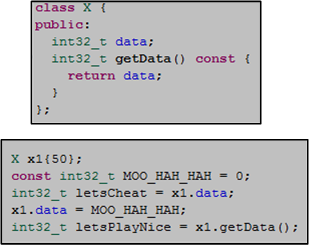
The cheater gets the 50, and the nice guy gets the goose egg.
Where Are The Initializers?
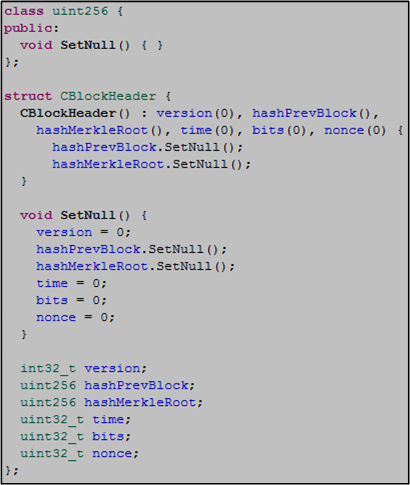
Notice that the CBlockHeader class constructor does not contain an initialization list – all initialization is performed in the constructor body via a call to SetNull().
An initialization explicitly states that initialization, rather than assignment, is done and can be more elegant and efficient (CppCoreGuidelines). It also prevents “use before set” errors. For a slight performance bump upon each CBlockHeader object instantiation and good C++ style, the struct implementation of the CBlockHeader constructor should look like this, no?
Nasty Pre-processor Hackros, Turtles All The Way Down
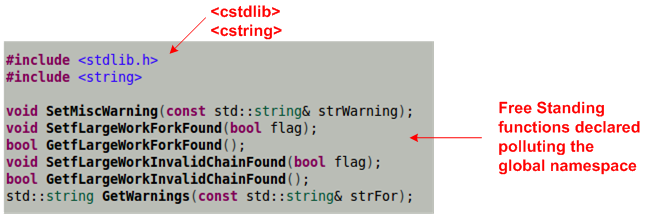
Ugh, I don’t even know what to say about the dangerous 1980’s C pre-processor macro bombs planted in the class definition: ADD_SERIAL_METHODS, NCONST_PTR (nested within ADD_SERIAL_METHODS) , and READWRITE. Compared to the design flaws pointed out previously, these abominations make the class uncomfortably uninhabitable for a large population of otherwise competent C++ programmers.
Bjarne Stroustrup is the creator of C++ and a long time hero of mine. He’s been passionately evolving the language (C With Classes, C++, C++98, C++11, C++14, C++17) and a leading force in the community since the 80s. Mr. Stroustrup has this to say about Hacros:

A safer, more maintainable, alternative to the current Hack-Horiffic design would be to wrap the required inline functionality in class templates and have CBlockHeader publicly extend those classes. The details are left to the aspiring student.
Fini
Ok, ok. EVERYONE on social media knows that trolls beget trolls. So, troll away at this post. Rip me to shreds. I deserve payback.

Sloppy Coding

This sloppy code runs a $20 billion, bleeding edge, financial system. I’ve written, and still do write, sloppy production code like this. However, some of the key stewards of this particular code base think they walk on water.
Subtle And Quirky, But Still Lovable
I’m a long time C++ programmer who’s going to expose something embarrassing about myself. As a starting point, please take a look at the code below:

The first std::cout statement prints out the letter A and the second one prints out B. Here comes the embarrassing part… I erroneously thought that both the map::insert() and map::operator[] functions expressed the same semantics:
If the map object already contains an entry for the key being supplied by the user in the function call, the value supplied by the user will not be copied into the map.
Applied to the specific example above, before running the program I thought both std::cout statements would print the letter A.
Of course, as any experienced C++ programmer knows (or, in my case, should know), this behavior is only true for the map::insert() function. The map::operator[] function combined with the assignment operator will always copy the value into the map – regardless of whether or not an entry for the key is already present in the map. It makes sense that the two functions behave differently because sometimes you want an unconditional copy and sometimes you don’t.
The reason I wrote this post is because I very recently got burned by my incorrect assumption. To make a long story short, there was a bug in my large program that eventually was traced, with the help of the simple code example above, to the bad line of code that I wrote using map::operator[]. A simple change to map::insert() fixed the bug. It was critical to the application that an existing value in the map not be overwritten.
One of the dings against C++ is that it contains a lot of subtle, quirky semantics that are difficult for mere humans to remember. Despite agreeing with this, I still love the ole language that keeps on chugging forward like the little train that could (direct mapping to the hardware and zero overhead abstraction), despite the chagrin of many in the software industry:
I consider C++ the most significant technical hazard to the survival of your project and do so without apologies – Alistair Cockburn
The “unsigned” Conundrum
A few weeks ago, CppCon16 conference organizer Jon Kalb gave a great little lightning talk titled “unsigned: A Guideline For Better Code“. Right up front, he asked the audience what they thought this code would print out to the standard console:

Even though -1 is obviously less 1, the program prints out “a is not less than b“. WTF?
The reason for the apparently erroneous result is due to the convoluted type conversion rules inherited from C regarding unsigned/signed types.
Before evaluating the (a < b) expression, the rules dictate that the signed int object, a, gets implicitly converted to an unsigned int type. For an 8 bit CPU, the figure below shows how the bit pattern 0xFF is interpreted differently by C/C++ compilers depending upon how it is declared:
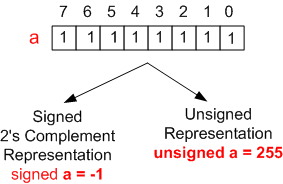
Thus, after the implicit type conversion of a from -1 to 255, the comparison expression becomes (255 < 1) – which produces the “a is not less than b” output.
Since it’s unreasonable to expect most C++ programmers to remember the entire arcane rule set for implicit conversions/promotions, what heuristic should programmers use to prevent nasty unsigned surprises like Mr. Kalb’s example? Here is his list of initial candidates:

If you’re trolling this post and you’re a C++ hater, then the first guideline is undoubtedly your choice :). If you’re a C++ programmer, the second two are pretty much impractical – especially since unsigned (in the form of size_t) is used liberally throughout the C++ standard library. (By the way, I once heard Bjarne Stroustrup say in a video talk that requiring size_t to be unsigned was a mistake). The third and fourth guidelines are reasonable suggestions; and those are the ones I use in writing my own code and reviewing the code of others.
At the end of his interesting talk, Mr. Kalb presented his own guideline:

I think Jon’s guideline is a nice, thoughtful addition to the last two guidelines on the previous chart. I would like to say that “Don’t use “unsigned” for quantities” subsumes those two, but I’m not sure it does. What do you think?
Plugging Those Leaks
It’s been 5 years since modern C++ arrived on the scene in the form of the C++11 standard. Prior to the arrival, C++ was notorious for memory leaks and segmentation faults due to the lack of standardized smart pointers (although third party library and home grown smart pointers have existed for decades). Dangerous, naked news and deletes could be found sprinkled across large code bases everywhere – hidden bombs waiting to explode at any moment during runtime.
I don’t know how many over-confident C++ programmers are still using the old new/delete pattern in new code bases, but if your team is one of them please consider hoisting this terrific poster on the walls of your office:

ISO WG-21 C++ committee convener Herb Sutter, a tireless and passionate C++ advocate for decades, presented this poster in his CppCon 2016 talk “Leak Freedom In C++: By Default“. Go watch it now.
Move In, Move Out
In many application domains, the Producer-Queue-Consumer pattern is used to transport data from input to output within a multi-threaded program:
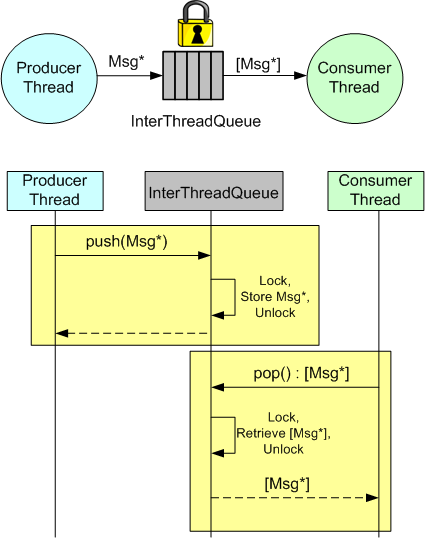
The ProducerThread creates Messages in accordance with the application’s requirements and pushes pointers to them into a lock-protected queue. The ConsumerThread, running asynchronous to the ProducerThread, pops sequences of Message pointers from the queue and processes them accordingly. The ConsumerThread may be notified by the ProducerThread when one or more Messages are available for processing or it can periodically poll the queue.
Instead of passing Message pointers, Message copies can be passed between the threads. However, copying the content can be expensive for large messages.
When using pointers to pass messages between threads, the memory to hold the data content must come from somewhere. One way to provide this memory is to use a Message buffer pool allocated on startup.
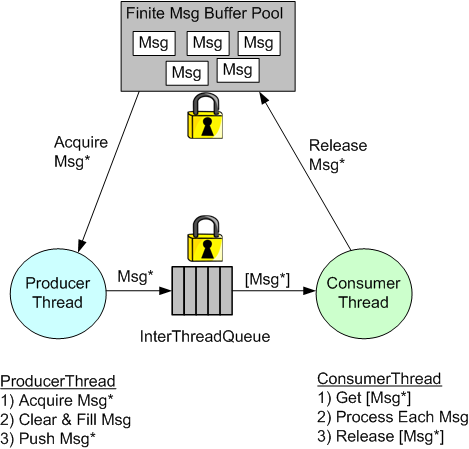
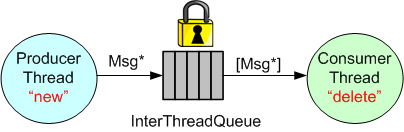
Another, simpler way that avoids the complexity of managing a Message buffer pool, is to manually “new” up the memory in the ProducerThread and then manually “delete” memory in the ConsumerThread.
Since the introduction of smart pointers in C++11, a third way of communicating messages between threads is to “move” std::unique_ptrs into and out of the InterThreadQueue:
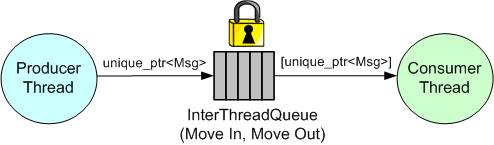
The advantage of using smart pointers is that no “deletes” need to be manually written in the ConsumerThread code.
The following code shows the implementation and usage of a simple InterThreadQueue that moves std::unique_ptrs into and out of a lock protected std::deque.
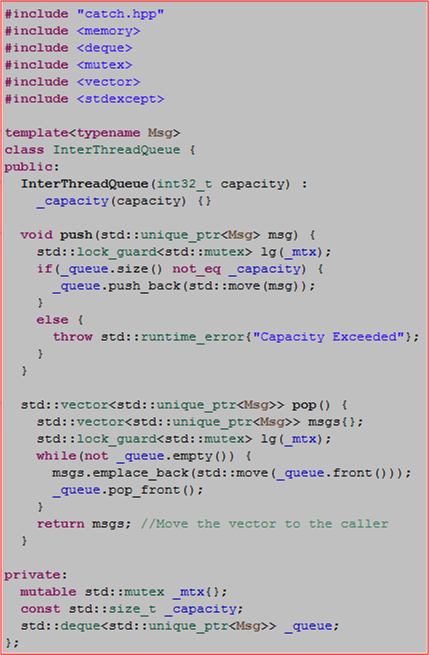
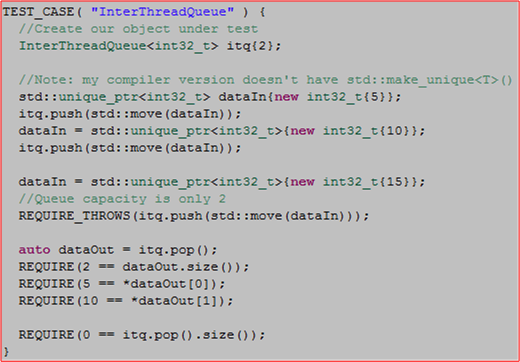
#include "catch.hpp"
#include <memory>
#include <deque>
#include <mutex>
#include <vector>
#include <stdexcept>
template<typename Msg>
class InterThreadQueue {
public:
InterThreadQueue(int32_t capacity) :
_capacity(capacity) {}
void push(std::unique_ptr<Msg> msg) {
std::lock_guard<std::mutex> lg(_mtx);
if(_queue.size() not_eq _capacity) {
_queue.push_back(std::move(msg));
}
else {
throw std::runtime_error{"Capacity Exceeded"};
}
}
std::vector<std::unique_ptr<Msg>> pop() {
std::vector<std::unique_ptr<Msg>> msgs{};
std::lock_guard<std::mutex> lg(_mtx);
while(not _queue.empty()) {
msgs.emplace_back(std::move(_queue.front()));
_queue.pop_front();
}
return msgs; //Move the vector to the caller
}
private:
mutable std::mutex _mtx{};
const std::size_t _capacity;
std::deque<std::unique_ptr<Msg>> _queue;
};
TEST_CASE( "InterThreadQueue" ) {
//Create our object under test
InterThreadQueue<int32_t> itq{2};
//Note: my compiler version doesn't have std::make_unique<T>()
std::unique_ptr<int32_t> dataIn{new int32_t{5}};
itq.push(std::move(dataIn));
dataIn = std::unique_ptr<int32_t>{new int32_t{10}};
itq.push(std::move(dataIn));
dataIn = std::unique_ptr<int32_t>{new int32_t{15}};
//Queue capacity is only 2
REQUIRE_THROWS(itq.push(std::move(dataIn)));
auto dataOut = itq.pop();
REQUIRE(2 == dataOut.size());
REQUIRE(5 == *dataOut[0]);
REQUIRE(10 == *dataOut[1]);
REQUIRE(0 == itq.pop().size());
}
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

