Archive
Native, Managed, Interpreted
Someone asked on Twitter what a “native” app was. I answered with:
“There is no virtual machine or interpreter that a native app runs on. The code compiles directly into machine code.”
I subsequently drew up this little reference diagram that I’d like to share:
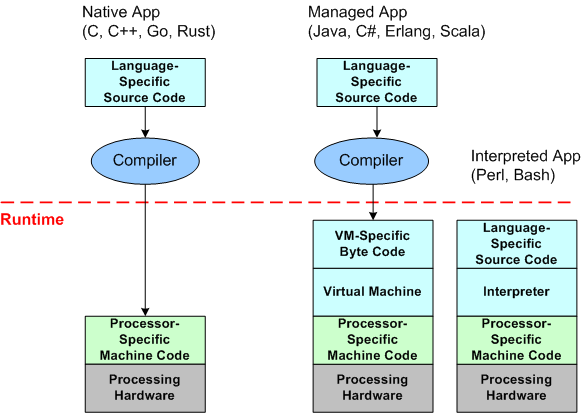
Given the source code for an application written in a native programming language, before you can run it, you must first compile the text into an executable image of raw machine instructions that your “native” device processor(s) know how to execute. After the compilation is complete, you command the operating system to load and run the application program image.
Given the source code for an application written in a “managed” programming language, you must also run the text through a compiler before launching it. However, instead of producing raw machine instructions, the compiler produces an intermediate image comprised of byte code instructions targeted for an abstract, hardware-independent, “virtual” machine. To launch the program, you must command the operating system to load/run the virtual machine image, and you must also command the virtual machine to load/run the byte code image that embodies the application functionality. During runtime, the virtual machine translates the byte code into instructions native to your particular device’s processor(s).
Given the source code for an application written in an “interpreted” programming language, you don’t need to pass it through a compiler before running it. Instead, you must command the operating system to load/run the interpreter, and you must also command the interpreter to load/run the text files that represent the application.
In general, moving from left to right in the above diagram, program execution speed decreases and program memory footprint increases for the different types of applications. A native program does not require a virtual machine or interpreter to be running and “managing” it while it is performing its duty. The tradeoff is that development convenience/productivity generally increases as you move from left to right. For interpreted programs, there is no need for any pre-execution compile step at all. For virtual machine based programs, even though a compile step is required prior to running the program, compilation times for large programs are usually much faster than for equivalent native programs.
Based on what I know, I think that pretty much sums up the differences between native, managed, and interpreted programs. Did I get it right?
Highly Available Systems == Scalable Systems
In this QCon talk: “Building Highly Available Systems In Erlang“, Erlang programming language creator and highly-entertaining speaker Joe Armstrong asserts that if you build a highly available software system, then scalability comes along for “free” with that system. Say what? At first, I wanted to ask Joe what he was smoking, but after reflecting on his assertion and his supporting evidence, I think he’s right.
In his inimitable presentation, Joe postulates that there are 6 properties of Highly Available (HA) systems:
- Isolation (of modules from each other – a module crash can’t crash other modules).
- Concurrency (need at least two computers in the system so that when one crashes, you can fix it while the redundant one keeps on truckin’).
- Failure Detection (in order to fix a failure at its point of origin, you gotta be able to detect it first)
- Fault Identification (need post-failure info that allows you to zero-in on the cause and fix it quickly)
- Live Code Upgrade (for zero downtime, need to be able to hot-swap in code for either evolution or bug fixes)
- Stable Storage (multiple copies of data; distribution to avoid a single point of failure)
By design, all 6 HA rules are directly supported within the Erlang language. No, not in external libraries/frameworks/toolkits, but in the language itself:
- Isolation: Erlang processes are isolated from each other by the VM (Virtual Machine); one process cannot damage another and processes have no shared memory (look, no locks mom!).
- Concurrency: All spawned Erlang processes run in parallel – either virtually on one CPU, or really, on multiple cores and processor nodes.
- Failure Detection: Erlang processes can tell the VM that it wants to detect failures in those processes it spawns. When a parent process spawns a child process, in one line of code it can “link” to the child and be auto-notified by the VM of a crash.
- Fault Identification: In Erlang (out of band) error signals containing error descriptors are propagated to linked parent processes during runtime.
- Live Code Upgrade: Erlang application code can be modified in real-time as it runs (no, it’s not magic!)
- Stable Storage: Erlang contains a highly configurable, comically named database called “mnesia” .
The punch line is that systems composed of entities that are isolated (property 1) and concurrently runnable (property 2) are automatically scalable. Agree?

Firing Up The Eclipse Erlide Plugin
To help me learn and practice writing source code in Erlang, I downloaded and installed the “Erlide” plugin for the Eclipse-Helios IDE. The figure below displays a snapshot of Eclipse with the default Erlang perspective opened up. The set of Erlang specific views that are displayed within the default perspective are: the editor, navigator, process list, and live expressions views. Each Erlang specific view is annotated with this kool little Erlide logo:
![]()

As you can see, the editor is showing the content of the “hello.erl” source code file, which contains the definition of the “hello/0” function. The console view at the bottom of the screen shows the result of manually typing in “hello:hello().“, which runs the program on the version 5.8.2 Erlang virtual machine (VM). Upon completion, the VM did what it was told. It printed, duh, : “Hello World!”.
The complete list of Erlide views available to aspiring Erlang programmers is shown below. Since I’m a newbie to the land of Erlang, I have no freakin’ idea what they do yet.

With the aid of the supplied eclipse Erlide help module (see below), I was easily able to configure and link the IDE to my previously downloaded and installed distribution of the Erlang VM.

The snapshot below shows the configurability options offered up by Erlide via the eclipse “Preferences” window. I won’t go into the details here, but the “Installed runtimes” option is where you connect up Erlide with your installed Erlang VM(s).

So, C++ programmers, what are you waiting for? Download the latest Erlang distro, the Erlide eclipse plugin (you do use eclipse, right?), buy a good Erlang book, and start exploring this powerful and relatively weird programming language.
Oh, and thanks to the great programmers who designed, wrote, and tested the Erlide Eclipse plugin – most likely on their own time. You guys and gals rock!
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

