A Fascinating Conversation
“A Conversation with Bjarne Stroustrup, Carl Hewitt, and Dave Ungar” is the most fascinating technical video I’ve seen in years. The primary focus of the discussion was how to write applications that efficiently leverage multicore processors. Because of the diversity of views, the video is so engrossing that I watched it three times. I also downloaded the MP3 podcast of the discussion and saved it to a USB stick for the drive to/from work.
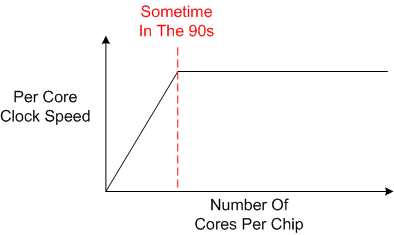
When pure physics started limiting the enormous CPU clock speed gains being achieved in the 90s, vertical scaling came to an abrupt halt and horizontal scaling kicked into gear. The number of cores per processor started going up, and it still is today.
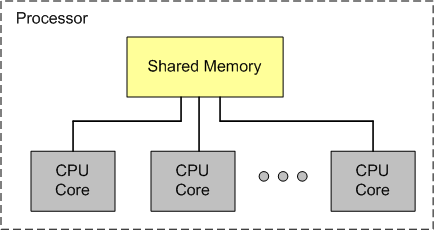
There was much discussion over the difference between a “lock” and “synchronization“. As the figure below illustrates, main memory is physically shared between the cores in a multicore processor. Thus, even if your programming language shields this fact from you by supporting high level, task-based, message passing instead of low-level cooperative threading with locks, some physical form of under-the-hood memory synchronization must be performed in order for the cores to communicate with each other through shared memory without data races.
Here is my layman’s take on each participant’s view of the solution to the multicore efficiency issue:
- Hewitt: We need new, revolutionary, actor-based programming languages that abandon the traditional, sequential Von Neumann model. The current crop of languages just don’t cut it as the number of cores per processor keeps steadily increasing.
- Ungar: We need incoherent, unsynchronized hardware memory architectures with background cache error correction. Build a reliable system out of unreliable parts.
- Stroustrup: Revolutions happen much less than people seem to think. We need to build up and experiment with efficient concurrency abstractions in layered libraries that increasingly hide locks and core-to-memory synchronization details from programmers (the C++ threads-to-tasks-to-“next?” approach).
Leave a comment
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address


I am in the Hewitt school. The reason this is is self evident is how popular GPU/CUDA etc computing became (for solving large numeric problems). This was an unconventional computer architecture that allowed massive parallelism and it kicked the conventional architecture’s butt for many problems.. It’s time for the Harvard Architecture and the Von Neumann bottle neck to die. This requires new creativity in processor design — something like self similar self constructing computing elements where when you new up an Actor its hardware appears out of the computing Ether and is garbage collected when the Actor dies. This would ideally be built on an a quantum computer so that non-deterministic automata algorithms could be exploited.
Well done Phillipe! Did you know that Mike Borden is coming back into the fold? I’m in FL cisiting my dad, but just saw it on linked in.