Archive
C++11 Annoyance Avoiders
I’ve always been torn as to whether or not to annotate derived class member functions intended to override base class members as virtual. Even though it’s unnecessary to do so, I have always preferred to declare them as virtual because it’s just another little reminder to me (besides the colon followed by the base class name at the top of the class definition) that the class I’m coding up is indeed a derived one.
With the introduction of the context-sensitive “override” keyword into C++11, I’ve decided that I’m still going to annotate overriding derived class member functions as a reminder of a class’s derived-ness. However, instead of adorning them with virtual, I’m going to use override instead. Even though they serve basically the same purpose, the compiler uses override to preclude inadvertent hiding of base class member functions that are intended to be overridden.
Assume that the writer of the Derived class below intended to override Base::hiddenFunc(double) but mistakenly wrote Derived::hiddenFunc(int32_t) instead. As you can see from the console output below the code graphic, a loss of precision occurs whenever a user of Derived calls hiddenFunc with a double.
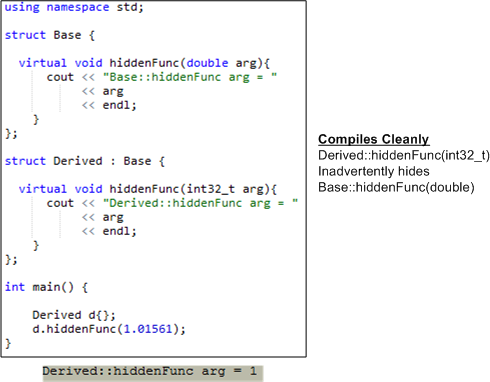
By using override instead of virtual, the potential “gotcha” is avoided. Because the use of override explicity tells the compiler of the programmer’s intention to override, and not hide, Base::hiddenFunc, the code below doesn’t even compile.

C++11 and C++14 provide lots of little, conscientious, “annoyance avoiders” like override (auto, brace initialization, nullptr, lambdas, std::array, smart pointers, etc). Thanks to the benevolent stewardship of Stroustrup/Sutter and the rest of the ISO WG21 C++ committee membership, these little gems make programming in the language more intrinsically rewarding and safer than it is now. If you’re not a hard core anti-C++ zealot, then maybe now is the time time to give the language a try.
No Runtime Overhead
Since I have the privilege of using C++11/14 on my current project, I’ve been using the new language idioms as fast as I can discover and learn them. For example, instead of writing risky, exception-unsafe, naked “new“, code like this:
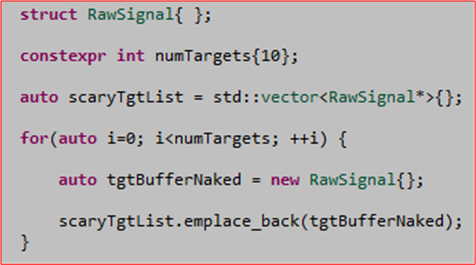
I’ve been writing code like this instead:
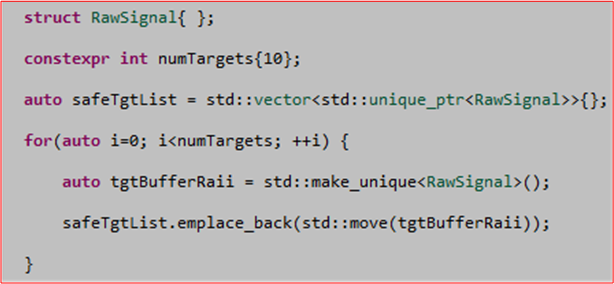
By using std::unique_ptr instead of a naked pointer, I don’t have to veer away from the local code I’m writing to write matching delete statements in destructors or in catch() exception clauses to prevent inadvertent memory leaks.
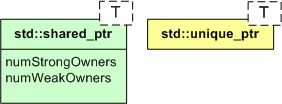
I could’ve used a std::shared_ptr (which can be copied instead of “moved“) in place of the std::unique_ptr, but std::shared_ptr is required to maintain a fatter internal state in the form of strong and weak owner counters. Unless I really need shared ownership of a dynamically allocated object, which I haven’t so far, I stick to the slimmer and more performant std::unique_ptr.
When I first wrote the std::unique_ptr code above, I was concerned that using the std::move() function to transfer encapsulated memory ownership into the safeTgtList vector would add some runtime overhead to the code (relative to the C++98/03 style of simply copying the naked pointer into the scaryTgtList vector). It is, after all, a function, so I thought it must insert some code into my own code.
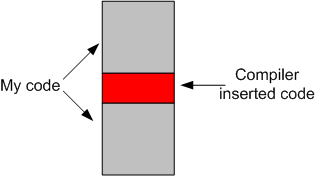
However, after digging a little deeper into my concern, I discovered (via Stroustrup, Sutter, and Meyers) that std::move() adds zero runtime overhead to the code. Its use is equivalent to performing a static_cast on its argument – which is evaluated at compile time.
As Scott Meyers stated at GoingNative13, std::move() doesn’t really move anything. It simply prepares for a subsequent real move by casting its argument from an lvalue to an rvalue – which is required for movement of an object’s innards. In the previous code, the move is actually performed within the std::vector::emplace_back() function.
Quoting Scott Meyers: “think of std::move() as an rvalue_cast“. I’m not sure why the ISO C++ committee didn’t define a new rvalue_cast keyword instead of std::move() to drive home the point that no runtime overhead is imposed, but I’d speculate that the issue was debated. Perhaps they thought rvalue_cast was too technical a term for most users?
Update 10/25/13
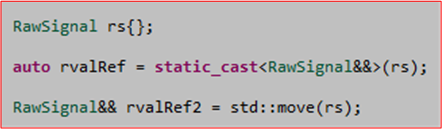
As I said early in the post, the code example is “like” the code I’ve been writing. The real code that triggered this post is as shown here:
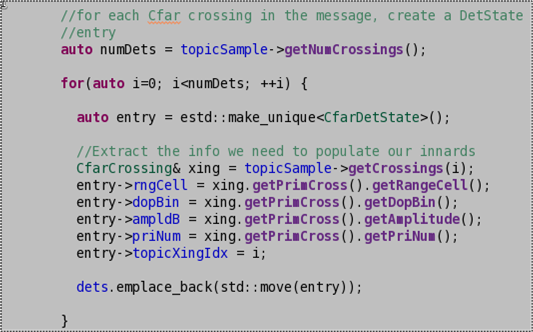
Since each “entry” CfarDetState object must be uniquely intialized form it’s associated CfarCrossing object, I can’t simply insert estd::make_unique<CfarDetState>() into the emplace_back() function. All of the members of each “entry” must be initialized first. Regardless of whether I use emplace_back() or push_back(), std::move(entry) must be used as the argument of the chosen function.
The Biggest Cheerleader
Herb Sutter is by far the biggest cheerleader for the C++ programming language – even more so than the language’s soft spoken creator, Bjarne Stroustrup. Herb speaks with such enthusiasm and optimism that it’s infectious.

In his talk at the recently concluded GoingNative2013 C++ conference, Herb presented this slide to convey the structure of the ISO C++ Working Group 21 (WG21):

On the left, we have the language core and language evolution working groups. On the right, we have the standard library working group.
But wait! That was the organizational structure as of 18 months ago. As of now, we have this decomposition:

As you can see, there’s a lot of volunteer effort being applied to the evolution of the language – especially in the domain of libraries. In fact, most of the core language features on the left side exist to support the development of the upcoming libraries on the right.
In addition to the forthcoming minor 2014 release of C++, which adds a handful of new features and fixes some bugs/omissions from C++11, the next major release is slated for 2017. Of course, we won’t get all of the features and libraries enumerated on the slide, but the future looks bright for C++.
The biggest challenge for Herb et al will be to ensure the conceptual integrity of the language as a whole remains intact in spite of the ambitious growth plan. The faster the growth, the higher the chance of the wheels falling off the bus.
“The entire system also must have conceptual integrity, and that requires a system architect to design it all, from the top down.” – Fred Brooks
“Who advocates … for the product itself—its conceptual integrity, its efficiency, its economy, its robustness? Often, no one.” – Fred Brooks
I’m not a fan of committees in general, but in this specific case I’m confident that Herb, Bjarne, and their fellow WG21 friends can pull it off. I think they did a great job on C++11 and I think they’ll perform just as admirably in hatching future C++ releases.
It’s Definitely A Compiler Bug
Previously, I wrote a post about a potential compiler bug with the g++ compiler in the GCC 4.7.2 collection that was driving me nutz: “Uniform Initialization Failure?“. In that post, I flip-flopped between concluding whether the issue I stumbled upon was a bug or just another one of those C++ quirks that cause newbie programmers to flee in droves toward the easier-to-learn programming languages. D’oh!
Since I wrote that post, I’ve purchased and have been studying the fourth edition of Bjarne’s TCPPL. It’s now a slam dunk. The g++ GCC 4.7.2 compiler does indeed have a bug in its implementation of C++11’s uniform initialization feature.
First, consider this Stroustrup code snippet:

Note how Bjarne “uniformly” uses braces to initialize all of class X‘s member variables – including the Club reference member variable, rc.
Next, look at the code I wrote that makes g++ 4.7.2 barf:

Note how the compiler spewed blasphemy when I tried to uniformly use braces to initialize the GccBug class’s foo and bar member variables.
Now, look at what I had to do to make the almighty compiler happy:

As you can see, I had to destroy the elegancy of uniform initialization by employing a mix of braces and old-style parenthesis to initialize the foo and bar member variables.
It’s my understanding that GCC 4.8.2 has been released and it has been deemed C++11 feature-complete. I currently don’t have it installed, but, if one of you dear readers are using it, can you please experiment with it and determine if the bug has been squashed? I have a highly coveted BD00 T-shirt waiting in the warehouse for the first person who reports back with the result.
The Current Crop
There are a bazillion books on C++03 out in the wild. However, even though there are lots of pieces of C++11 material available for consumption online, there are (AFAIK) only 6 C++11 books currently available:

Lucky BD00. He has 24 X 7 e-access to all of these tomes through his Safari Books Online membership.
Note that even though he has some C++11/14 training material available for purchase on his web site, none of Scott Meyers‘ “Effective” series of C++ books has been updated yet. Fear not. The first in the series, “Effective C++11/14“, is coming to market in early 2014. The description of Scott’s upcoming GoingNative 2013 session, titled “An Effective C++11/14 Sampler“, reads as follows:
After years of intensive study (first of C++0x, then of C++11, and most recently of C++14), Scott thinks he finally has a clue. About the effective use of C++11, that is (including C++14 revisions). At last year’s Going Native, Herb Sutter predicted that Scott would produce a new version of Effective C++ in the 2013-14 time frame, and Scott’s working on proving him almost right. Rather than revise Effective C++, Scott decided to write a new book that focuses exclusively on C++11/14: on the things the experts almost always do (or almost always avoid doing) to produce clear, efficient, effective code. In this presentation, Scott will present a taste of the Items he expects to include in Effective C++11/14. If all goes as planned, he’ll also solicit your help in choosing a cover for the book.
It’s about time that Scott got a clue. 🙂
Don’t Panic!
The fourth edition of “The C++ Programming Language” weighs in at 1346 pages and 44 chapters allocated over four partitions. The end of each chapter provides a list of advisory items – yielding a grand total of 699 nuggets of general programming and C++ specific wisdom for the reader to ponder.

The figure below shows a breakdown of the behemoth book’s table of contents. The number of advisories provided in each chapter and each partition are shown on the right side.

As a temporary excursion from reading and studying and writing exploratory snippets of C++11 code, I went through all 699 items and plucked out a subset of the tidbits I found most useful. Of course, your personal list would no doubt turn out differently.

Even though it’s not on my list, my absolute favorite item of advice is the first one presented at the end of chapter 2:

D’oh! Wanna guess at how much time is needed for all to become clear? Maybe Malcolm Gladwell‘s famous “10,000 hours” isn’t enough? But that’s why I love C++. It provides an endlessly rich and deep opportunity for learning.
The Point Of No Return
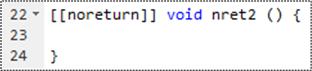
As part of learning the new feature set in C++11, I stumbled upon the weird syntax for the new “attribute” feature: [[ ]]. One of these new C++11 attributes is [[noreturn]].
The [[noreturn]] attribute tells the compiler that the function you are writing will not return control of execution back to its caller – ever. For example, this function will generate a compiler warning or error because even though it returns no value, it does return execution control back to its caller:
![]()
The following functions, however, will compile cleanly:

Using [[noreturn]] enables compiler writers to perform optimizations that would otherwise not be available without the attribute. For example, it can silently (but correctly) eliminate the unreachable call to fnReturns() in this snippet:

Note: I used the Coliru interactive online C++ IDE to experiment with the [[noreturn]] attribute. It’s perfect for running quick and dirty learning experiments like this.
The Importance Of Locality
Since I love the programming language he created and I’m a fan of his personal philosophy, I’m always on the lookout for interviews of Bjarne Stroustrup. As far as I can tell, the most recent one is captured here: “An Interview with Bjarne Stroustrup | | InformIT“. Of course, since the new C++11 version of his classic TC++PL book is now available, the interview focuses on the major benefits of the new set of C++11 language features.

For your viewing pleasure and retention in my archives, I’ve clipped some juicy tidbits from the interview and placed them here:
Adding move semantics is a game changer for resource (memory, locks, file handles, threads, and sockets) management. It completes what was started with constructor/destructor pairs. The importance of move semantics is that we can basically eliminate complicated and error-prone explicit use of pointers and new/delete in most code.
TC++PL4 is not simply a list of features. I try hard to show how to use the new features in combination. C++11 is a synthesis that supports more elegant and efficient programming styles.
I do not consider it the job of a programming language to be “secure.” Security is a systems property and a language that is – among other things – a systems programming language cannot provide that by itself.
The repeated failures of languages that did promise security (e.g. Java), demonstrates that C++’s more modest promises are reasonable. Trying to address security problems by having every programmer in every language insert the right run-times checks in the code is expensive and doomed to failure.
Basically, C is not the best subset of C++ to learn first. The “C first” approach forces students to focus on workarounds to compensate for weaknesses and a basic level of language that is too low for much programming.
Every powerful new feature will be overused until programmers settle on a set of effective techniques and find which uses impede maintenance and performance.
I consider Garbage Collection (GC) the last alternative after cleaner, more general, and better localized alternatives to resource management have been exhausted. GC is fundamentally a global memory management scheme. Clever implementations can compensate, but some of us remember too well when 63 processors of a top-end machine were idle when 1 processor cleaned up the garbage for them all. With clusters, multi-cores, NUMA memories, and multi-level caches, systems are getting more distributed and locality is more important than ever.

make_unique
On my current project, we’re joyfully using C++11 to write our computationally-dense target processing software. We’ve found that std::shared_ptr and std::unique_ptr are extremely useful classes for avoiding dreaded memory leaks. However, I find it mildly irritating that there is no std::make_unique to complement std::make_shared. It’s great that std::make_unique will be included in the C++14 standard, but whenever we use a std::unique_ptr we gotta include a fugly “new” in our C++11 code until then:
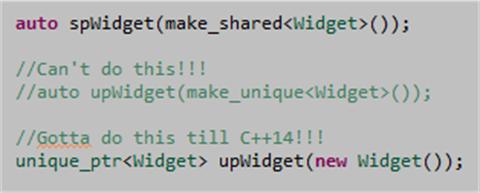
But wait! I stumbled across this helpful Herb Sutter slide:

A variadic function template that uses perfect forwarding. It’s outta my league, but….. Whoo Hoo! I’m gonna add this sucker to our platform library and start using it ASAP.
Our Stack
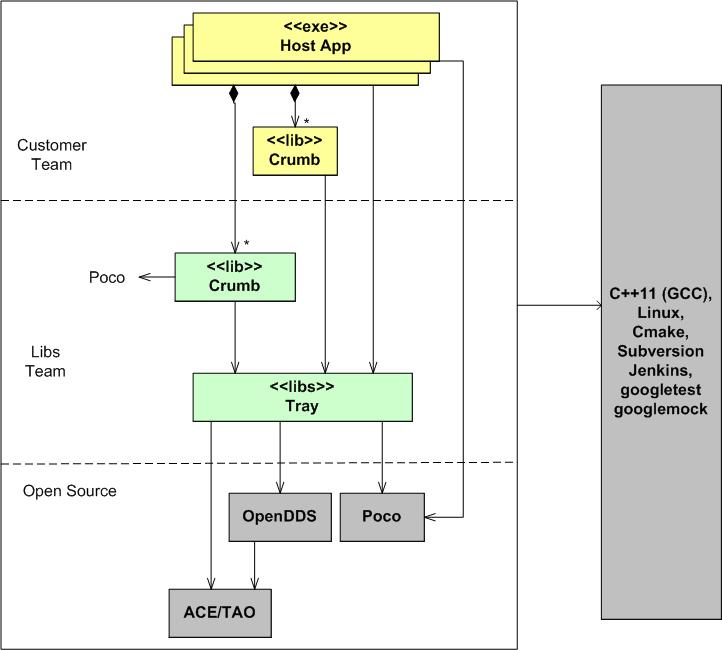
The figure below shows a layered view of the latest distributed system product that I’m working on. Customer teams compose their applications by writing their own system-specific Crumbs and linking them with our pre-written, pre-tested Crumbs. In the ideal case, customers don’t have to write a single line of Crumb code. They simply compose, compile, link, configure, and deploy an amalgamation of our off-the-shelf Crumbs as a set of application components that meets their needs.
Note that we are using C++11 to build the system. Also note the third party, open source libraries that we are building upon. Except for Poco, Crumb developers don’t directly use the OpenDDS or ACE/TAO APIs. Our Crumb “Tray” serves as a wrapper/facade that hides the complexity those inter-process communication facilities.
My role on the development team is as a Libs team “Crumb” designer/writer. If I gave you anymore product views or disclosed anything more concrete, then I’d either get fired or I’d have to kill you, or both.
What are you currently working on?
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

