Archive
The Point Of No Return
As part of learning the new feature set in C++11, I stumbled upon the weird syntax for the new “attribute” feature: [[ ]]. One of these new C++11 attributes is [[noreturn]].
The [[noreturn]] attribute tells the compiler that the function you are writing will not return control of execution back to its caller – ever. For example, this function will generate a compiler warning or error because even though it returns no value, it does return execution control back to its caller:
![]()
The following functions, however, will compile cleanly:

Using [[noreturn]] enables compiler writers to perform optimizations that would otherwise not be available without the attribute. For example, it can silently (but correctly) eliminate the unreachable call to fnReturns() in this snippet:

Note: I used the Coliru interactive online C++ IDE to experiment with the [[noreturn]] attribute. It’s perfect for running quick and dirty learning experiments like this.
A Bureaucrat’s Dream
Thanks to powerful, vested interests and ignorant leadership, some stodgy dinosaur orgs still cling to a bevy of high-falutin’, delay-inducing, product conception/development/maintenance processes. Because of the strong nuclear forces in place, it’s virtually impossible to change these labyrinthian processes – despite those noble “continuous improvement” initiatives that are seemingly promoted 24X7.
The state transition diagram below models a hypothetical schedule and budget busting maintenance process. But beware! Since BD00 likes to make sh*t up, the 5 role, 12 step, bureaucrat’s dream is a totally contorted fabrication that has no semblance to the truth.

Of course, some classes of discovered product defects should indeed be run through the ringer so that they don’t happen again. But mindlessly requiring every single defect (e.g. a low risk, one-line code change?, formatting violation?, documentation typo?) to plod through the glorious process is akin to using brain surgery to cure a headache.
Many of these process worshipping orgs can save a ton of time, money, and frustration if they “allowed” a parallel JFTDT process for those simple, low risk, defects discovered during and after a product is developed.

But no! In zombie orgs that have these types of beloved processes in place, it can’t be done. Despite the unsubstantiated and outrageous BD00 claim that the vast majority of discovered defects in most projects can be safely run through the insanely simple JFTDT process, anyone who’s not the CEO that thinks of advocating for a parallel, streamlined process should think twice. No one wants to be the next dude who gets shoved through the hidden JSTFU process.
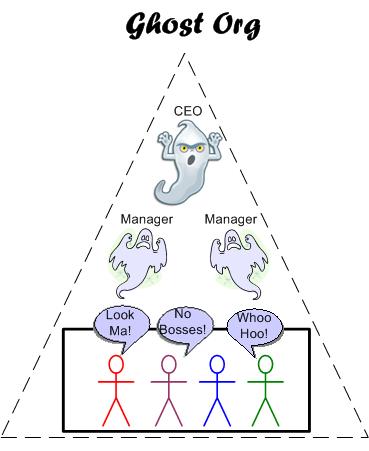
Ghost Org
After discovering Valve Inc. earlier this year, I wrote several posts (here and here and here) praising their flat organizational structure and unique management practices. Well, as the saying goes, “nothing ever is as it seems“.
In February, Valve laid off a group of hardware designers and one of them has spoken out against the company. Jeri Ellsworth, the former head of Valve’s hardware division, is that person:

In a podcast interview, Jeri said the following unflattering things about the company:
There is actually a hidden layer of powerful management structure in the company, and it felt a lot like High School. There are popular kids that have acquired power, then there’s the trouble makers, and then everyone in between. Everyone in between is ok, but the trouble makers are the ones trying to make a difference.
Now we’ve all seen the Valve handbook, which offers a very idealized view. A lot of that is true. It is a pseudo-flat structure, where in small groups at least in small groups you are all peers and make decisions together.
Their structure probably works really well with about 20 people, but breaks down terribly when you get to a company of 300 people. Communication was a problem. I don’t think it works.
They have a bonus structure in there where you can get bonuses – if you work on very prestigious projects – that are more than what you earn. So everyone is trying to work on projects that are really visible. And it’s impossible to pull those people away for something risky like augmented reality because they only want to work on the sure thing. So that was a frustration, we were starved for resources. And I probably was [abrasive] but I just couldn’t find a way to make a process to actually deliver any hardware inside that company.
If I sound bitter, it’s because I am. I am really, really bitter. They promised me the world and then stabbed me in the back.
Despite my naivete and gullibility, I originally thought that Valve was an exemplar case. With over 300 employees, they seemingly proved that flatness and egalitarianism can scale. It seemed magical. But sigh, according to Jeri, who admittedly is only one data point, it doesn’t.
In light of this sad, new information, I no longer think flatness scales. At a certain (but unknown) size, hierarchy is required for sustained economic viability in for-profit enterprises. When you arrive at the (unknown) size where you need a hierarchy, tis better to have a visible, transparent pyramid than a hidden, privileged one.
The trouble with unwritten rules is that you don’t know where to go to erase them. – Unknown
I’m glad to be part of an org with a visible hierarchy instead of an invisible one. At least I know who to suck up to (which I do well) and who not to piss off (which I don’t do well).
Hierarchy will never go away, never. – Tom Peters
Components, Namespaces, Libraries

Regardless of which methodology you use to develop software, the following technical allocation chain must occur to arrive at working source code from some form of requirements:

The figure below shows a 2/6/13 end result of the allocation chain for a hypothetical example project. How the 2/6/13 combo was arrived at is person and domain-specific. Given the same set of requirements to N different, domain-knowledgeable people, N different designs will no doubt be generated. Person A may create a 3/6/9 design and person B may conjure up 4/8/16 design.

Given a set of static or evolving requirements, how should one allocate components to namespaces and libraries? The figure below shows extreme 1/1/13 and 13/13/13 cases for our hypothetical 13 component example.
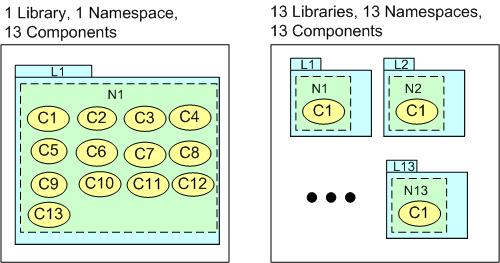
As the number of components, N, in the system design gets larger, the mindless N/N/N strategy becomes unscalable because of an increasing dependency management nightmare. In addition to deciding which K logical components to use in their application, library users must link all K physical libraries with their application code. In the mindless 1/1/N strategy, only one library must be linked with the application code, but because of the single namespace, the design may be harder to logically comprehend.
Expectedly, the solution to the allocation problem lies somewhere in between the two extremes. Arriving at an elegant architecture/design requires a proactive effort with some upfront design thinking. Domain knowledge and skillful application of the coupling-cohesion heuristic can do the trick. For large scale systems, letting a design emerge won’t.
Emergent design works in nature because evolution has had the luxury of millions of years to get it “right“. Even so, according to angry atheist Richard Dawkins, approximately 99% of all “deployed” species have gone extinct – that’s a lot of failed projects. In software development efforts, we don’t have the luxury of million year schedules or the patience for endless, random tinkering.
Burn Baby Burn
The “time-boxed sprint” is one of the star features of the Scrum product development process framework. During each sprint planning meeting, the team estimates how much work from the product backlog can be accomplished within a fixed amount of time, say, 2 or 4 weeks. The team then proceeds to do the work and subsequently demonstrate the results it has achieved at the end of the sprint.
As a fine means of monitoring/controlling the work done while a sprint is in progress, some teams use an incarnation of a Burn Down Chart (BDC). The BDC records the backlog items on the ordinate axis, time on the abscissa axis, and progress within the chart area.
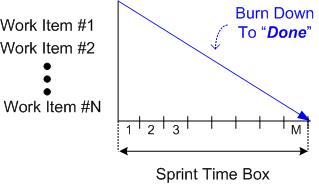
The figure below shows the state of a BDC just prior to commencing a sprint. A set of product backlog items have been somehow allocated to the sprint and the “time to complete” each work item has been estimated (Est. E1, E2….).
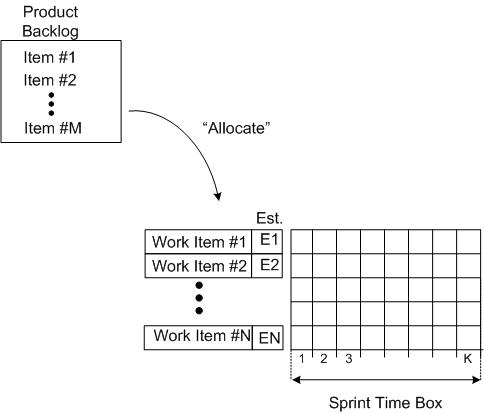
At the end of the sprint, all of the tasks should have magically burned down to zero and the BDC should look like this:
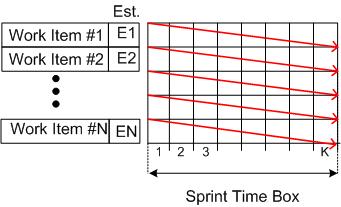 So, other than the shortened time frame, what’s the difference between an “agile” BDC and the hated, waterfall-esque, Gannt chart? Also, how is managing by burn down progress any different than the hated, traditional, Earned Value Management (EVM) system?
So, other than the shortened time frame, what’s the difference between an “agile” BDC and the hated, waterfall-esque, Gannt chart? Also, how is managing by burn down progress any different than the hated, traditional, Earned Value Management (EVM) system?
I love deadlines. I like the whooshing sound they make as they fly by – Douglas Adams
In practice, which of the outcomes below would you expect to see most, if not all, of the time? Why?

We need to estimate how many people we need, how much time, and how much money. Then we’ll know when we’re running late and we can, um, do something.
Usain Taylor
Since I love zombie movies, I recently watched the 3D version of “World War Z“. Similar to the brilliantly made “28 days Later” and “28 Months later” movies, the zombie dudes in WWZ are fast movers – undead versions of Usain Bolt with the tackling expertise of Lawrence Taylor and the chomping skill of Dracula.

I think this new twist on the zombie genre makes these movies much more exciting and suspenseful. You never freakin’ know when Usain Taylor is gonna explode out of nowhere and take a Shylockian pound of flesh out of your gut/butt/face/neck/arm/leg.
George Romero, who directed the most famous and beloved zombie movie ever made, “The Night Of The Living Dead“, doesn’t like the cinematic transition from lumbering hunks to agile bullets:
If zombies are dead, how can they move fast? – George Romero
Geez George. If you’re gonna bring logic into play, then:
If zombies are dead, how can they move at all? – BZ00

Fluency And Maturity
After reading about Martin Fowler‘s “levels of agile fluency”, I decided to do a side-by-side exploration of his four levels of fluency with the famous (infamous?) five “levels of CMMI maturity“:
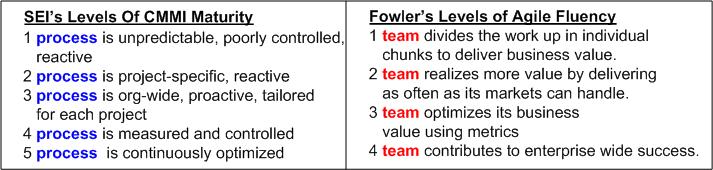
As you can easily deduce, the first difference that I noticed was that
The SEI focuses on the process. Fowler focuses on the team of people.
Next, I noticed:
To the SEI, “proactive” is good and “reactive” is bad. Proactive vs. reactive seems to be a “don’t care” to Fowler.
The SEI emphasizes the attainment of “control“. Fowler emphasizes the attainment of “business value“.
While writing this post, I really wanted to veer off into a rant demonizing the SEI list for being so mechanistically Newtonian. However, I stepped back, decided to take the high road, and formed the following meta-conclusion:
The SEI & Fowler lists aren’t necessarily diametrically opposed.
Perhaps the nine levels can be intelligently merged into a brilliant hybrid that balances both people and process (like the Boehm/Turner attempt).
What do you think? Is the side-by-side comparison fair, or is it an apple & oranges monstrosity?
Slack Time
The best resource on the importance of “slack time” is Tom DeMarco‘s aptly titled book, “Slack: Getting Past Burnout, Busywork, and the Myth of Total Efficiency“. (I’ve loved everything Mr. DeMarco has produced since the 80’s.)

I’ve worked on projects where I had a lot of slack time available that allowed me to interlace learning with doing. I’ve also worked on projects where I was balls-to-the-wall; solely “doing” for the entire duration. While on the former, I felt grateful to be able to kill two birds with one stone. While on the latter, I felt angry at having no time for personal development.
Having too much slack time available on a project is certainly inefficient. It can lead to boredom and a guilty feeling of “not contributing” to the org. On the other hand, having no time to breathe can lead to unnecessary mistakes, corner-cutting, and an angry feeling of being exploited – especially if you perceive other teams as having too much slack time available.

Successfully Pulling Off A “Snowden”
BD00 just finished reading this FastCompany.com article: “How To Whistleblow Like Edward Snowden Without Blowing Your Career”.
After reading the lame suggestions on how to successfully pull off a “Snowden” without getting your head chopped off, BD00 laughed his arse off when he spied the last sentence in the treatise:
Courts rarely side with whistle-blowers, despite considerable legal changes to aid the ethical ones.
That one single sentence trumped all the other sage advice previously proffered forth. To generalize further and make the factful quote scarier, simply replace the word “Courts” with “Those in authority“. And yes, this most likely includes the chain of command at your org, starting with your boss and moving upward.
Unless you harbor the insane delusion of becoming the next Erin Brockovich, BD00 recommends a STFU policy for all you disloyal ingrates out there.
You are assuming that the recipient of your information knows how to handle it in a way that doesn’t burn you – rarely is that the case.

Kudos To mttd
An indication that you’re improving as a blogger is if someone posts a link to one of your blog posts on Reddit.com. Some kind soul that goes by the Reddit handle of “mttd” actually did that for BD00 (thanks!).
The graphic below shows the relative spike in traffic that resulted from “mttd” acting as my benefactor. He/she posted a link to my June 1st “Agile Overload” post. Of course, the “what have you done for me lately” effect soon prevailed and traffic returned to normal shortly thereafter.

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

