Archive
Tickled Pink
Since I’m a fan of DDS, I was tickled pink to see this newsletter appear in my mailbox:
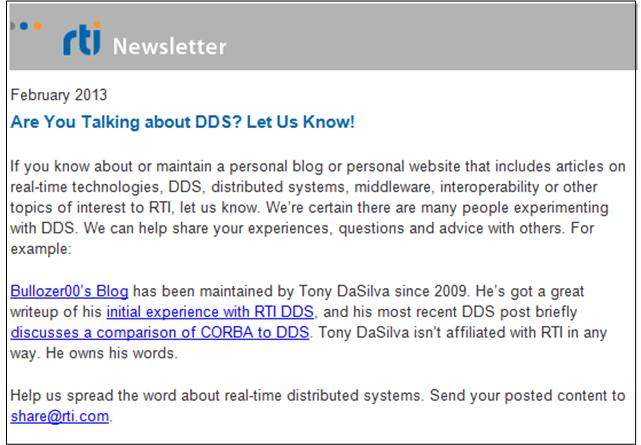
Since the above graphic is a bitmap, clicking on the links won’t work. In case you do want to read the linked-to pages, here they are:
Message-Centric Vs. Data-Centric
The slide below, plagiarized from a recent webinar presented by RTI Inc’s CEO Stan Schneider, shows the evolution of distributed system middleware over the years.

At first, I couldn’t understand the difference between the message-centric pub-sub (MCPS) and data-centric pub-sub (DCPS) patterns. I thought the difference between them was trivial, superficial, and unimportant. However, as Stan’s webinar unfolded, I sloowly started to “get it“.
In MCPS, application tier messages are opaque to to the middleware (MW). The separation of concerns between the app and MW tiers is clean and simple:

In DCPS systems, app tier messages are transparent to the MW tier – which blurs the line between the two layers and violates the “ideal” separation of concerns tenet of layered software system design. Because of this difference, the term “message” is superceded in DCPS-based technologies (like the OMG‘s DDS) by the term “topic“. The entity formerly known as a “message” is now defined as a topic sample.

Unlike MCPS MW, DCPS MW supports being “told” by the app tier pub-sub components which Quality Of Service (QoS) parameters are important to each of them. For example, a publisher can “promise” to send topic samples at a minimum rate and/or whether it will use a best-effort UDP-like or reliable TCP-like protocol for transport. On the receive side, a subscriber can tell the MW that it only wants to see every third topic sample and/or only those samples in which certain data-field-filtering criteria are met. DCPS MW technologies like DDS support a rich set of QoS parameters that are usually hard-coded and frozen into MCPS MW – if they’re supported at all.

With smart, QoS-aware DCPS MW, app components tend to be leaner and take less time to develop because the tedious logic that implements the QoS functionality is pushed down into the MW. The app simply specifies these behaviors to the MW during launch and it gets notified by the MW during operation when QoS requirements aren’t being, or can’t be, met.

The cost of switching from an MCPS to a DCPS-based distributed system design approach is the increased upfront, one-time, learning curve (or more likely, the “unlearning” curve).
Related articles
OMG! Design By Committee
In Federico Biancuzzi’s terrific “Masterminds Of Programming“, Federico interviews the three Amigo co-creators of UML. In discussing the “advancement” of the UML after the Amigos freely donated their work to the OMG for further development, Jim Rumbaugh had this to say:
The OMG (Object Management Group) is a case study in how political meddling can damage any good idea. The first version of UML was simple enough, because people didn’t have time to add a lot of clutter. Its main fault was an inconsistent viewpoint—some things were pretty high-level and others were closely aligned to particular programming languages. That’s what the second version should have cleared up. Unfortunately, a lot of people who were jealous of our initial success got involved in the second version. – Jim Rumbaugh
LOL! Following up, Jim landed a second blow:
The OMG process allowed all kinds of special interests to stuff things into UML 2.0, and since the process is mainly based on consensus, it is almost impossible to kill bad ideas. So UML 2.0 became a bloated monstrosity, with far too much dubious content, and still no consistent viewpoint and no way to define one. – Jim Rumbaugh
Double LOL!
Another UML co-creator, Grady Booch, says essentially the same thing but without specifically mentioning the OMG cabal:
UML 2.0 to some degree, and I’ll say this a little bit harshly, suffered a bit of a second system effect in that there were great opportunities and special interest groups, if you will, clamoring for certain specific features which added to the bloat of UML 2.0. – Grady Booch
Triple LOL!
Mitchi Henning, a key player during the CORBA era, rants about the OMG in this controversial “The Rise And Fall Of CORBA” article. Mitchi enraged the corbaholic community by lambasting both CORBA and the dysfunctional OMG politburo that maintains it:
Over the span of a few years, CORBA moved from being a successful middleware that was hailed as the Internet’s next-generation e-commerce infrastructure to being an obscure niche technology that is all but forgotten. This rapid decline is surprising. How can a technology that was produced by the world’s largest software consortium fall from grace so quickly? Many of the reasons are technical: poor architecture, complex APIs, and lack of essential features all contributed to CORBA’s downfall. However, such technical shortcomings are a symptom rather than a cause. Ultimately, CORBA failed because its standardization process virtually guarantees poor technical quality. Seeing that other standards consortia use a process that is very similar, this does not bode well for the viability of other technologies produced in this fashion. – Mitchi Henning
Maybe the kings and queens of the OMG should add an exclamation point to the end of their acronym: OMG!
The reason the OMG! junta interests me is because I’ve been working hands-on with RTI‘s implementation of the OMG Data Distribution Service (DDS) standard to design and build the infrastructure for a distributed sensor data processing server that will be embedded in a safety-critical supersystem. At this point in time, since DDS was co-designed, tested, and fielded by two commercial companies and it wasn’t designed from scratch by a big OMG committee, I think it’s a terrific standard. Particularly, I think RTI’s version is spectacular relative to the other two implementations that I know about. I hope the OMG! doesn’t transform DDS into an abomination………

Communication Layer Performance Benchmarking
Along with two outstanding and dedicated peers, I’m currently designing and writing (in C++) a large, distributed, multi-process, multi-threaded, scalable, real-time, sensor software system. Phew, that’s a lot of “see how smart I am” techno-jargon, no?
Since the performance and reliability of the underlying Inter-Process Communication (IPC) layer is critical to meeting our customer’s end-to-end system latency and throughput requirements, we decided to measure the performance of three different IPC candidates:
- Real Time Innovations Inc.’s implementation of the Object Management Group’s Data Distribution Service (DDS) standard
- The Apache Software Foundation’s ActiveMQ implementation of the Java Messaging System (JMS) standard
- A homegrown brew built on top of the Boost Organization‘s Asio (Asychronous input output) portable C++ library.
The figure below shows the average CPU load vs throughput performance of the three distributed system messaging communication candidates. Notice that the centralized broker-based JMS approach yielded horrendous relative results.
Transmit batching, along with a whole bevy of “free” (to application layer programmers) tunable features in RTI’s DDS, consists of aggregating a bunch of application layer messages into one network packet to increase the throughput (at the expense of increased latency). Since batching isn’t available in AMQ JMS or our “homegrown” Boost.Asio comm layer candidate, only the DDS performance increase is shown on the graph.

Measurement Approach
One way to measure the CPU load imposed on a processor node by an IPC layer candidate in a data streaming, real-time, system is to quantize time into discrete slices and measure the per slice processing time that it takes to send a fixed number of messages out via the comm software stack. Since other non-deterministic OS runtime functionality shares the CPU with the application processes and the comm software stack, measuring and averaging the normalized CPU time across a large number of slices can give some quantitative feel for the load imposed on the processor.
The figure below shows the approach that was taken to measure the CPU load versus throughput performance of the three communication layer candidates. To implement this strategy, I wrote a small C++ test application that is designed to operate in a time sliced mode, where the time slice size (default = 50 msecs) is user selectable via the command line.

During runtime, the test app generates and publishes a stream of “canned” messages at a user specified rate and for a user-defined test run duration. Upon the start of each time slice, the current time is “grabbed” and stored for later use. At the end of each tight, K-message, generate-and-publish loop, the end time is retrieved from the OS and then the percent CPU load for the slice is calculated in accordance with the simple equations below. At the end of the test run, the first 1000 sample points are averaged, and the result, along with the max and min loads measured during the run are printed to the console and a date stamped log file.
 Of course, to ensure that the comm layer candidate wasn’t dropping or corrupting application messages during test runs, I wrote a subscriber app to provide a “resistor load” on the performance measuring publisher app process. By comparing the number and integrity of messages received to the number and integrity of those transmitted, the measurements were given higher credibility. The figure below shows the test fixtures that I ran the performance tests on. For the AMQ JMS candidate, a broker process was running along side of the app processes, but his single-point-of-failure component is not shown in the diagram.
Of course, to ensure that the comm layer candidate wasn’t dropping or corrupting application messages during test runs, I wrote a subscriber app to provide a “resistor load” on the performance measuring publisher app process. By comparing the number and integrity of messages received to the number and integrity of those transmitted, the measurements were given higher credibility. The figure below shows the test fixtures that I ran the performance tests on. For the AMQ JMS candidate, a broker process was running along side of the app processes, but his single-point-of-failure component is not shown in the diagram.

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

