Archive
Tickled Pink
Since I’m a fan of DDS, I was tickled pink to see this newsletter appear in my mailbox:
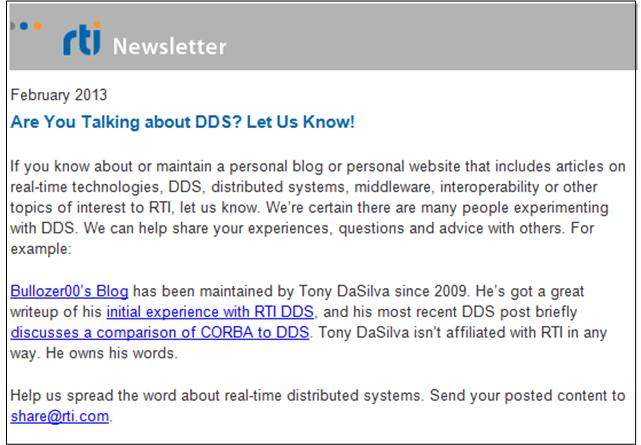
Since the above graphic is a bitmap, clicking on the links won’t work. In case you do want to read the linked-to pages, here they are:
Not Either, But Both?
I recently dug up an old DDS tutorial pitch by distributed system middleware expert extraordinaire, Doug Schmidt. The last slide in the pitch shows a side-by-side, high-level feature comparison of CORBA and DDS:

High performance middleware technologies like CORBA and DDS are big, necessarily complex beasts that have high learning curves. Thus, I’m not so sure I agree with Doug’s assessment that complex software systems (like sensor-based command and control systems) need both. One can build a pub-sub mechanism on top of CORBA (using the notification, event, or messaging services) and one can build a client-server, request-response mechanism on top of DDS (using the TCP/IP-like “reliability” QoS). What do you think about the tradeoff? Fill the holes yourself with a tad of home-grown infrastructure code, or use both and create a two-headed, fire-breathing dragon?

World Class Help
I’m currently transitioning from one software project to another. After two years of working on a product from the ground up, I will be adding enhancements to a legacy system for an existing customer.
The table below shows the software technologies embedded within each of the products. Note that the only common attribute in the table is C++, which, thank god, I’m very proficient at. Since ACE, CORBA, and MFC have big, complicated, “funky” APIs with steep learning curves, it’s a good thing that “training” time is covered in the schedule as required by our people-centric process. 🙂
![]()
I’m not too thrilled or motivated at having to spin up and learn ACE and CORBA, which (IMHO) have had their 15 minutes of fame and have faded into history, but hey, all businesses require maintenance of old technologies until product replacement or retirement.
I am, however, delighted to have limited e-access to LinkedIn connection Steve Vinoski. Steve is a world class expert in CORBA know-how who’s co-authored (with Michi Henning) the most popular C++ CORBA programming book on the planet:

Even though Steve has moved on (C++ -> Erlang, CORBA -> REST), he’s been gracious enough to answer some basic beginner CORBA questions from me without requiring a consulting contract 🙂 Thanks for your generosity Steve!
A Role Model For Change
In the comments section of the Horse And Buggy post, Steve Vinoski was gracious enough to provide links to four IEEE Computer Society columns that he wrote a few years ago on the topic of distributed software systems. For your viewing pleasure, I’ve re-listed them here:
http://steve.vinoski.net/pdf/IEEE-Serendipitous Reuse.pdf
http://steve.vinoski.net/pdf/IEEE-Demystifying_RESTful_Data_Coupling.pdf
http://steve.vinoski.net/pdf/IEEE-Convenience_Over_Correctness.pdf
http://steve.vinoski.net/pdf/IEEE-RPC_and_REST_Dilemma_Disruption_and_Displacement.pdf
Of course, being a Vinoski fan, I read them all. If you choose to read them, and you’re not an RPC (Remote Procedure Call) zealot, I think you’ll enjoy them as much as I did. To view and learn more about distributed software system design from a bunch of Steve Vinoski video interviews, check out the collection of them at InfoQ.com.
I really admire Steve because he made a major leap out of his comfort zone into a brave new world. He transitioned from being a top notch CORBA and C++ proponent to being a REST and Erlang advocate. I think what he did is admirable because it’s tough, especially as one gets older, to radically switch mindsets after investing a lot of time acquiring deep expertise in any technical arena (the tendency is to dig one’s heels in). Add to that the fact that he worked for big gun CORBA vendor Iona Technologies (which no longer exists as an independent company) during the time of his epiphany, and you’ve got a bona fide role model for change, no?

Horse And Buggy
Werner Vogels is Amazon.com’s Chief Technology Officer and author of the blog “All Things Distributed – Building Scalable And Robust Distributed Systems“. I just couldn’t stop myself from laughing when he announced that fellow distributed-systems guru Steve Vinoski had just joined Twitter:

Specifically, the last sentence put me in stitches. As you can see from the book cover below, Steve is a CORBA expert and way back in the dark ages he was a CORBA advocate. However, he’s moved into the 21st century and left that horse and buggy behind – unlike others who cling to their horse whips and ostracize those who point out the obvious.

OMG! Design By Committee
In Federico Biancuzzi’s terrific “Masterminds Of Programming“, Federico interviews the three Amigo co-creators of UML. In discussing the “advancement” of the UML after the Amigos freely donated their work to the OMG for further development, Jim Rumbaugh had this to say:
The OMG (Object Management Group) is a case study in how political meddling can damage any good idea. The first version of UML was simple enough, because people didn’t have time to add a lot of clutter. Its main fault was an inconsistent viewpoint—some things were pretty high-level and others were closely aligned to particular programming languages. That’s what the second version should have cleared up. Unfortunately, a lot of people who were jealous of our initial success got involved in the second version. – Jim Rumbaugh
LOL! Following up, Jim landed a second blow:
The OMG process allowed all kinds of special interests to stuff things into UML 2.0, and since the process is mainly based on consensus, it is almost impossible to kill bad ideas. So UML 2.0 became a bloated monstrosity, with far too much dubious content, and still no consistent viewpoint and no way to define one. – Jim Rumbaugh
Double LOL!
Another UML co-creator, Grady Booch, says essentially the same thing but without specifically mentioning the OMG cabal:
UML 2.0 to some degree, and I’ll say this a little bit harshly, suffered a bit of a second system effect in that there were great opportunities and special interest groups, if you will, clamoring for certain specific features which added to the bloat of UML 2.0. – Grady Booch
Triple LOL!
Mitchi Henning, a key player during the CORBA era, rants about the OMG in this controversial “The Rise And Fall Of CORBA” article. Mitchi enraged the corbaholic community by lambasting both CORBA and the dysfunctional OMG politburo that maintains it:
Over the span of a few years, CORBA moved from being a successful middleware that was hailed as the Internet’s next-generation e-commerce infrastructure to being an obscure niche technology that is all but forgotten. This rapid decline is surprising. How can a technology that was produced by the world’s largest software consortium fall from grace so quickly? Many of the reasons are technical: poor architecture, complex APIs, and lack of essential features all contributed to CORBA’s downfall. However, such technical shortcomings are a symptom rather than a cause. Ultimately, CORBA failed because its standardization process virtually guarantees poor technical quality. Seeing that other standards consortia use a process that is very similar, this does not bode well for the viability of other technologies produced in this fashion. – Mitchi Henning
Maybe the kings and queens of the OMG should add an exclamation point to the end of their acronym: OMG!
The reason the OMG! junta interests me is because I’ve been working hands-on with RTI‘s implementation of the OMG Data Distribution Service (DDS) standard to design and build the infrastructure for a distributed sensor data processing server that will be embedded in a safety-critical supersystem. At this point in time, since DDS was co-designed, tested, and fielded by two commercial companies and it wasn’t designed from scratch by a big OMG committee, I think it’s a terrific standard. Particularly, I think RTI’s version is spectacular relative to the other two implementations that I know about. I hope the OMG! doesn’t transform DDS into an abomination………

ICONIX SysML Training Preview
During the week of January 25-29, I, along with 19 other enginerds will be attending a SysML training course given by Doug Rosenberg of ICONIX. At this point in time, I think the specific course is named “SysML JumpStart Training with Enterprise Architect“. I love the following “no-candyasses-allowed” warning at the bottom of the web page:
JumpStart Training is not a class for uncommitted students or uneasy beginners. Because of the rapid-learning atmosphere, JumpStart Training is ideal for those looking for an intense and highly-focused training course which will get the project up and running, fast!
I’m grateful for the opportunity and excited to attend the course because I’m a big fan of both the UML and its SysML profile. Over the past several years, I’ve been teaching myself at a leisurely pace how to apply these two increasingly important technologies to the software design and specification work that I do.
Because of the powerful and sprawling nature of the UML family, unless you’re an Einsteinian genius, it’s my uncredentialed opinion that you can’t learn UML or SysML overnight. The symbology, syntax, and semantics of the languages are rich and necessarily complex because they’re designed to tackle big hairball software-centric systems problems. Based on my personal experience, I don’t think very many people can acquire a deep understanding of the UML’s 13 diagrams or SysML’s 9 diagrams in 5 days, but you gotta start somewhere and formal training is a good start. We’ll see how it goes.
 While surfing the ICONIX web site, I stumbled upon this “MDG Technology For DDS” page (MDG = Model Driven Generation, DDS = Data Distribution Service). Interestingly, there seems to be no equivalent “MDG Technology For CORBA” page on the ICONIX web site. It’s interesting because I’m currently fighting a CORBA vs DDS battle in house. It’s even more interesting in that this InformIT author page states that Doug Rosenberg has previously developed and taught a CORBA class. I’ll be sure to ask Doug about this anomaly when I meet him.
While surfing the ICONIX web site, I stumbled upon this “MDG Technology For DDS” page (MDG = Model Driven Generation, DDS = Data Distribution Service). Interestingly, there seems to be no equivalent “MDG Technology For CORBA” page on the ICONIX web site. It’s interesting because I’m currently fighting a CORBA vs DDS battle in house. It’s even more interesting in that this InformIT author page states that Doug Rosenberg has previously developed and taught a CORBA class. I’ll be sure to ask Doug about this anomaly when I meet him.

Data-Centric, Transaction-Centric
The market (ka-ching!, ka-ching!) for transaction-centric enterprise IT (Information Technology) systems dwarfs that for real-time, data-centric sensor control systems. Because of this market disparity, the lion’s share of investment dollars is naturally and rightfully allocated to creating new software technologies that facilitate the efficient development of behemoth enterprise IT systems.
I work in an industry that develops and sells distributed, real-time, data-centric sensor systems and it frustrates me to no end when people don’t “see” (or are ignorant of) the difference between the domains. With innocence, and unfortunately, ignorance embedded in their psyche, these people try to jam-fit risky, transaction-centric technologies into data-centric sensor system designs. By risky, I mean an elevated chance of failing to meet scalability, real-time throughput and latency requirements that are much more stringent for data-centric systems than they are for most transaction-centric systems. Attributes like scalability, latency, capacity, and throughput are usually only measurable after a large investment has been made in the system development. To add salt to the wound, re-architecting a system after the mistake is discovered and ( more importantly) acknowledged, delays release and consumes resources by amounts that can seriously damage a company’s long term viability.
As an example, consider the CORBA and DDS OMG standard middleware technologies. CORBA was initially designed (by committee) from scratch to accommodate the development of big, distributed, client-server, transaction-centric systems. Thus, minimizing latency and maximizing throughout were not the major design drivers in its definition and development. DDS was designed to accommodate the development of big, distributed, publisher-subscriber, data-centric systems. It was not designed by a committee of competing vendors each eager to throw their pet features into a fragmented, overly complex quagmire. DDS was derived from the merger of two fielded and proven implementations, one by Thales (distributed naval shipboard sensor control systems) and the other by RTI (distributed robotic sensor and control systems). In contrast, as a well meaning attempt to be all things to all people, publish-subscribe capability was tacked on to the CORBA beast after the fact. Meanwhile, DDS has remained lean and mean. Because of the architecture busting risk for the types of applications DDS targets, no client-server capability has been back-fitted into its design.
Consider the example distributed, data-centric, sensor system application layer design below. If this application sits on top of a DDS middleware layer, there is no “intrusion” of a (single point of failure) CORBA broker into the application layer. Each application layer system component simply boots up, subscribes to the topic (message) streams it needs, starts crunching them with it’s app-specific algorithms, and publishes its own topic instances (messages) to the other system components that have subscribed to the topic.

Now consider a CORBA broker-based instantiation of this application example (refer to the figure below). Because of the CORBA requirement for each system component to register with an all knowing centralized ORB (Object Request Broker) authority, CORBA “leaks” into the application layer design. After registration, and after each service has found (via post-registration ORB lookup) the other services it needs to subscribe to, the ORB can disappear from the application layer – until a crash occurs and the system gets hosed. DDS avoids leakage into the value-added application layer by avoiding the centralized broker concept and providing for fully distributed, under-the-covers, “auto-discovery” of publishers and subscribers. No DDS application process has to interact with a registrar at startup to find other components – it only has to tell DDS which topics it will publish and which topics it needs to subscribe to. Each CORBA component has to know about the topics it needs and the services it needs to subscribe to.

The more a system is required to accommodate future growth, the more inapplicable a centralized ORB-based architecture is. Relative to a fully distributed coordination and auto-discovery mechanism that’s transparent to each application component, attempting to jam fit a single, centralized coordinator into a large scale distributed system so that the components can find and interact with each other reduces robustness, fault tolerance, and increases long term maintenance costs.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

