Archive
Ploddingly Slow, But Thorough
I cracked open one of my C++ programming books recently and started leafing through it in the hope of stirring up some warm memories of my use of the language to wrestle embedded systems problems into submission. Instead, I immediately experienced a moment of existential horror! My cherished language of choice all of a sudden looked like an intimidating, unfathomable, encrypted mess. I thought for a moment that I was having my second stroke.
It’s scary at how one can forget so much so fast unless one arduously burns calories to maintain a high level of competence in an area crucial for putting food on the table.
After regaining my bearings, I realized that most programmers who know other languages but don’t know C++ experience an instance of the same abject terror when they scrutinize C++ code for the first time. It’s too bad, but it is what it is.

Before my life was abruptly upended by the Emperor, I used to be a ploddingly slow, but thorough, C++ programmer. But as anyone who has read this blog quickly discovered, I ain’t never been no genius. I had to work much harder and longer than most to become a C++ craftsman. Malcolm Gladwell’s “10,000 hours to become a subject matter expert” threshold to prosperity is too low of a bar to apply to dumschitts like me. I needed 2X the time to become internally confident that I was an excellent C++ programmer. It was a difficult but satisfying road to travel because my mind was richly rewarded with the excitement of learning something new whenever I danced with C++’s exquisitely rich feature set and its “std::” (affectionately pronounced as “stood” 🙂 ) libraries in my head.

While coding away on problems, I was always thinking in the background about what I could do to help future maintainers understand the code ASAP so they could get something done without getting frustratingly stuck. I’m embarrassed and sad to admit it, but it was more of a classic, fear-based, ego-driven mission than an altruistic one. I was afraid of feeling like schitt whenever I envisioned colleagues reading my code. I yearned for everyone who read the code to say “Wow, I wish I knew this maestro!“, instead of “WTF!” after every few lines.

To drill deeper into what I’m exposing here about my dark passenger, I was firmly in the clutches of the “impostor syndrome” for most of my undecorated career. But hey, despite the fact that Stroustrup, Sutter, Meyers, Josuttis, Kalb, Lavavej, Lakos, Williams, Carruth, Niebler, Boehm, Alexandrescu, Gregory, Davidson caused my cancer ( <– just joking), it was a fun, multi-decade, journey down the C++ rabbit hole. I’m extremely gratefuI that all of those wonderful teachers took me along for the adventure.

In closing out this post, I remembered the need to blatantly include some Bitcoin propaganda in it. So, say ‘ello to my leetle friend…

I wish the tat was orange instead of black, but the artist didn’t have any orange ink in her pallet. I’ll make sure my upcoming neck tat is full Satoshi orange though.
Template Argument 1 Is Invalid

I’d like to thank the hard working hosts of the first ever C++ podcast, Rob Irving and Jason Turner, for mentioning my “Time To Get Moving!” blog post on episode #16. If you’re a C++ coder and you’re not a subscriber to this great learning resource, then shame on you.

Hey Rob and Jason, you guys gotta slightly modify your logo. You’re statement doesn’t compile because it’s illegal to use the “+” character in an identifier name 🙂

Since I pointed out the bug, what do you guys think about changing your template argument,”C++“, to “Bulldozer00“?
Make Simple Tasks Simple
In the slide deck that Bjarne Stroustrup presented for his “Make Simple Tasks Simple” CppCon keynote speech, he walked through a progression of refactorings that reduced an (arguably) difficult-to-read, multi-line, C++98 code segment (that searches a container for an element matching a specific pattern) into an expressive, C++11 one liner:
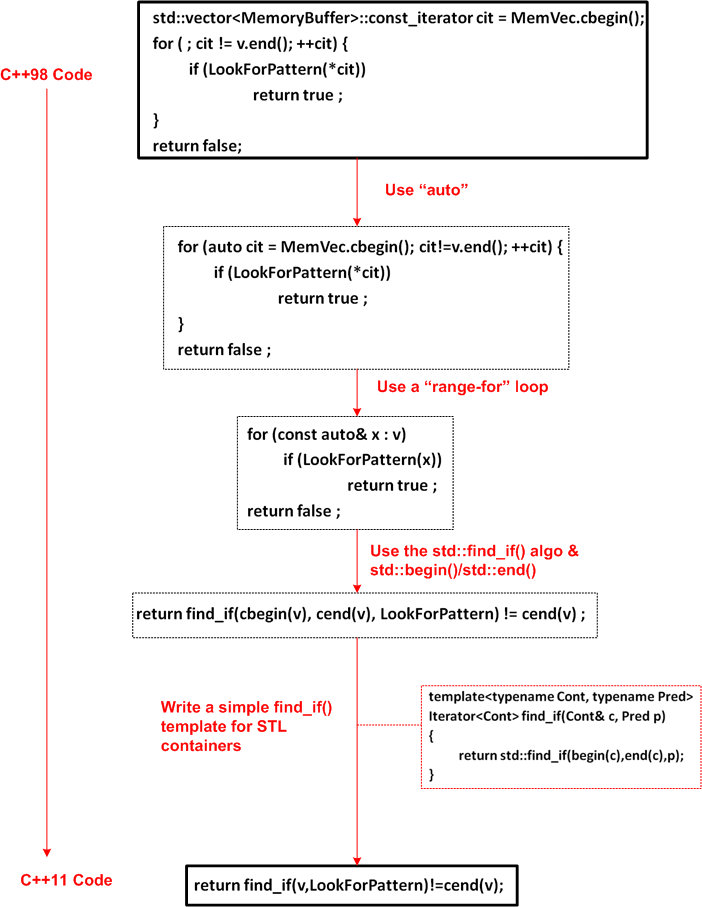
Some people may think the time spent refactoring the original code was a pre-mature optimization and, thus, a waste of time. But that wasn’t the point. The intent of the example was to illustrate several features of C++11 that were specifically added to the language to allow sufficiently proficient programmers to “make simple tasks simple (to program)“.
Note: After the fact, I discovered that “MemVec” should be replaced everywhere with “v” (or vice versa), but I was too lazy to fix the pic :). Can you find any other bugs in the code?
On The Origin Of Features
Thanks to an angel on the blog staff at the ISO C++ web site, my last C++ post garnered quite a few hits that were sourced from that site. Thus, I’m following it up with another post based on the content of Bjarne Stroustrup’s brilliant and intimate book, “The Design And Evolution Of C++“.
The drawing below was generated from a larger, historical languages chart provided by Bjarne in D&E. It reminds me of a couple of insightful quotes:
“Complex systems will evolve from simple systems much more rapidly if there are stable intermediate forms than if there are not.” — Simon, H. 1982. The Sciences of the Artificial.
“A complex system that works is invariably found to have evolved from a simple system that worked… A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over, beginning with a working simple system.” — Gall, J. 1986. Systemantics: How Systems Really Work and How They Fail.
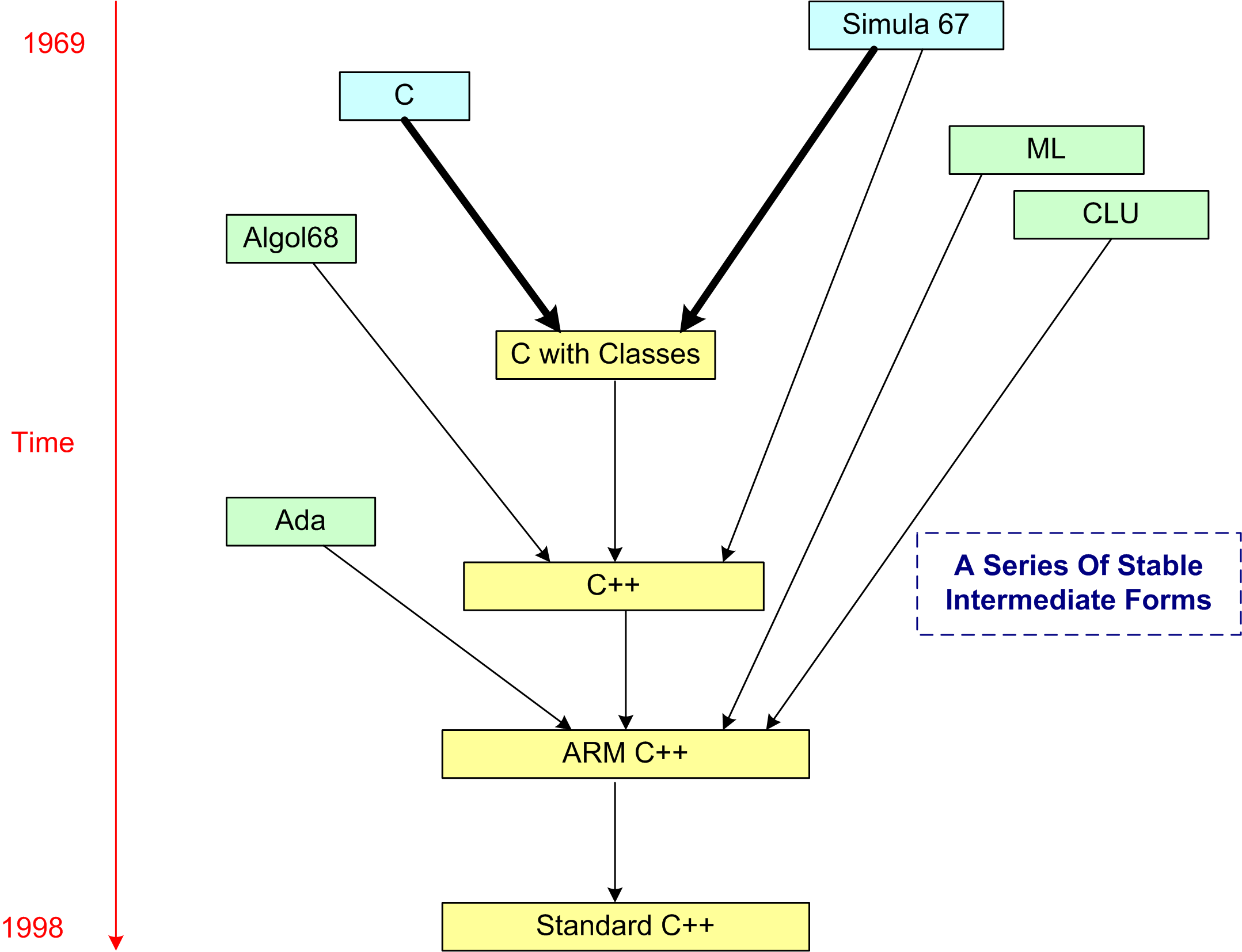
A we can see from the figure, “Simula67” and “C” were the ultimate ancestral parents of the C++ programming language. Actually, as detailed in my last post, “frustration” and “unwavering conviction” were the true parents of creation, but they’re not languages so they don’t show up on the chart. 🙂
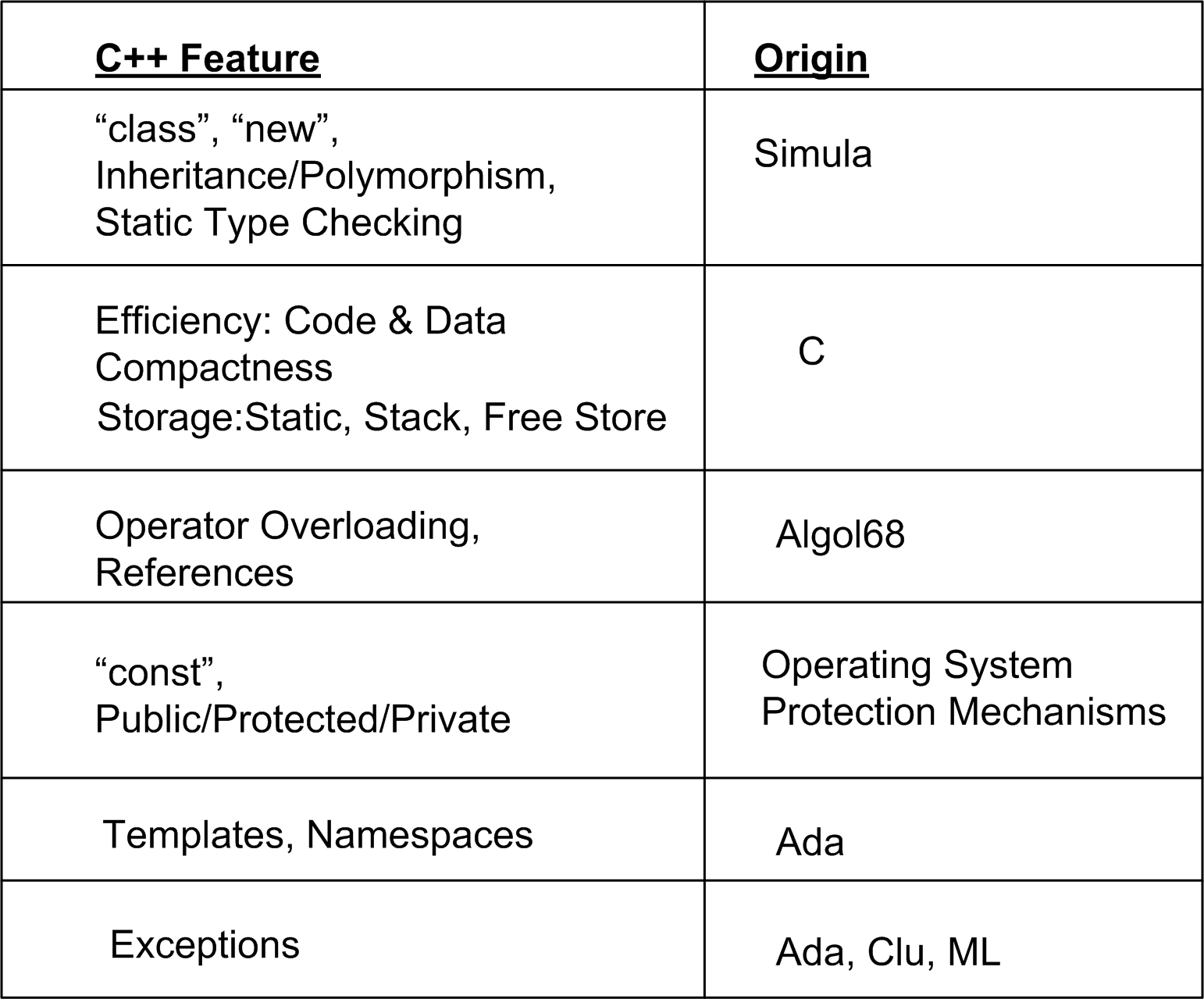
To complement the language-lineage figure, I compiled this table of early C++ features and their origins from D&E:
Finally, if you were wondering what Mr. Stroustrup’s personal feature-filtering criteria were (and still are 30+ years later!), here is the list:

If you consider yourself a dedicated C++ programmer who has never read D&E and my latest 2 posts haven’t convinced you to buy the book, then, well, you might not be a dedicated C++ programmer.
Looks Weird, But Don’t Be Afraid To Do It
Modern C++ (C++11 and onward) eliminates many temporaries outright by supporting move semantics, which allows transferring the innards of one object directly to another object without actually performing a deep copy at all. Even better, move semantics are turned on automatically in common cases like pass-by-value and return-by-value, without the code having to do anything special at all. This gives you the convenience and code clarity of using value types, with the performance of reference types. – C++ FAQ
Before C++11, you’d have to be tripping on acid to allow a C++03 function definition like this to survive a code review:
std::vector<int> moveBigThingsOut() {
const int BIGNUM(1000000);
std::vector<int> vints;
for(int i=0; i<BIGNUM; ++i) {
vints.push_back(i);
}
return vints;
}
Because of: 1) the bolded words in the FAQ at the top of the page, 2) the fact that all C++11 STL containers are move-enabled (each has a move ctor and a move assignment member function implementation), 3) the fact that the compiler knows it is required to destruct the local vints object just before the return statement is executed, don’t be afraid to write code like that in C++11. Actually, please do so. It will stun reviewers who don’t yet know C++11 and may trigger some fun drama while you try to explain how it works. However, unless you move-enable them, don’t you dare write code like that for your own handle classes. Stick with the old C++03 pass by reference idiom:
void passBigThingsOut(std::vector<int>& vints) {
const int BIGNUM(1000000);
vints.clear();
for(int i=0; i<BIGNUM; ++i) {
vints.push_back(i);
}
}
Which C++11 user code below do you think is cleaner?
//This one-liner?
auto vints = moveBigThingsOut();
//Or this two liner?
std::vector<int> vints{};
passBigThingsOut(vints);
Periodic Processing With Standard C++11 Facilities
With the addition of the <chrono> and <thread> libraries to the C++11 standard library, programs that require precise, time-synchronized functionality can now be written without having to include any external, non-standard libraries (ACE, Boost, Poco, pthread, etc) into the development environment. However, learning and using the new APIs correctly can be a non-trivial undertaking. But, there’s a reason for having these rich and powerful APIs:
The time facilities are intended to efficiently support uses deep in the system; they do not provide convenience facilities to help you maintain your social calendar. In fact, the time facilities originated with the stringent needs of high-energy physics. Furthermore, language facilities for dealing with short time spans (e.g., nanoseconds) must not themselves take significant time. Consequently, the <chrono> facilities are not simple, but many uses of those facilities can be very simple. – Bjarne Stroustrup (The C++ Programming Language, Fourth Edition).
Many soft and hard real-time applications require chunks of work to be done at precise, periodic intervals during run-time. The figure below models such a program. At the start of each fixed time interval T, “doStuff()” is invoked to perform an application-specific unit of work. Upon completion of the work, the program (or task/thread) “sleeps” under the care of the OS until the next interval start time occurs. If the chunk of work doesn’t complete before the next interval starts, or accurate, interval-to-interval periodicity is not maintained during operation, then the program is deemed to have “failed“. Whether the failure is catastrophic or merely a recoverable blip is application-specific.
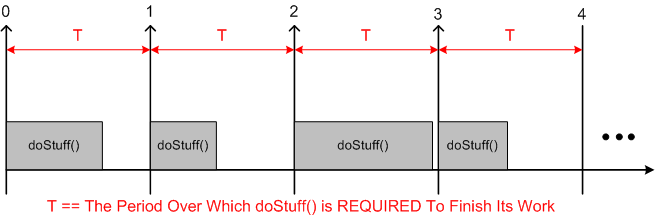
Although the C++11 time facilities support time and duration manipulations down to the nanosecond level of precision, the actual accuracy of code that employs the API is a function of the precision and accuracy of the underlying hardware and OS platform. The C++11 API simply serves as a standard, portable bridge between the coder and the platform.
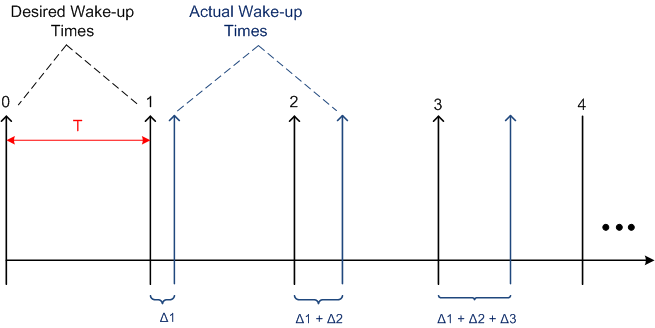
The figure below shows the effect of platform inaccuracy on programs that need to maintain a fixed, periodic timeline. Instead of “waking up” at perfectly constant intervals of T, some jitter is introduced by the platform. If the jitter is not compensated for, the program will cumulatively drift further and further away from “real-time” as it runs. Even if jitter compensation is applied on an interval by interval basis to prevent drift-creep, there will always be some time inaccuracy present in the application due to the hardware and OS limitations. Again, the specific application dictates whether the timing inaccuracy is catastrophic or merely a nuisance to be ignored.
The simple UML activity diagram below shows the cruxt of what must be done to measure the “wake-up error” on a given platform.

On each pass through the loop:
- The OS wakes us up (via <thread>)
- We retrieve the current time (via <chrono>)
- We compute the error between the current time and the desired time (via <chrono>)
- We compute the next desired wake-up time (via <chrono>)
- We tell the OS to put us to sleep until the desired wake-up time occurs (via <thread>)
For your viewing and critiquing pleasure, the source code for a simple, portable C++11 program that measures average “wakeup error” is shown here:

The figure below shows the results from a typical program run on a Win7 (VC++13) and Linux (GCC 4.7.2) platform. Note that the clock precision on the two platforms are different. Also note that in the worst case, the 100 millisecond period I randomly chose for the run is maintained to within an average of .1 percent over the 30 second test run. Of course, your mileage may vary depending on your platform specifics and what other services/daemons are running on that platform.

The purpose of writing and running this test program was not to come up with some definitive, quantitative results. It was simply to learn and play around with the <chrono> and <thread> APIs; and to discover how qualitatively well the software and hardware stacks can accommodate software components that require doing chunks of work on fixed, periodic, time boundaries.
In case anyone wants to take the source code and run with it, I’ve attached it to the site as a pdf: periodicTask.pdf. You could simulate chunks of work being done within each interval by placing a std::this_thread::sleep_for() within the std::this_thread::sleep_until() loop. You could elevate numLoops and intervalPeriodMillis from compile time constants to command line arguments. You can use std::minmax_element() on the wakeup error samples.
Another Humbler
It’s often frustrating but always well worth the pain to get humbled from time to time. If it happens often enough, it’ll deflate your head somewhat and keep you on the ground with the rest of your plebe peers. Too much humbling and you lose your self-esteem, too little humbling and you morph into an insufferable, self-important narcissist – like me. One of the reasons why I love zappos.com is that one of their core company values is “Be Humble”.
The other day, I was slinging some code and I was hunting for a bug. In order to slow things down and help expose the critter, I inserted the following code into my program:
//sleep for a second to allow already waiting subscribers a chance to discover us
boost::this_thread::sleep(boost::posix_time::milliseconds(2000));
std::cerr << “\nSleeping For A Bit….. Zzzz\n\n”;
I then ran the sucker and watched the console intently. Low and behold, the program did not seem to pause for the 2 seconds that I commanded. WTF? After the “Sleeping For A Bit” message was printed to the console, the program just zoomed along. WTF? Over the next 10 minutes, I reran the code several times and stared at the source. WTF? Then, by the grace of the universe, it hit me out of the blue:
//sleep for a second to allow already waiting subscribers a chance to discover us
std::cerr << “\nSleeping For A Bit….. Zzzz\n\n”;
boost::this_thread::sleep(boost::posix_time::milliseconds(2000));
Duh! This never happens to you, right?

Now, if I can only practice what I preach; walk the talk.
Close Spatial Proximity
Even on software development projects with agreed-to coding rules, it’s hard to (and often painful to all parties) “enforce” the rules. This is especially true if the rules cover superficial items like indenting, brace alignment, comment frequency/formatting, variable/method name letter capitalization/underscoring. IMHO, programmers are smart enough to not get obstructed from doing their jobs when trivial, finely grained rules like those are violated. It (rightly) pisses them off if they are forced to waste time on minutiae dictated by software “leads” that don’t write any code and (especially) former programmers who’ve been promoted to bureaucratic stooges.
Take the example below. The segment on the right reflects (almost) correct conformance to the commenting rule “every line in a class declaration shall be prefaced with one or more comment lines”. A stricter version of the rule may be “every line in a class declaration shall be prefaced with one or more Doxygenated comment lines”.

Obviously, the code on the left violates the example commenting rule – but is it less understandable and maintainable than the code on the right? The result of diligently applying the “rule” can be interpreted as fragmenting/dispersing the code and rendering it less understandable than the sparser commented code on the left. Personally, I like to see necessarily cohesive code lines in close spatial proximity to each other. It’s simply easier for me to understand the local picture and the essence of what makes the code cohesive.
Even if you insert an automated tool into your process that explicitly nags about coding rule violations, forcing a programmer to conform to standards that he/she thinks are a waste of time can cause the counterproductive results of subversive, passive-aggressive behavior to appear in other, more important, areas of the project. So, if you’re a software lead crafting some coding rules to dump on your “team”, beware of the level of granularity that you specify your coding rules. Better yet, don’t call them rules. Call them guidelines to show that you respect and trust your team mates.
If you’re a software lead that doesn’t write code anymore because it’s “beneath” you or a bureaucrat who doesn’t write code but who does write corpo level coding rules, this post probably went right over your head.
Note: For an example of a minimal set of C++ coding guidelines (except in rare cases, I don’t like to use the word “rule”) that I personally try to stick to, check this post out: project-specific coding guidelines.
Bah Hum BUG
Note: For those readers not familiar with c++ programming, you still might get some value out of this nerd-noid blarticle by skipping to the last paragraph.
The other day, a colleague called me over to help him find a bug in some c++ code. The bug was reported in from the field by system testers. Since the critter was causing the system to crash (which was better than not crashing and propagating bad “logical” results downstream) a slew of people, including the customer, were “waiting” for it to be fixed so the testers could continue testing. My friend had localized the bug to the following 3 simple lines:

After extracting the three lines of code out of the production program and wrapping it in a simple test driver, he found that after line 3 was executed, “val” was being set to “1” as expected. However, the “int” pointer, p_msg, was not being incremented as assumed by the downstream code – which subsequently crashed the system. WTF?
After figuring it out by looking up the c++ operator precedence rules, we recreated the crime scene in the diagram below. The left scenario at the bottom of the figure below was what we initially thought the code was doing, but the actual behavior on the right was what we observed. Not only was the pointer not incremented, but the value in msg[0] was being incremented – a double freakin’ whammy.

Before analyzing the precedence rules, we thought that there was a bug in the compiler (yeah, right). However, after thinking about it for a while, we understood the behavior. Line 3 was:
- extracting the value in msg[0] (which is “1”)
- assigning it to “val”
- incrementing the value in msg[0]
Changing the third line to “int val = *p_msg++” solved the problem. Because of the operator precedence rules, the new behavior is what was originally intended:
- extract the value in msg[0] (which is “1”)
- assign it to “val”
- increment the pointer to point to the value in msg[1]
A simple “const” qualifier placed at the beginning of line 2 would have caused the compiler to barf on the code in line 3: “you cannot assign to a variable that is const“. The bug would’ve been squashed before making it out into the field.
It’s great to be brought down to earth and occasionally being humbled by experiences like these; especially when you’re not the author of the bug 🙂 Plus, after-the-fact fire fighting is cherished by institutions over successful prevention. After all, how can you reward someone for a problem that didn’t occur because of his/her action? Even worse, most institutions actively thwart the application of prevention techniques by imposing Draconian schedules upon those doing the work.
The world is full of willing people, some willing to work, the rest willing to let them. – Robert Frost
My contortion of this quote is:
The world is full of willing people, some willing to work, the rest willing to manage them while simultaneously pressuring them into doing a poor job. – Bulldozer00
Project-Specific Coding Guidelines
I’m about to embark on the development of a distributed, scalable, data-centric, real-time, sensor system. Since some technical risks are at this point disturbingly high, especially meeting CPU loading and latency requirements, a team of three of us (two software engineers and one system engineer) are going to prototype several CPU-intensive system functions.
Assuming that our prototyping effort proves that our proposed application layer functional architecture is feasible, a much larger team will be applied to the effort in an attempt to meet schedule. In order to promote consistency across the code base, facilitate on-boarding of new team members, and lower long term maintenance costs, I’m proposing the following 15 design and C++ coding guidelines:
- Minimize macro usage.
- Use STL containers instead of homegrown ones.
- No unessential 3rd party libraries, with the exception of Boost.
- Strive for a clear and intuitive namespace-to-directory mapping.
- Use a consistent, uniform, communication scheme between application processes. Deviations must be justified.
- Use the same threading library (Boost) when multi-threading is needed within a process.
- Design a little, code a little, unit test a little, integrate a little, document a little. Repeat.
- Avoid casting. When casting is unavoidable, use the C++ cast operators so that the cast hacks stick out like a sore thumb.
- No naked pointers when heap memory is required. Use C++ auto and Boost smart pointers.
- Strive for pure layering. Document all non-adjacent layer interface breaches and wrap all forays into OS-specific functionality.
- Strive for < 100 lines of code per function member.
- Strive for < 4 nested if-then-else code sections and inheritance tree depths.
- Minimize “using” directives, liberally employ “using” declarations to keep verbosity low.
- Run the code through a static code analyzer frequently.
- Strive for zero compiler warnings.
Notice that the list is short, (maybe) memorize-able, and (maybe) enforceable. It’s an attempt to avoid imposing a 100 page tome of rules that nobody will read, let alone use or enforce. What do you think? What is YOUR list of 15?

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

