Stack, Heap, Pool: The Prequel
Out of the 1600+ posts I’ve written for this blog over the past 6 years, the “Stack, Heap, Pool” C++ post has gotten the most views out of the bunch. However, since I did not state my motive for writing the post, I think it caused some people to misinterpret the post’s intent. Thus, the purpose of this post is to close that gap of understanding by writing the intro to that post that I should have written. So, here goes…
The figure below shows a “target” entering, traversing, and exiting a pre-defined sensor coverage volume.
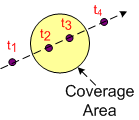
From a software perspective:
- A track data block that represents the real world target must be created upon detection and entry into the coverage volume.
- The track’s data must be maintained in memory and updated during its journey through the coverage volume. (Thus, the system is stateful at the application layer by necessity.)
- Since the data becomes stale and useless to system users after the target it represents leaves the coverage volume, the track data block must be destroyed upon exit (or some time thereafter).
Now imagine a system operating 24 X 7 with thousands of targets traversing through the coverage volume over time. If the third processing step (controlled garbage collection) is not performed continuously during runtime, then the system has a memory leak. At some point after bootup, the system will eventually come to a crawl as the software consumes all the internal RAM and starts thrashing from swapping virtual memory to/from off-processor, mechanical, disk storage.
In C++, there are two ways of dynamically creating/destroying objects during runtime:
- Allocating/deallocating objects directly from the heap using standard language facilities (new+delete (don’t do this unless you’re stuck in C++98/03 land!!!), std::make_shared, or, preferably, std::make_unique)
- Acquiring/releasing objects indirectly from the heap using a pool of memory that is pre-allocated from said heap every time the system boots up.
Since the object’s data fields must be initialized in both techniques, initialization time isn’t a factor in determining which method is “faster“. Finding a block of memory the size of a track object is the determining factor.
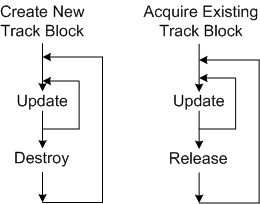
As the measurements I made in the “Stack, Heap, Pool” post have demonstrated, the pool “won” the performance duel over direct heap allocation in this case because it has the advantage that all of its entries are the exact same size of a track object. Since the heap is more general purpose than a pool, the use of an explicit or implicit “new” will generally make finding an appropriately sized chunk of memory in a potentially fragmented heap more time consuming than finding one in a finite, fixed-object-size, pool. However, the increased allocation speed that a pool provides over direct heap access comes with a cost. If the number of track objects pre-allocated on startup is less than the peak number of targets expected to be simultaneously present in the coverage volume at any one instant, then newly detected targets will be discarded because they can’t “fit” into the system – and that’s a really bad event when users are observing and directing traffic in the coverage volume. There is no such thing as a free lunch.

Leave a comment
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address


Thannk you for writing this
You’re welcome. I’m glad you liked it.