Archive
Asstimation!
Here’s one way of incrementally learning how to generate better estimates:
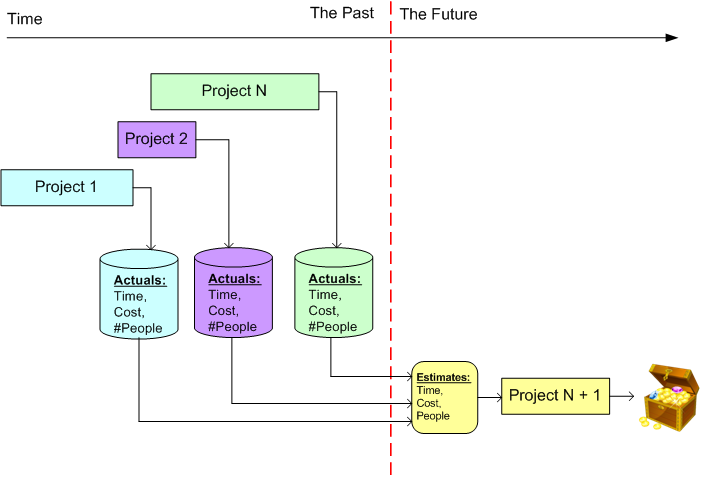 Like most skills, learning to estimate well is simple in theory but difficult in practice. For each project, you measure and record the actuals (time, cost, number/experience/skill-types of people) you’ve invested in your project. You then use your historical metrics database to estimate what it should take to execute your next project. You can even supplement/compare your empirical, company-specific metrics with industry-wide metrics available from reputable research firms.
Like most skills, learning to estimate well is simple in theory but difficult in practice. For each project, you measure and record the actuals (time, cost, number/experience/skill-types of people) you’ve invested in your project. You then use your historical metrics database to estimate what it should take to execute your next project. You can even supplement/compare your empirical, company-specific metrics with industry-wide metrics available from reputable research firms.
It should be obvious, but good estimates are useful for org-wide executive budgeting/allocating of limited capital and human resources. They’re also useful for aiding a slew of other org-wide decisions (do we need to hire/fire, take out a loan, restrict expenses in the short term, etc). Nevertheless, just like any other tool/technique used to develop non-trivial software systems, the process of estimation is fraught with risks of “doing it badly“. It requires discipline and perseverance to continuously track and record project “actuals“. Perhaps hardest of all is the ongoing development and maintenance of a system where historical actuals can be easily categorized and painlessly accessed to compose estimates for important impending projects.
In the worst cases of estimation dysfunction, the actuals aren’t tracked/recorded at all, or they’re hopelessly inaccessible, or both. Foregoing the thoughtful design, installation, and maintenance of a historical database of actuals (rightfully) fuels the radical #noestimates twitter community and leads to the well-known, well-tread, practice of:
OMITTED ACTIVITIES!
The best book I’ve read (so far) on software estimation is Steve McConnell’s “Software Estimation: Demystifying the Black Art“. Steve is one of the most pragmatic technical authors I know. His whole portfolio of books is worth delving into.
Prior to describing many practical and “doable” estimation practices, Steve presents a dauntingly depressive list of estimation error sources:
- Unstable requirements
- Unfounded optimism
- Subjectivity and bias
- Unfamiliar application domain area
- Unfamiliar technology area
- Incorrect conversion from estimated time to project time (for example, assuming the project team will focus on the project eight hours per day, five days per week)
- Misunderstanding of statistical concepts (especially adding together a set of “best case” estimates or a set of “worst case” estimates)
- Budgeting processes that undermine effective estimation (especially those that require final budget approval in the wide part of the Cone of Uncertainty)
- Having an accurate size estimate, but introducing errors when converting the size estimate to an effort estimate
- Having accurate size and effort estimates, but introducing errors when converting those to a schedule estimate
- Overstated savings from new development tools or methods
- Simplification of the estimate as it’s reported up layers of management, fed into the budgeting process, and so on
- OMITTED ACTIVITIES!
But wait! We’re not done. That last screaming bullet, OMITTED ACTIVITIES!, needs some elaboration:
- Glue code needed to use third-party or open-source software
- Ramp-up time for new team members
- Mentoring of new team members
- Management coordination/manager meetings
- Requirements clarifications
- Maintaining the scripts required to run the daily build
- Participation in technical reviews
- Integration work
- Processing change requests
- Attendance at change-control/triage meetings
- Maintenance work on previous systems during the project
- Performance tuning
- Administrative work related to defect tracking
- Learning new development tools
- Answering questions from testers
- Input to user documentation and review of user documentation
- Review of technical documentation
- Reviewing plans, estimates, architecture, detailed designs, stage plans, code, test cases
- Vacations
- Company meetings
- Holidays
- Sick days
- Weekends
- Troubleshooting hardware and software problems
It’s no freakin’ wonder that the vast majority of software-intensive projects are underestimated, no? To add insult to injury, the unspoken pressure from the “upper layers” to underestimate the activities that ARE actually included in a project plan seals the deal for “perceived” future failure, no? It’s also no wonder that after a few years, good technical people who feel that hands-on creative work is their true calling start agonizing over whether to get the hell out of such a failure-inducing system and make the move on up into the world of politics, one-upsmanship, feigned collaboration, dubious accomplishment, and strategic self-censorship. Bummer for those people and the orgs they dwell in. Bummer for “the whole“.

An Estimation Example
The figure below shows the derivation of an estimate of work in staff-hours to design/develop/test a Computer Software Configuration Item (CSCI) named YYYY. The estimate is based on the size of an existing CSCI named XXXX and the productivity numbers assigned to the “Real Time” category of software from the productivity chart in Steve McConnell‘s “Software Estimation: Demystifying the Black Art“.

Of course, the simple equation used to compute effort and all of the variables in it can be challenged, but would it improve the accuracy of the range of estimates?
Estimation Deflation
The best book I’ve read to date on the topic of software effort and schedule estimation is Steve McConnell‘s “Software Estimation: Demystifying the Black Art“. According to Mr. McConnell, two large influences on the amount of work required to develop a non-trivial piece of software are “size” and “kind“. Regardless of the units of measure (use cases, user stories, function points, Lines Of Code, etc), the greater the “size”, the greater the amount of work required to build the thang. Similarly, the harder “kinds” are associated with lower productivity than the simpler “kinds”.
In his book, McConnell provides the following handy, industry-data-backed, “kinds” vs “productivity” table that’s parameterized by “size” (in Lines Of Code (LOC)). Note that the “kinds” are sort of arbitrary and by no means an industry standard.

The Real-Time, 10K-100K LOC entry is circled because that’s the type and typical size of software that I specify/design/write. Note the huge 15-to-1 range of productivity for the type. Also note that the table contains large ranges of productivity for all the kind-size entries. Hint, hint: estimating is hard.
Ideally, for psuedo-accurate planning purposes, a software development org maintains its own table (see bogus example below) with real, measured numbers for the sizes of the CSCIs (Computer Software Configuration Items) that its DICs have created.
 Of course, for a variety of cultural, competence, and social reasons, a lot of orgs don’t measure or maintain a custom productivity table. Thus, estimators are forced to pull numbers out of their arses and anyone’s productivity estimate is as bad anyone else’s. Everyone who wasn’t born yesterday knows that the pressure to use ridiculously high productivity numbers in work estimates pervades the ether in most orgs. Even when some FAI bucks the trend and withstands the looks and sound bites of disdain for conjuring up a work estimate that is perceived by the management chain as “too high”, the final estimates that show up on “approved” schedules are magically deflated to what is wanted by some clueless BM, SCOL, or CGH.
Of course, for a variety of cultural, competence, and social reasons, a lot of orgs don’t measure or maintain a custom productivity table. Thus, estimators are forced to pull numbers out of their arses and anyone’s productivity estimate is as bad anyone else’s. Everyone who wasn’t born yesterday knows that the pressure to use ridiculously high productivity numbers in work estimates pervades the ether in most orgs. Even when some FAI bucks the trend and withstands the looks and sound bites of disdain for conjuring up a work estimate that is perceived by the management chain as “too high”, the final estimates that show up on “approved” schedules are magically deflated to what is wanted by some clueless BM, SCOL, or CGH.

Reuse Based Estimation
“It’s called estimation, not exactimation” – Scott Ambler
One of the pragmatically simple, down to earth equations in Steve McConnell‘s terrific “Software Estimation” defines the schedule for a new software development project in terms of past performance as:

Of course, in order to use the equation to compute a guesstimate, as the table below shows, you must have tracked and recorded past efforts along with the calendar times it took to get those jobs completed.

Of course, not many orgs keep a running tab of past projects in an integrated, simple to use, easily accessible form like the above table, or do they? The info may actually be available someplace in the corpo data dungeon, but it’s likely fragmented, scattered, and buried within all kinds of different and incompatible financial forms and Microsoft project files. Why is this the case? Because it’s a management task and thus, no one’s responsible for doing it. In elegant corpo-speak, managers are responsible for “getting work done through others“. The catch phrase used to be “getting work done“, but to remove all ambiguity and increase clarity, the “through others” was cleverly or unconsciously tacked on.
How about you? How do you guesstimate effort and schedule?
Zero Time, Zero Cost
In “The Politics Of Projects“, Robert Block states that orgs “don’t want projects, they want products“. Thus, the left side of the graph below shows the ideal project profile; zero cost and zero time. A twitch of Samantha Stevens’s nose and, voila, a marketable product appears out of thin air and the revenue stream starts flowin’ into the corpo coffers.

Based on a first order linear approximation, all earthly product development orgs get one of the performance lines on the right side of the figure. There are so many variables involved in the messy and chaotic process from viable idea to product that it’s often a crap shoot at predicting the slope and time-to-100-percent-complete end point of the performance line:
- Experience of the project team
- Cohesiveness of the project team
- Enthusiasm of the project team
- Clarity of roles and responsibilities of each team member
- Expertise in the product application domain
- Efficacy of the development tool set
- Quality of information available to, and exchanged between, project members
- Amount and frequency of meddling from external, non-project groups and individuals
- <Add your own performance influencing variable here>
To a second order approximation, the S-curve below shows real world project performance as a function of time. The slope of the performance trajectory (% progress per unit time) is not constant as the previous first order linear model implies. It starts out small during the chaotic phase, increases during the productive stage, then decreases during the closeout phase. The objective is to minimize the time spent in phases P1, P2, and P3 without sacrificing quality or burning out the project team via overwork.
 Assume (and it’s a bad assumption) that there’s an objective and accurate way of measuring “% complete” at any given time for a project. Now, assume that you’ve diligently tracked and accumulated a set of performance curves for a variety of large and small projects and a variety of teams over the years. Armed with this data and given a new project with a specific assigned team, do you think you could accurately estimate the time-to-completion of the new project? Why or why not?
Assume (and it’s a bad assumption) that there’s an objective and accurate way of measuring “% complete” at any given time for a project. Now, assume that you’ve diligently tracked and accumulated a set of performance curves for a variety of large and small projects and a variety of teams over the years. Armed with this data and given a new project with a specific assigned team, do you think you could accurately estimate the time-to-completion of the new project? Why or why not?
Wishful And Realistic
As software development orgs grow, they necessarily take on larger and larger projects to fill the revenue coffers required to sustain the growth. Naturally, before embarking on a new project, somebody’s gotta estimate how much time it will take and how many people will be needed to get it done in that guesstimated time.
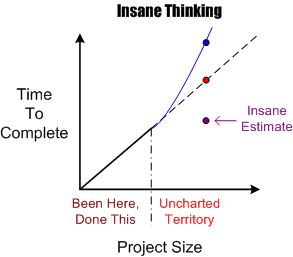
The figure below shows an example of the dumbass linear projection technique of guesstimation. Given a set of past performance time-size data points, a wishful estimate for a new and bigger project is linearly extrapolated forward via a neat and tidy, mechanistic, textbook approach. Of course, BMs, DICs, and customers all know from bitter personal experience that this method is bogus. Everyone knows that software projects don’t scale linearly, but (naturally) no one speaks up out of fear of gettin’ their psychological ass kicked by the pope du jour. Everyone wants to be perceived as a “team” player, so each individual keeps their trap shut to avoid the ostracism, isolation, and pariah-dom that comes with attempting to break from clanthink unanimity. Plus, even though everyone knows that the wishful estimate is an hallucination, no one has a clue of what it will really take to get the job done. Hell, no one even knows how to define and articulate what done means. D’oh! (Notice the little purple point in the lower right portion of the graph. I won’t even explain its presence because you can easily figure out why it’s there.)
 OK, you say, so what works better Mr. Smarty-Pants? Since no one knows with any degree of certainty what it will take to “just get it done” (<- tough management speak – lol!) nothing really works in the absolute sense, but there are some techniques that work better than the standard wishful/insane projection technique. But of course, deviation from the norm is unacceptable, so you may as well stop reading here and go back about your b’ness.
OK, you say, so what works better Mr. Smarty-Pants? Since no one knows with any degree of certainty what it will take to “just get it done” (<- tough management speak – lol!) nothing really works in the absolute sense, but there are some techniques that work better than the standard wishful/insane projection technique. But of course, deviation from the norm is unacceptable, so you may as well stop reading here and go back about your b’ness.
One such better, but forbidden, way to estimate how much time is needed to complete a large hairball software development project is shown below. A more realistic estimate can be obtained by assuming an exponential growth in complexity and associated time-to-complete with increasing project size. The trick is in conjuring up values for the constant K and exponent M. Hell, it requires trickery to even come up with an accurate estimate of the size of the project; be it function points, lines of code, number of requirements or any other academically derived metric.

An even more effective way of estimating a more accurate TTC is to leverage the dynamic learning (gasp!) that takes place the minute the project execution clock starts tickin’. Learning? Leverage learning? No mechanistic equations based on unquantifiable variables? WTF is he talkin’ bout? He’s kiddin’ right?

Dude, Read It The Freakin’ First Time
Recently, I was asked by Joe Manager to estimate the amount of resources (people and time) that I thought would be consumed in the development of a large, computationally-intensive, software-centric system. I dutifully did what was asked of me and posted a coarse, first cut estimate on the company wiki for all to scrutinize. I also provided a link to the page to Joe Manager. Unsurprisingly (to me at least) , at the next “planning” meeting I was asked again by Joe, on-the-spot and in real-time, what it would take to do the job if I were to lead the project. Since my pre-meeting intuition told me to bring a hard copy of my estimate to the meeting, I presented it to Mr. Manager and gently reminded him that I had forwarded it to him earlier when he asked for it the (freakin’) first time.

Apparently, besides being forgetful, poor Joe wasn’t told of the not-so-secret policy that I’m not allowed to lead anyone, let alone a team on a large and costly software development project that could be pretty important to the company’s future. Plus, since Joe’s last name is “Manager”, isn’t he supposed to at least consider planning and leading the effort his own freakin’ self? Or is he just envisioning someone else struggling to get it done while he periodically samples status, rides the schedule, and watches from the grassy knoll.
In a bacon and eggs breakfast, the chicken is involved, but the pig is committed – Ken Schwaber
Percent Complete
In order to communicate progress to someone who requires a quantitative number attached to it, some sort of consistent metric of accomplishment is needed. The table below lists some of the commonly used size metrics in the software development world.

All of these metrics suffer to some extent from a “consistency” problem. The problem (as exemplified in the figure below) is that, unlike a standard metric such as the “meter”, the size and meaning of each unit is different from unit to unit within an application, and across applications. Out of all the metrics in the list, the definition of what comprises a “Function Point” unit seems to be the most rigorous, but it still suffers from a second, “translation” problem. The translation problem manifests when an analyst attempts to convert messy and ambiguous verbal/written user needs into neat and tidy requirement metrics using one of the units in the list.

Nevertheless, numerically-trained MBA and PMI certified managers and their higher up executive bosses still obsessively cling to progress reports based on these illusory metrics. These STSJs (Status Takers and Schedule Jockeys) love to waste corpo time passing around status reports built on quicksand like the “percent done” example below.

The problems with using graphs like this to “direct” a project are legion. First, it is assumed that the TNFP is known with high accuracy at t=0 and, more erroneously, that its value stays constant throughout the duration. A second problem with this “best practice” is that lots, if not all, non-trivial software development projects do not progress linearly with the passage of time. The green trace in the graph is an example of a non-linearly progressing project.
Since most managers are sequential, mechanistic, left-brain-trained thinkers, they falsely conclude that all projects progress linearly. These bozelteens also operate under the meta-assumption that no initial assumptions are violated during project execution (regardless of what items they initially deposited in their “risk register” at t=0). They mistakenly arrive at conclusions like: ” if it took you two weeks to get to 50% done, you will be expected to be done in two more weeks”. Bummer.
Even after trashing the “percent complete” earned-value-management method in the previous paragraphs, I think there is a chance to acquire a long term benefit by tracking progress this way. The benefit can accrue IF AND ONLY IF the method is not taken too seriously and it’s not used to impose undue stress upon the software creators and builders who are trying their best to balance time-cost and quality. Performing the “percent complete” method over a bunch of projects and averaging the results can yield decent, but never 100% accurate, metrics that can be used to more effectively estimate future project performance. What do you think?
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address


{kind=link}