Archive
On The Origin Of Features
Thanks to an angel on the blog staff at the ISO C++ web site, my last C++ post garnered quite a few hits that were sourced from that site. Thus, I’m following it up with another post based on the content of Bjarne Stroustrup’s brilliant and intimate book, “The Design And Evolution Of C++“.
The drawing below was generated from a larger, historical languages chart provided by Bjarne in D&E. It reminds me of a couple of insightful quotes:
“Complex systems will evolve from simple systems much more rapidly if there are stable intermediate forms than if there are not.” — Simon, H. 1982. The Sciences of the Artificial.
“A complex system that works is invariably found to have evolved from a simple system that worked… A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over, beginning with a working simple system.” — Gall, J. 1986. Systemantics: How Systems Really Work and How They Fail.
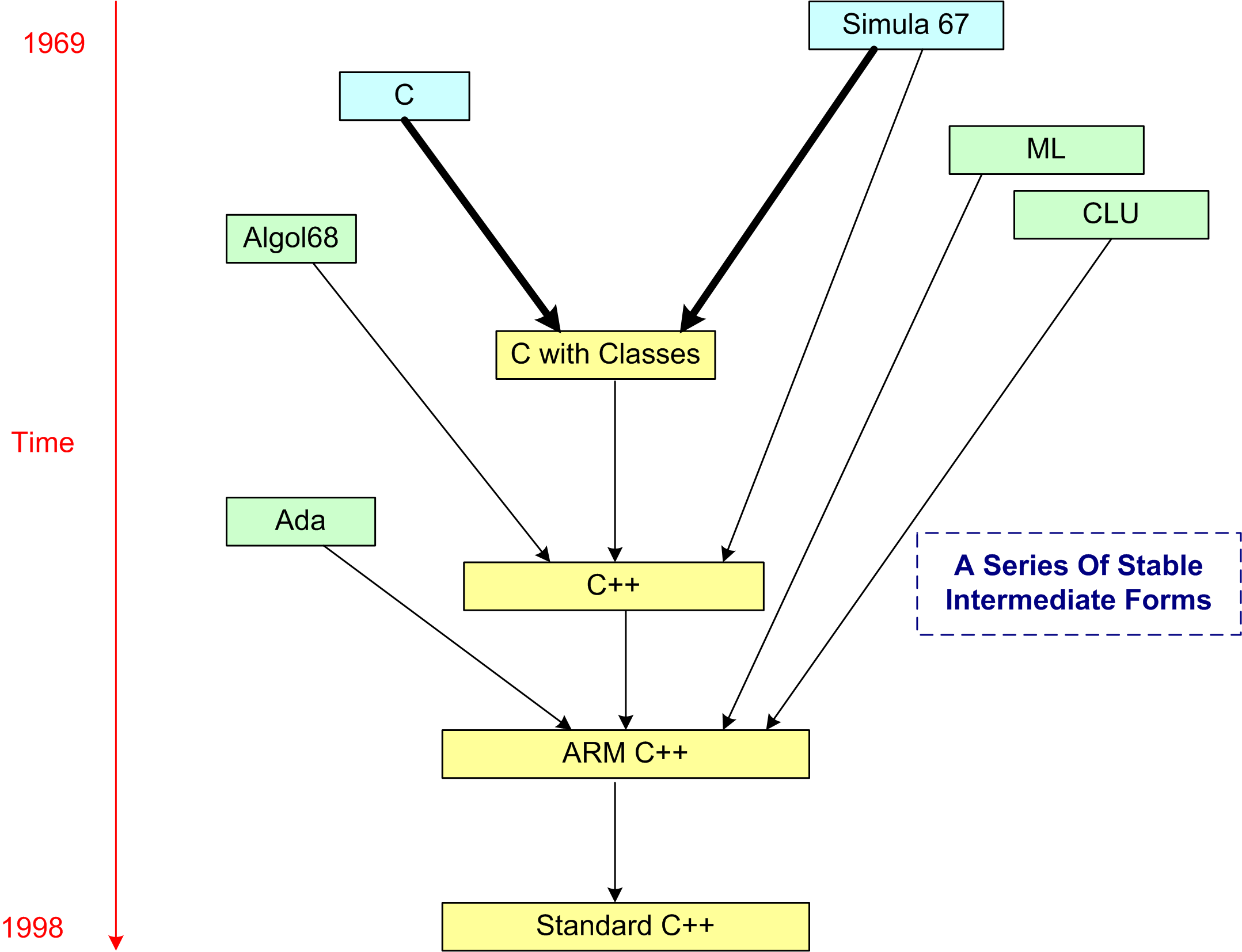
A we can see from the figure, “Simula67” and “C” were the ultimate ancestral parents of the C++ programming language. Actually, as detailed in my last post, “frustration” and “unwavering conviction” were the true parents of creation, but they’re not languages so they don’t show up on the chart. 🙂
To complement the language-lineage figure, I compiled this table of early C++ features and their origins from D&E:
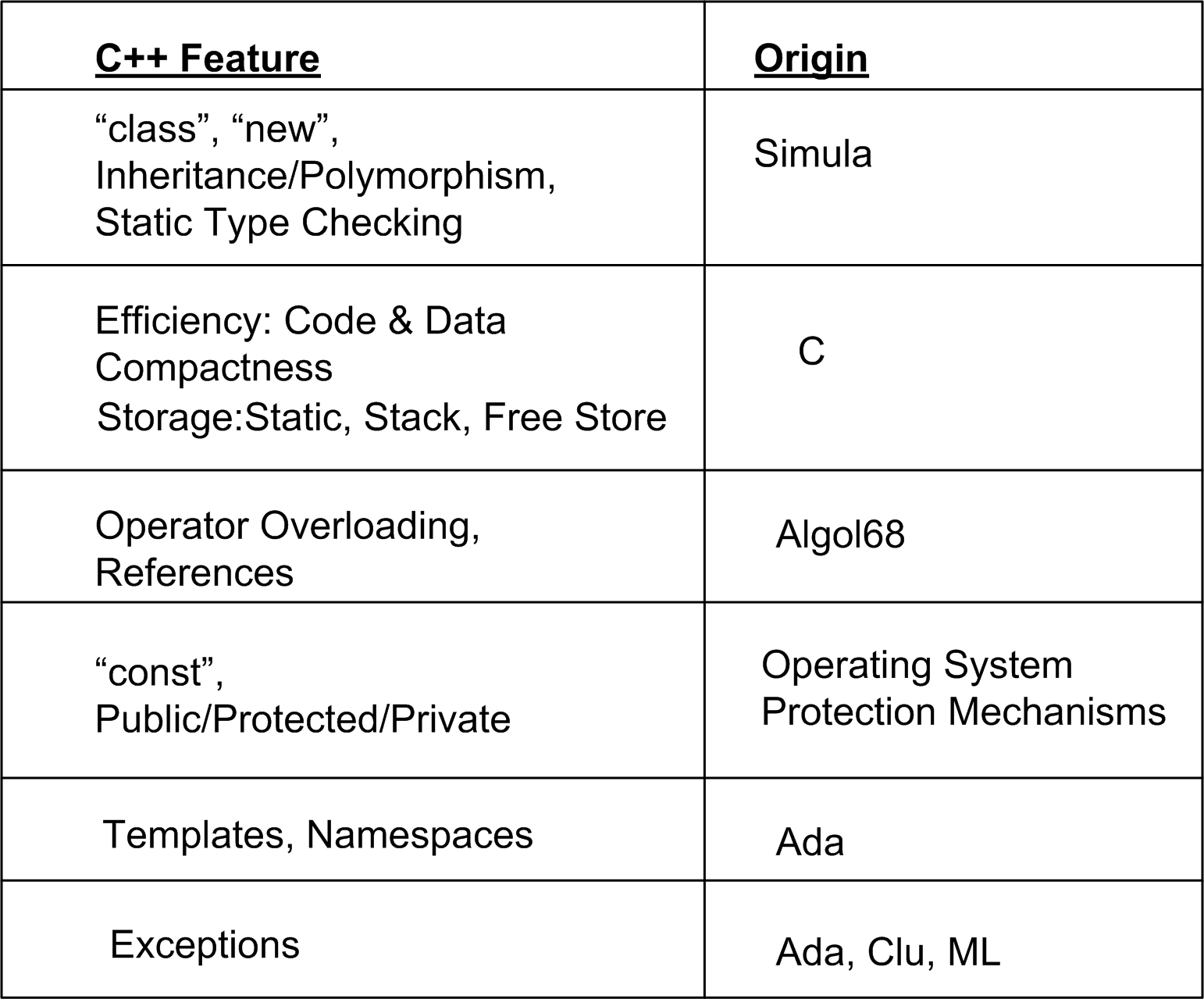
Finally, if you were wondering what Mr. Stroustrup’s personal feature-filtering criteria were (and still are 30+ years later!), here is the list:

If you consider yourself a dedicated C++ programmer who has never read D&E and my latest 2 posts haven’t convinced you to buy the book, then, well, you might not be a dedicated C++ programmer.
And In The Beginning…
I’m on my second pass through Bjarne Stroustrup’s “The Design And Evolution Of C++“. In the book, which was published exactly 20 years ago in 1994, Bjarne discloses all of the “whys” and “hows” that drove the growth of C++ up to the time of the book’s publication.
In the beginning, before there was C++ there was the even-more-nerdly-named “C With Classes” (CWC). Bjarne’s motivation for creating CWC was, as many inventions are, rooted in frustration:
This was exactly the kind of problem that I had become determined never again to attack without the proper tools. – Bjarne Stroustrup
The problem Bjarne refers to in the above quote was: “the task of exploring if/how the UNIX kernel could be distributed over a network of LAN-connected computers“. The preceding “never again” problem was for achieving his Ph.D. thesis at Cambridge University: “to study alternatives for the organization of system software for distributed systems“. Notice how the word “distributed” appears in both problems – and this was way back in the 70’s when bell bottoms were in fashion and prior to the rise of multi-core processor technology.

Even though he didn’t say why he chose the tool for his Cambridge Ph.D. thesis project, Bjarne used Nygaard and Dahl’s Simula programming language to code up a program for “simulating software running on a distributed system“. If you already know the history of C++, you won’t be surprised at Bjarne’s feelings for Simula or why he imported some of its key features into CWC:
It was a pleasure to write that simulator. The features of Simula were almost ideal for the purpose, and I was particularly impressed by the way the concepts of the language helped me think about the problems in my application. The class concept allowed me to map my application concepts into the language constructs in a direct way that made my code more readable than I had seen in any other language. The way Simula classes can act as co-routines made the inherent concurrency of my application easy to express.
Class hierarchies were used to express variants of application-level concepts. The use of class hierarchies was not heavy, though; the use of classes to express concurrency was much more important in the organization of my simulator.
During writing and initial debugging, I acquired a great respect for the expressiveness of Simula’s type system and its compiler’s ability to catch type errors.
In the above book quotes, we see the “whys” for:
- The appearance of the “Classes” word in “C With Classes“.
- CWC’s’s support for an object oriented programming style
- CWC’s static type system.
In contrast to Simula’s elegant expressiveness, its compile time and runtime performance were abysmal (garbage collection + runtime type checking + built-in concurrency = slooow). The runtime performance was so poor that Bjarne had to rewrite his simulator in low-level BPCL at the last second in order to get any meaningful results out of the program to stuff into his Ph.D. thesis.
Although there were several other pragmatic reasons for the appearance of the “C” in “C With Classes” (flexibility, ubiquity of available compilers, direct mapping of data to the hardware, simple linkage and runtime systems), performance ultimately drove the decision to use the well known and proven C language as ground zero for CWC – despite its funky syntactic quirks and unsafe features.
Curiously, support for concurrency was provided in CWC’s very first library in 1980. Concurrency appeared in the form of a tasking library and built-in support for two special functions recognized by the preprocessor: call() and return(). If defined by the programmer for a class, these functions would get implicitly invoked prior to entry and prior to exit of every class member function except for the constructor/destructor. They were required by the monitor class in the tasking library to acquire and release a lock for precluding data races. Interestingly, the call() and return() functions were later removed because “nobody used them but me“. We’d have to wait until 2011 for concurrency to return to C++ in the form of new libraries.
On exiting this post, I’d like to show you this e-mail exchange with Bjarne regarding the possibility of a book sequel in the near future:
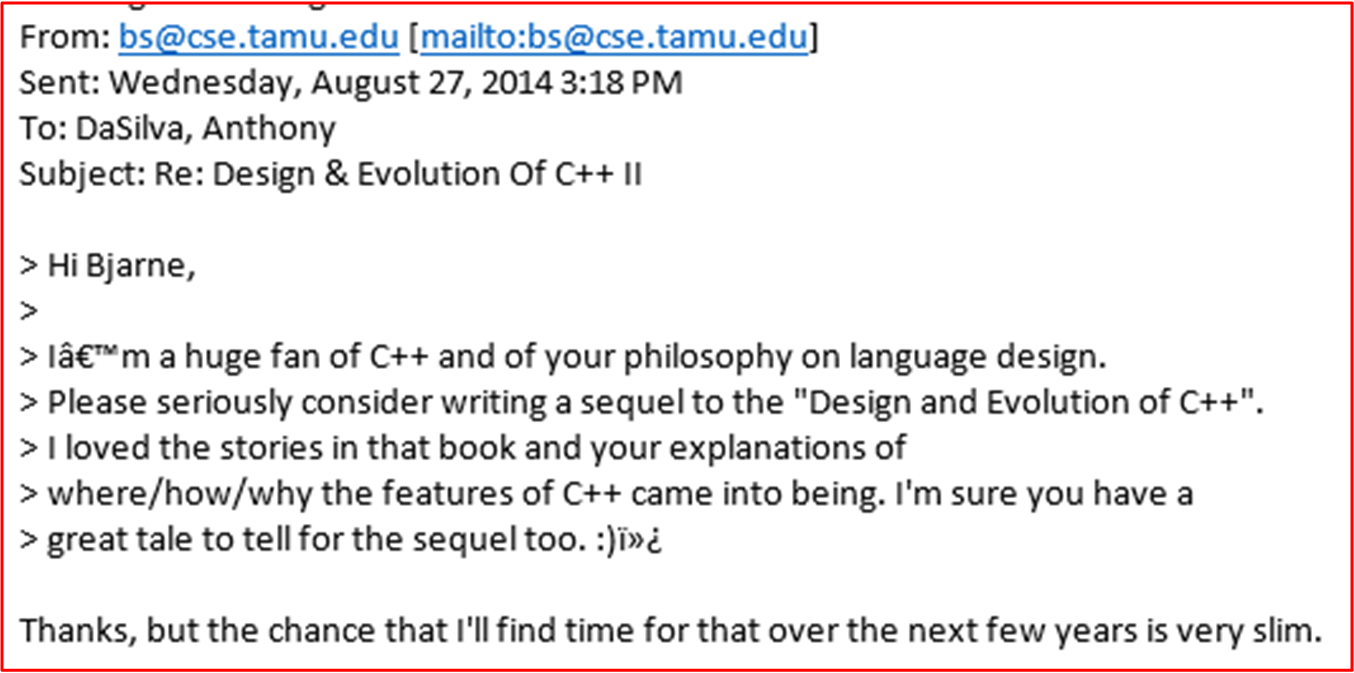
Why not join an e-mail campaign to get Bjarne started on D&E II? So, go ahead. E-mail Bjarne like I did and plead with him to start penning the sequel. The 20 year trek from 1994 to 2014 has got to be filled with as many great “hows” and “whys” as D&E I.
A Grand Introduction
We should not be ashamed of bits. We should be proud of them. – Alex Stepanov
You may not interpret it in the same way as I did, but I found this cppcon conference introduction of Bjarne Stroustrup by programming scholar Alex Stepanov very moving:
Are you ashamed of bits, addresses, and being faithful to the machine? I’m not.

Multiple, Independent Sources Of Information On The Same Topic
I can’t rave enough about how great a safaribooksonline.com subscription is for writing code. Take a look at this screenshot:
As you can hopefully make out, I have five Firefox tabs open to the following C++11 programming books:
- The C++ Programming Language, 4th Edition – Bjarne Stroustrup
- The C++ Standard Library: A Tutorial and Reference (2nd Edition) – Nicolai M. Josuttis
- C++ Primer Plus (6th Edition) – Stephen Prata
- C++ Primer (5th Edition) – Stanley B. Lippman, Josée Lajoie, Barbara E. Moo
- C++ Concurrency in Action: Practical Multithreading – Anthony Williams
A subscription is a bit pricey, but if you can afford it, I highly recommend buying one. You’ll not only write better code faster, you’ll amplify your learning experience by an order of magnitude from having the capability to effortlessly switch between multiple, independent sources of information on the same topic. W00t!
Game Changer
Even though I’m a huge fan of the man, I was quite skeptical when I heard Bjarne Stroustrup enunciate: “C++ feels like a new language“. Of course, Bjarne was talking about the improvements brought into the language by the C++11 standard.
Well, after writing C++11 production code for almost 2 years now (17 straight sprints to be exact), I’m no longer skeptical. I find myself writing code more fluidly, doing battle with the problem “gotchas” instead of both the problem and the language gotchas. I don’t have to veer off track to look up language technical details and easily forgotten best-practices nearly as often as I did in the pre-C++11 era.
It seems that the authors of the “High Integrity C++” coding standard agree with my assessment. In a white paper summarizing the changes to their coding standard, here is what they have to say:

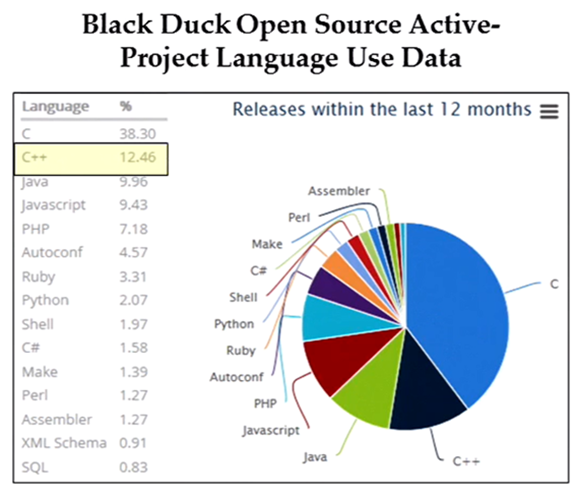
Even though C++’s market niche has shrunk considerably in the 21st century, it is still widely used throughout the industry. The following chart, courtesy of Scott Meyers’ recent talk at Facebook, shows that the old-timer still has legs. The pending C++14 and C++17 updates virtually guarantee its relevance far into the future; just like the venerable paper clip and spring-loaded mouse trap.
FUNGENOOP Programming
As you might know, the word “paradigm” and the concept of a “paradigm shift” were made insanely famous by Thomas Kuhn’s classic book: “The Structure Of Scientific Revolutions“. Mr. Kuhn’s premise is that science only advances via a progression of funerals. An old, inaccurate view of the world gets supplanted by a new, accurate view only when the powerfully entrenched supporters of the old view literally die off. The implication is that a paradigm shift is a binary, black and white event. The old stuff has been proven “wrong“, so you’re compelled to totally ditch it for the new “right” stuff – lest you be ostracized for being out of touch with reality.
In his recent talks on C++, Bjarne Stroustrup always sets aside a couple of minutes to go off on a mini-rant against “paradigm shifts“. Even though Einstein’s theory of relativity subsumes Newton’s classical physics, Newtonian physics is still extremely useful to practicing engineers. The discovery of multiplication/division did not make addition/subtraction useless. Likewise, in the programming world, the meteoric rise of the “object-oriented” programming style (and more recently, the “functional” programming style) did not render “procedural” and/or “generic” programming techniques totally useless.
This slide below is Bjarne’s cue to go off on his anti-paradigm rant.

If the system programming problem you’re trying to solve maps perfectly into a hierarchy of classes, then by all means use a OOP-centric language; perhaps Java, Smalltalk? If statefulness is not a natural part of your problem domain, then preclude its use by using something like Haskell. If you’re writing algorithmically simple but arcanely detailed device drivers that directly read/write hardware registers and FIFOs, then perhaps use procedural C. Otherwise, seriously think about using C++ to mix and match programmimg techniques in the most elegant and efficient way to attack your “multi-paradigm” system problem. FUNGENOOP (FUNctional + GENeric + Object Oriented + Procedural) programming rules!

Stopping The Spew!
Every C++ programmer has experienced at least one, and most probably many, “Template Spew” (TS) moments. You know you’ve triggered a TS moment when, just after hitting the compile button on a program the compiler deems TS-worthy, you helplessly watch an undecipherable avalanche of error messages zoom down your screen at the speed of light. It is rumored that some novices who’ve experienced TS for the very first time have instantaneously entered a permanent catatonic state of unresponsiveness. It’s even said that some poor souls have swan-dived off of bridges to untimely deaths after having seen such carnage.
Note: The graphic image that follows may be highly disturbing. You may want to stop reading this post at this point and continue to waste company time by surfing over to facebook, reddit, etc.
TS occurs when one tries to use a templated class object or function template with a template parameter type that doesn’t provide the behavior “assumed” by the class or function. TS is such a scourge in the C++ world that guru Scott Meyers dedicates a whole item in “Effective STL“, number 49, to handling the trauma associated with deciphering TS gobbledygook.
For those who’ve never seen TS output, here is a woefully contrived example:

The above example doesn’t do justice to the havoc the mighty TS dragon can wreak on the mind because the problem (std::vector<T> requires its template arg to provide a copy assignment function definition) can actually be inferred from a couple of key lines in the sea of TS text.
Ok, enough doom and gloom. Fear not, because help is on the way via C++14 in the form of “concepts lite“. A “concept” is simply a predicate evaluated on a template argument at compile time. If you employ them while writing a template, you inform the compiler of what kind(s) of behavior your template requires from its argument(s). As a use case illustration, behold this slide from Bjarne Stroustrup:

The “concept” being highlighted in this example is “Sortable“. Once the compiler knows that the sort<T> function requires its template argument to be “Sortable“, it checks that the argument type is indeed sortable. If not, the error message it emits will be something short, sweet, and to the point.
The concept of “concepts” has a long and sordid history. A lot of work was performed on the feature during the development of the C++11 specification. However, according to Mr. Stroustrup, the result was overly complicated (concept maps, new syntax, scope & lookup issues). Thus, the C++ standards committee decided to controversially sh*tcan the work:
C++11 attempt at concepts: 70 pages of description, 130 concepts – we blew it!
After regrouping and getting their act together, the committee whittled down the number of pages and concepts to something manageable enough (approximately 7 pages and 13 concepts) to introduce into C++14. Hence, the “concepts lite” label. Hopefully, it won’t be long before the TS dragon is relegated back to the dungeon from whence it came.
Context Sensitive Keywords
Update: Thanks to Chris’s insightful comment, the title of this post should have been “Context Sensitive Identifiers“. “override” and “final” are not C++ keywords; they are identifiers with special meaning.
If maintaining backward compatibility is important, then introducing a new keyword into a programming language is always a serious affair. Introducing a new keyword that is already used in millions of lines of existing code as an identifier (class name, namespace name, variable name, etc), can break a lot of product code and discourage people from upgrading their compilers and using the new language/library features.
Unlike other languages, backward compatibility is a “feature” (not a “meh“) in C++. Thus, the proposed introduction of a new keyword is highly scrutinized by the standards committee when core language improvements are considered. This is the main reason why the verbosity-reducing “auto” keyword wasn’t added until the C++11 standard was hatched.
Even though Bjarne Stroustrup designed/implemented “auto” in C++ over 30 years ago to provide for convenient compiler type deduction, the priority for backward compatibility with C caused it to be sh*t-canned for decades. However, since (hopefully) nobody uses it in C code anymore (“auto” is the default storage type for all C local variables – so why be redundant?), the time was deemed right to include it in the C++11 release. Of course, some really, really old C/C++ code will get broken when compiled under a new C++11 compiler, but the breakage won’t be as dire as if “auto” had made it into the earlier C++98 or C++03 standards.
With the seriousness of keyword introduction in mind, one might wonder why the “override” and “final” keywords were added to C++11. Surely, they’re so common that millions of lines of C/C++ legacy code will get broken. D’oh!
But wait! To severely limit code-breakage, the “override” and “final” keywords are defined to be context sensitive. Unless they’re used in a purposefully narrow, position-specific way, C++11 compilers will reject the source code that contains them.
The “final” keyword (used to explicitly prevent further inheritance and/or virtual function overriding) can only be used to qualify a class definition or a virtual function declaration. The closely related “override” keyword (used to prevent careless mistakes when declaring a virtual function) can only be used to qualify a virtual function. The figure below shows how “final” and “override” clarify programmer intention and prevent accidental mistakes.



Because of the context-specific constraints imposed on the “final” and “override” keywords, this (crappy) code compiles fine:

The point of this last code fragment is to show that the introduction of context-specific keywords is highly unlikely to break existing code. And that’s a good thing.
Periodic Processing With Standard C++11 Facilities
With the addition of the <chrono> and <thread> libraries to the C++11 standard library, programs that require precise, time-synchronized functionality can now be written without having to include any external, non-standard libraries (ACE, Boost, Poco, pthread, etc) into the development environment. However, learning and using the new APIs correctly can be a non-trivial undertaking. But, there’s a reason for having these rich and powerful APIs:
The time facilities are intended to efficiently support uses deep in the system; they do not provide convenience facilities to help you maintain your social calendar. In fact, the time facilities originated with the stringent needs of high-energy physics. Furthermore, language facilities for dealing with short time spans (e.g., nanoseconds) must not themselves take significant time. Consequently, the <chrono> facilities are not simple, but many uses of those facilities can be very simple. – Bjarne Stroustrup (The C++ Programming Language, Fourth Edition).
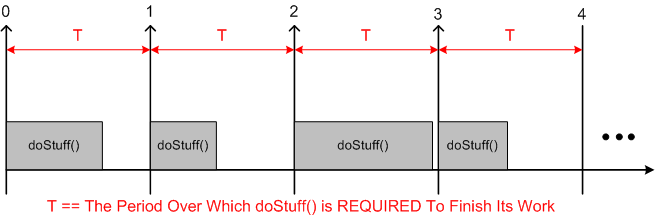
Many soft and hard real-time applications require chunks of work to be done at precise, periodic intervals during run-time. The figure below models such a program. At the start of each fixed time interval T, “doStuff()” is invoked to perform an application-specific unit of work. Upon completion of the work, the program (or task/thread) “sleeps” under the care of the OS until the next interval start time occurs. If the chunk of work doesn’t complete before the next interval starts, or accurate, interval-to-interval periodicity is not maintained during operation, then the program is deemed to have “failed“. Whether the failure is catastrophic or merely a recoverable blip is application-specific.
Although the C++11 time facilities support time and duration manipulations down to the nanosecond level of precision, the actual accuracy of code that employs the API is a function of the precision and accuracy of the underlying hardware and OS platform. The C++11 API simply serves as a standard, portable bridge between the coder and the platform.
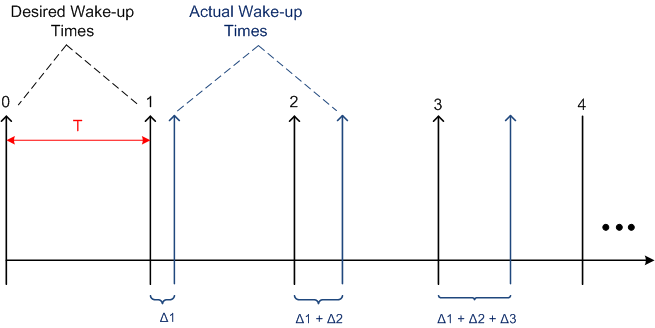
The figure below shows the effect of platform inaccuracy on programs that need to maintain a fixed, periodic timeline. Instead of “waking up” at perfectly constant intervals of T, some jitter is introduced by the platform. If the jitter is not compensated for, the program will cumulatively drift further and further away from “real-time” as it runs. Even if jitter compensation is applied on an interval by interval basis to prevent drift-creep, there will always be some time inaccuracy present in the application due to the hardware and OS limitations. Again, the specific application dictates whether the timing inaccuracy is catastrophic or merely a nuisance to be ignored.
The simple UML activity diagram below shows the cruxt of what must be done to measure the “wake-up error” on a given platform.

On each pass through the loop:
- The OS wakes us up (via <thread>)
- We retrieve the current time (via <chrono>)
- We compute the error between the current time and the desired time (via <chrono>)
- We compute the next desired wake-up time (via <chrono>)
- We tell the OS to put us to sleep until the desired wake-up time occurs (via <thread>)
For your viewing and critiquing pleasure, the source code for a simple, portable C++11 program that measures average “wakeup error” is shown here:

The figure below shows the results from a typical program run on a Win7 (VC++13) and Linux (GCC 4.7.2) platform. Note that the clock precision on the two platforms are different. Also note that in the worst case, the 100 millisecond period I randomly chose for the run is maintained to within an average of .1 percent over the 30 second test run. Of course, your mileage may vary depending on your platform specifics and what other services/daemons are running on that platform.

The purpose of writing and running this test program was not to come up with some definitive, quantitative results. It was simply to learn and play around with the <chrono> and <thread> APIs; and to discover how qualitatively well the software and hardware stacks can accommodate software components that require doing chunks of work on fixed, periodic, time boundaries.
In case anyone wants to take the source code and run with it, I’ve attached it to the site as a pdf: periodicTask.pdf. You could simulate chunks of work being done within each interval by placing a std::this_thread::sleep_for() within the std::this_thread::sleep_until() loop. You could elevate numLoops and intervalPeriodMillis from compile time constants to command line arguments. You can use std::minmax_element() on the wakeup error samples.
Staying Sane
Standardization is long periods of mind-numbing boredom interrupted by moments of sheer terror – Bjarne Stroustrup
In his ACCU2013 talk, “C++14 Early Thoughts“, Bjarne Stroustrup presented this slide:

By using “we” in each bullet point, Bjarne was referring to the ISO WG-1 C++ committee and the daunting challenges it faces to successfully move the language forward.
Not only do the committee leaders have to manage the external onslaught of demands from a huge, dedicated user base, they have to homogenize the internal communications amongst many smart and assertive members. To illustrate the internal management problem, Bjarne said something akin to: “There is no topic the committee isn’t willing to discuss at length for two years“.

In order to prevent being overwhelmed with work, the committee uses this set of grass roots principles to filter out the incoming chaff from the wheat:

I have no idea how internal conflicts are handled, nor how infinite loops of technical debate are exited, but since the all-volunteer committee is still functioning and doing a great job (IMO) of modernizing the language, there’s got to be some magic at work here:

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

