Not Just Expert Friendly
Check out this snippet from one of Bjarne Stroustrup’s CppCon keynote slides:

Now take a glance at one of Herb Sutter’s CppCon talk slides:

Bjarne’s talk was titled “Make Simple Tasks Simple” and Herb’s talk was tiled “Back To The Basics!: Modern C++ Style“. Since I abhor unessential complexity, I absolutely love the fact that these two dedicated gentlemen are spearheading the effort to evolve C++ in two directions simultaneously: increasing both expert-friendliness AND novice-friendliness.
By counterbalancing the introduction of advanced features like variadic templates and forwarding references with simpler features like range-for loops, nullptr, and brace-initialization, I think Bjarne and Herb (and perhaps other community members I don’t know about) are marvelously succeeding at the monumental task of herding cats. To understand what I mean, take a look at another one of Herb’s slides:
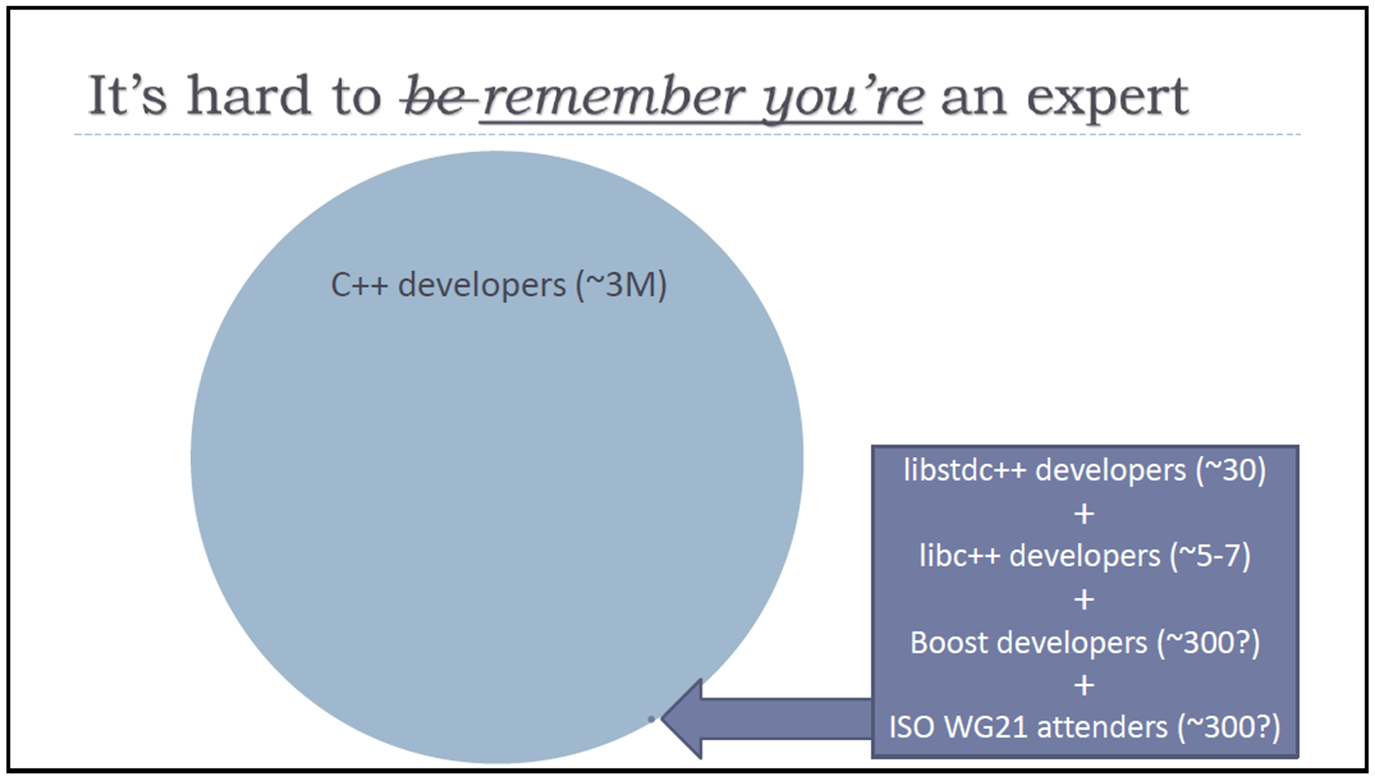
Do you see that teeny tiny dot at the end of the big arrow down on the lower right edge of the circle? Well, I don’t come anywhere close to qualifying for membership with the cats inside that dot… and I’d speculate that most advanced feature proposals and idiom ideas, whether they are understandable/teachable to mere mortals or not, originate from the really smart cats within that dot.

By gently but doggedly communicating the need for lowering the barriers to entry for potentially new C++ users while still navigating the language forward into unchartered waters, I’m grateful to Herb and Bjarne. Because of these men, the ISO C++ committee actually works – and it is indeed amazing for any committee to “work“.
On The Origin Of Features
Thanks to an angel on the blog staff at the ISO C++ web site, my last C++ post garnered quite a few hits that were sourced from that site. Thus, I’m following it up with another post based on the content of Bjarne Stroustrup’s brilliant and intimate book, “The Design And Evolution Of C++“.
The drawing below was generated from a larger, historical languages chart provided by Bjarne in D&E. It reminds me of a couple of insightful quotes:
“Complex systems will evolve from simple systems much more rapidly if there are stable intermediate forms than if there are not.” — Simon, H. 1982. The Sciences of the Artificial.
“A complex system that works is invariably found to have evolved from a simple system that worked… A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over, beginning with a working simple system.” — Gall, J. 1986. Systemantics: How Systems Really Work and How They Fail.
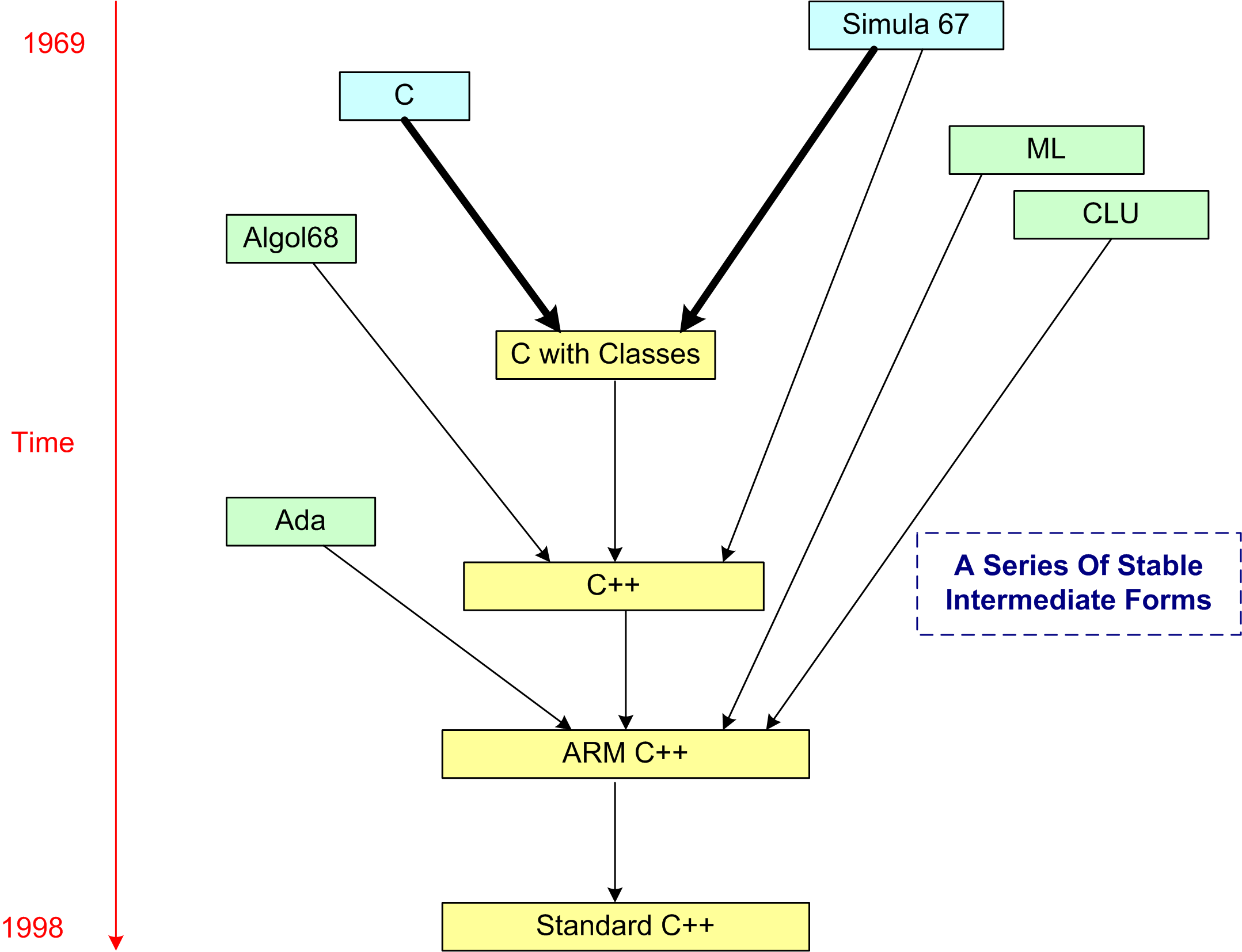
A we can see from the figure, “Simula67” and “C” were the ultimate ancestral parents of the C++ programming language. Actually, as detailed in my last post, “frustration” and “unwavering conviction” were the true parents of creation, but they’re not languages so they don’t show up on the chart. 🙂
To complement the language-lineage figure, I compiled this table of early C++ features and their origins from D&E:
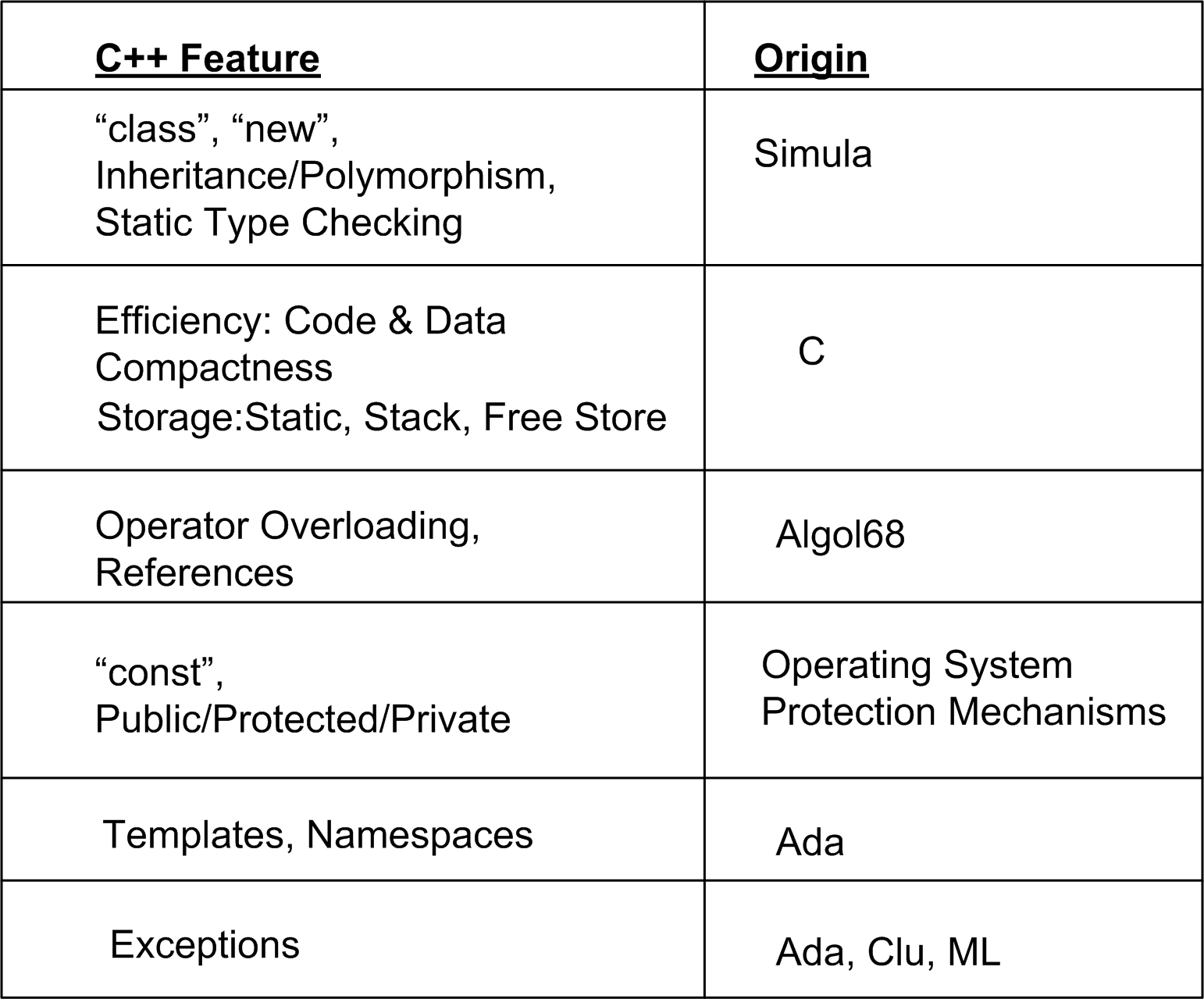
Finally, if you were wondering what Mr. Stroustrup’s personal feature-filtering criteria were (and still are 30+ years later!), here is the list:

If you consider yourself a dedicated C++ programmer who has never read D&E and my latest 2 posts haven’t convinced you to buy the book, then, well, you might not be a dedicated C++ programmer.
And In The Beginning…
I’m on my second pass through Bjarne Stroustrup’s “The Design And Evolution Of C++“. In the book, which was published exactly 20 years ago in 1994, Bjarne discloses all of the “whys” and “hows” that drove the growth of C++ up to the time of the book’s publication.
In the beginning, before there was C++ there was the even-more-nerdly-named “C With Classes” (CWC). Bjarne’s motivation for creating CWC was, as many inventions are, rooted in frustration:
This was exactly the kind of problem that I had become determined never again to attack without the proper tools. – Bjarne Stroustrup
The problem Bjarne refers to in the above quote was: “the task of exploring if/how the UNIX kernel could be distributed over a network of LAN-connected computers“. The preceding “never again” problem was for achieving his Ph.D. thesis at Cambridge University: “to study alternatives for the organization of system software for distributed systems“. Notice how the word “distributed” appears in both problems – and this was way back in the 70’s when bell bottoms were in fashion and prior to the rise of multi-core processor technology.

Even though he didn’t say why he chose the tool for his Cambridge Ph.D. thesis project, Bjarne used Nygaard and Dahl’s Simula programming language to code up a program for “simulating software running on a distributed system“. If you already know the history of C++, you won’t be surprised at Bjarne’s feelings for Simula or why he imported some of its key features into CWC:
It was a pleasure to write that simulator. The features of Simula were almost ideal for the purpose, and I was particularly impressed by the way the concepts of the language helped me think about the problems in my application. The class concept allowed me to map my application concepts into the language constructs in a direct way that made my code more readable than I had seen in any other language. The way Simula classes can act as co-routines made the inherent concurrency of my application easy to express.
Class hierarchies were used to express variants of application-level concepts. The use of class hierarchies was not heavy, though; the use of classes to express concurrency was much more important in the organization of my simulator.
During writing and initial debugging, I acquired a great respect for the expressiveness of Simula’s type system and its compiler’s ability to catch type errors.
In the above book quotes, we see the “whys” for:
- The appearance of the “Classes” word in “C With Classes“.
- CWC’s’s support for an object oriented programming style
- CWC’s static type system.
In contrast to Simula’s elegant expressiveness, its compile time and runtime performance were abysmal (garbage collection + runtime type checking + built-in concurrency = slooow). The runtime performance was so poor that Bjarne had to rewrite his simulator in low-level BPCL at the last second in order to get any meaningful results out of the program to stuff into his Ph.D. thesis.
Although there were several other pragmatic reasons for the appearance of the “C” in “C With Classes” (flexibility, ubiquity of available compilers, direct mapping of data to the hardware, simple linkage and runtime systems), performance ultimately drove the decision to use the well known and proven C language as ground zero for CWC – despite its funky syntactic quirks and unsafe features.
Curiously, support for concurrency was provided in CWC’s very first library in 1980. Concurrency appeared in the form of a tasking library and built-in support for two special functions recognized by the preprocessor: call() and return(). If defined by the programmer for a class, these functions would get implicitly invoked prior to entry and prior to exit of every class member function except for the constructor/destructor. They were required by the monitor class in the tasking library to acquire and release a lock for precluding data races. Interestingly, the call() and return() functions were later removed because “nobody used them but me“. We’d have to wait until 2011 for concurrency to return to C++ in the form of new libraries.
On exiting this post, I’d like to show you this e-mail exchange with Bjarne regarding the possibility of a book sequel in the near future:
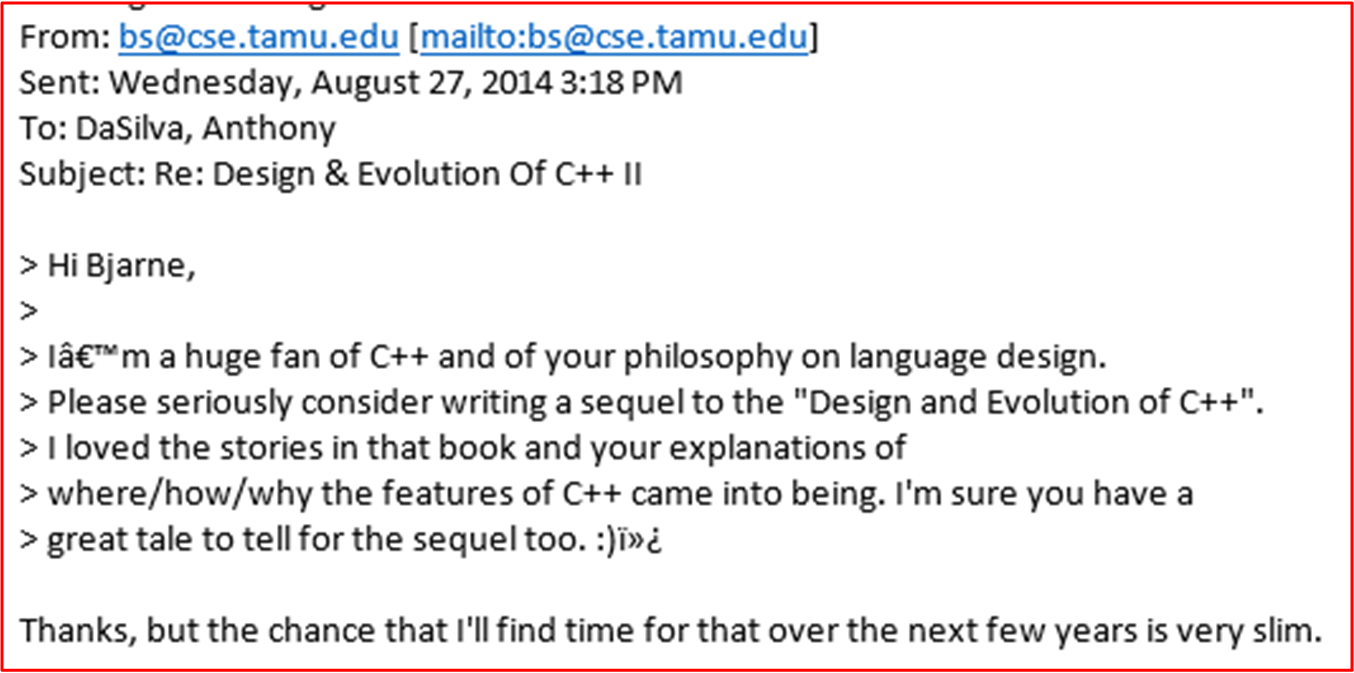
Why not join an e-mail campaign to get Bjarne started on D&E II? So, go ahead. E-mail Bjarne like I did and plead with him to start penning the sequel. The 20 year trek from 1994 to 2014 has got to be filled with as many great “hows” and “whys” as D&E I.
A Grand Introduction
We should not be ashamed of bits. We should be proud of them. – Alex Stepanov
You may not interpret it in the same way as I did, but I found this cppcon conference introduction of Bjarne Stroustrup by programming scholar Alex Stepanov very moving:
Are you ashamed of bits, addresses, and being faithful to the machine? I’m not.

Live Instructor, Or Live Code?
I’m currently taking an in-house course on Java programming. The material is being presented in standard lecture fashion where the instructor sequentially walks through a series of static powerpoint slides and explains what the code snippets on each slide are doing.
In parallel to the in-house class, I’m also taking an online Java video course taught by Paul Deitel in the comfort of my home. The 36 hour course is available to me through my pricey (but outstanding) safaribooksonline subscription:
Other than in the lesson video intros (e.g. the one above), you never see Mr. Deitel on the screen. Like many educational videos you can watch for free on YouTube and Kahn Academy, you see code and a yellow circle highlighter that Paul dynamically steers around the screen as he explains what the code is doing.
Even though the standard “live instructor” teaching method enables the student to ask a physically-present instructor questions in real-time, I find the video “live code” method much more flexible and effective for the following reasons:
- You can see the instructor dynamically interacting with the IDE (in this case Eclipse).
- You can learn at your own speed by replaying lesson snippets that you didn’t fully grasp the first time. (I’m not so smart, so I use this feature all the time).
- The instructor can compile/run the code in front of your eyes and connect the code with its output by switching between the console and the code editor as needed.
- The instructor can intentionally insert bugs in the code and step through the debugger.
- The instructor can switch between the code and detailed online documentation as needed.
Regarding this particular course, I’m thrilled with Mr. Deitel’s work. He’s very thorough, shows great empathy for the student, and he dispassionately points out the differences between Java and C++ as they emerge throughout his code examples.
As I learn more details about Java, I’m confirming what everybody has been saying about the language since its inception: it is a smoother and easier to learn language than C++. However, I (still) don’t like:
- Centralized garbage collection (I prefer C++’s RAII idiom and smart pointers for localized garbage collection).
- The fact that all methods are virtual by default.
- The fact that every user-defined reference type inherits from class Object.
- The fact that a whole other layer of software, the JVM, sits between user code and the operating system.
- The fact that Java” steers” programmers toward designing deep, complicated inheritance hierarchies regardless of whether that style fits the application.
Regarding the last point, the mental steerage toward a pure OO programming style is subliminally catalyzed in the way that the JDK library packages are designed and the proliferation of large frameworks in the Java community. The obsession with deep hierarchies reminds me of Microsoft’s horrendously complicated old MFC framework for writing Windows GUI applications.
I’ve personally seen the effects of a fixed OO mindset in Java programmers who subsequently learn and write C++ production code in my domain: distributed real-time event systems that are naturally “flat“. The code ends up being overly complicated, hard to understand, and very few methods in the deep trees end up being called. The end result is that the “smoothness” of the language is nullified, developer time is wasted on unnecessary code, and the code is hard to maintain.
Spike To Learn
As one of the responsibilities on my last project, I had to interface one of our radars to a 10+ year old, legacy, command-and-control system built by another company. My C++11 code was required to receive commands from the control system and send radar data to it via UDP datagrams over a LAN that connects the two systems together.
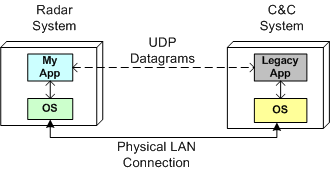
It’s unfortunate, but we won’t get a standard C++ networking library until the next version of the C++ standard gets ratified in 2017. However, instead of using the low-level C sockets API to implement the interface functionality, I chose to use the facilities of the Poco::Net library.

Poco is a portable, well written, and nicely documented set of multi-function, open source C++ libraries. Among other nice, higher level, TCP/IP and http networking functionality, Poco::Net provides a thin wrapper layer around the native OS C-language sockets API.
Since I had never used the Poco::Net API before, I decided to spike off the main trail and write a little test program to learn the API before integrating the API calls directly into my production code. I use the “Spike To Learn” best practice whenever I can.
Here is the finished and prettied-up spike program for your viewing pleasure:
#include <string>
#include <iostream>
#include "Poco/Net/SocketAddress.h"
#include "Poco/Net/DatagramSocket.h"
using Poco::Net::SocketAddress;
using Poco::Net::DatagramSocket;
int main() {
//simulate a UDP legacy app bound to port 15001
SocketAddress legacyNodeAddr{"localhost", 15001};
DatagramSocket legacyApp{legacyNodeAddr}; //create & bind
//simulate my UDP app bound to port 15002
SocketAddress myAddr{"localhost", 15002};
DatagramSocket myApp{myAddr}; //create & bind
//myApp creates & transmits a message
//encapsulated in a UDP datagram to the legacyApp
char myAppTxBuff[]{"Hello legacyApp"};
auto msgSize = sizeof(myAppTxBuff);
myApp.sendTo(myAppTxBuff,
msgSize,
legacyNodeAddr);
//legacyApp receives a message
//from myApp and prints its payload
//to the console
char legacyAppRxBuff[msgSize];
legacyApp.receiveBytes(legacyAppRxBuff, msgSize);
std::cout << std::string{legacyAppRxBuff}
<< std::endl;
//legacyApp creates & transmits a message
//to myApp
char legacyAppTxBuff[]{"Hello myApp!"};
msgSize = sizeof(legacyAppTxBuff);
legacyApp.sendTo(legacyAppTxBuff,
msgSize,
myAddr);
//myApp receives a message
//from legacyApp and prints its payload
//to the console
char myAppRxBuff[msgSize];
myApp.receiveBytes(myAppRxBuff, msgSize);
std::cout << std::string{myAppRxBuff}
<< std::endl;
}
As you can see, I used the Poco::Net::SocketAddress and Poco::Net::DatagramSocket classes to simulate the bi-directional messaging between myApp and the legacyApp on one machine. The code first transmits the text message “Hello legacyApp!” from myApp to the legacyApp; and then it transmits the text message “Hello myApp!” from the legacyApp to myApp.

Lest you think the program doesn’t work 🙂 , here is the console output after the final compile & run cycle:

As a side note, notice that I used C++11 brace-initializers to uniformly initialize every object in the code – except for one: the msgSize object. I had to fallback and use the “=” form of initialization because “auto” does not yet play well with brace-initializers. For who knows why, the type of obj in a statement of the form “auto obj{5};” is deduced to be a std::initializer_list<T> instead of a simple int. I think this strange inconvenience will be fixed in C++17. It may have been fixed already in the recently ratified C++14 standard, but I don’t know for sure. Do you?
Design Disaster
In an attempt to gain an understanding of the software design he was carrying around in his head, I sat down with a colleague and started talking face to face with him. To facilitate the conversation, I started sketching my emergent understanding of his design in my notebook. As you can see, by the time we finished talking, 20 minutes later, I ran out of ink and I wasn’t much better off than before we started the conversation:

If I had a five year old son, I would proudly magnetize my sketch on the fridge right next to his drawings.
Nasty, Non-linear, Inter-variable Couplings
To illustrate the difference between analytical thinking and systems thinking (which some people think are identical), Jamshid Gharajedaghi presents these two figures in his wonderful book: “Systems Thinking: Managing Chaos and Complexity“.

Anyone who has been through high school has been exposed to equations of the type on the left. To discover the impact of one variable, say x1, on the system output, y, you simply vary its value while keeping the values of the other (so-called) independent variables fixed. But what about equations of the type on the right? Every time you attempt to vary the value of one variable to discover its effect on system behavior, you unwittingly “disturb” the values of each of the other variables… which in turn disturbs the variable you’re trying to directly control… which in turn disturbs the set of variables yet again… ad infinitum. It’s called the law of unintended consequences.
Nice and tidy equations of the type on the left are applicable to, and only to, problem modeling in the natural sciences in which the players are time, energy, and mindless chunks of matter. Intractable sets of equations of the type on the right, unsolvable messes in which every variable is correlated which every other variable, are applicable to socio-technical systems where the most influential players have minds of their own. System thinkers focus on the coupling and dynamic interactions between the variables in the system to understand emergent behaviors. Analytical thinkers assume away (either consciously or unconsciously) the nasty, non-linear, inter-variable couplings and thus form an erroneous understanding of the underlying causes of system behavior. Welcome to the guild of business management.
Tuna Quagmire
Although I prolly shoulda kept the ingredients secret, here’s my tuna quagmire before the big mix:

And voila, here’s the tuna quagmire after the mix:

Of course, the very best ingredient, by a wide margin, is the BD00 GIANT MARTINI.
The Angle Bracket Tax
The following C++14 code fragment represents a general message layout along with a specific instantiation of that message:
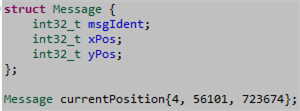
Side note: Why won’t a C++98/03 compiler accept the above code?
Assume that we are “required” to send thousands of these X-Y position messages per second between two computers over a finite bandwidth communication link:
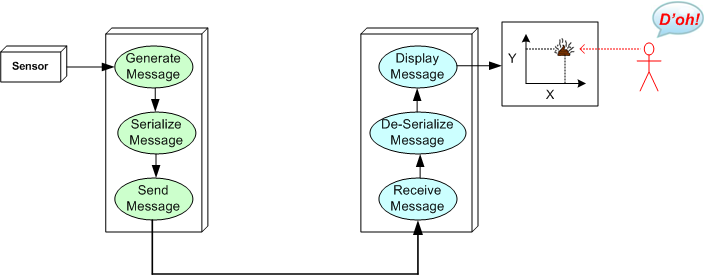
There are many ways we can convert the representation of the message in memory into a serial stream of bytes for transmittal over the communication link, but let’s compare a simple binary representation against an XML equivalent:

The tradeoff is simple: human readability for performance. Even though the XML version is self-describing and readable to a human being, it is 6.5 times larger than the tight, fixed-size, binary format. In addition, the source code required to serialize/deserialize (i.e. marshal/unmarshal) the XML version is computationally denser than the code to implement the same functionality for the fixed-size, binary representation. In the software industry, this tradeoff is affectionately known as “the angle bracket tax” that must be payed for using XML in the critical paths of your system.
If your system requires high rates of throughput and low end-to-end latency for streaming data over a network, you may have no choice but to use a binary format to send/receive messages. After all, what good is it to have human readable messages if the system doesn’t work due to overflowing queues and lost messages?
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

