Archive
The New Software Development Certification Fad
I like Alistair Cockburn‘s work, but I’m bummed. He, like fellow agilist Ken Schwaber, is on a certification kick. You know, like the phony belt colors in six sigma and the levels of “assessment” (<– psuedo-certification) in the CMMI and the “highly coveted” ISO-900X certification cartel.
InfoQ: Interview with Alistair Cockburn.
How well do you think certification/assessment systems have really worked to establish high quality products and services coming out of highly credentialed orgs and individuals? All it is to me is another way to extract snake oil money out of struggling orgs. You see, those few orgs that know how to develop high quality, value-added software products don’t need no stinkin’ certs. Those orgs that repeatedly screw up cuz of CCH mismanagement and misalignment need certs to give themselves a false sense of pride and to temporarily cloak their poor performance. However, when the money’s gone, the time’s gone, and the damn thang don’t work, the truth is revealed.

Greenspun’s Tough Love

In Founders At Work, Phil Greenspun recounts his tough-love approach toward molding his young programmers into well-rounded and multi-talented individuals:
For programmers, I had a vision—partly because I had been teaching programmers at MIT—that I didn’t like the way that programmer careers turned out. I wanted them to have a real professional résumé.
They would have to develop the skill of starting from the problem. They would invest some time in writing up their results. I was very careful about trying to encourage these people to have an independent professional reputation, so there’s code that had their name on it and that they took responsibility for, documentation that explained what problem they were trying to solve, what alternatives they considered, what the strengths and limitations of this particular implementation that they were releasing were, maybe a white paper on what lessons they learned from a project. I tried to get the programmers to write, which they didn’t want to do.
People don’t like to write. It’s hard. The people who were really good software engineers were usually great writers; they had tremendous ability to organize their thoughts and communicate. The people who were sort of average-quality programmers and had trouble thinking about the larger picture were the ones who couldn’t write.
So, did it work? Sadly, Phil follows up with:
In the end, the project was a failure because the industry trends moved away from that. People don’t want programmers to be professionals; they want programmers to be cheap. They want them to be using inefficient tools like C and Java. They just want to get them in India and pay as little as possible. But I think part of the hostility of industrial managers toward programmers comes from the fact that programmers never had been professionals.
Programmers have not been professionals because they haven’t really cared about quality. How many programmers have you asked, “Is this the right way to do things? Is this going to be good for the users?” They reply, “I don’t know and I don’t care. I get paid, I have my cubicle, and the air-conditioning is set at the right temperature. I’m happy as long as the paycheck comes in.”
FAW was published in 2008. Two years later, do you think attitudes have changed much? What’s your attitude?
Yes I do! No You Don’t!
“Jane, you ignorant slut” – Dan Ackroid
In this EETimes post, I Don’t Need No Stinkin’ Requirements, Jon Pearson argues for the commencement of coding and testing before the software requirements are well known and recorded. As a counterpoint, Jack Ganssle wrote this rebuttal: I Desperately Need Stinkin Requirements. Because software industry illuminaries (especially snake oil peddling methodologists) often assume all software applications fit the same mold, it’s important to note that Pearson and Gannsle are making their cases in the context of real-time embedded systems – not web based applications. If you think the same development processes apply in both contexts, then I urge you to question that assumption.
I usually agree with Ganssle on matters of software development, but Pearson also provides a thoughtful argument to start coding as soon as a vague but bounded vision of the global structure and base behavior is formed in your head. On my current project, which is the design and development of a large, distributed real-time sensor that will be embedded within a national infrastructure, a trio of us have started coding, integrating, and testing the infrastructure layer before the application layer requirements have been nailed down to a “comfortable degree of certainty”.
The simple figures below show how we are proceeding at the current moment. The top figure is an astronomically high level, logical view of the pipe-filter archetype that fits the application layer of our system. All processes are multi-threaded and deployable across one or more processor nodes. The bottom figure shows a simplistic 2 layer view of the software architecture and the parallel development effort involving the systems and software engineering teams. Notice that the teams are informally and frequently synchronizing with each other to stay on the same page.

 The main reason we are designing and coding up the infrastructure while the application layer requirements are in flux is that we want to measure important cross-cutting concerns like end-to-end latency, processor loading, and fault tolerance performance before the application layer functionality gets burned into a specific architecture.
The main reason we are designing and coding up the infrastructure while the application layer requirements are in flux is that we want to measure important cross-cutting concerns like end-to-end latency, processor loading, and fault tolerance performance before the application layer functionality gets burned into a specific architecture.
So, do you think our approach is wasteful? Will it cause massive, downstream rework that could have been avoided if we held off and waited for the requirements to become stable?
To Call, Or To Be Called. THAT Is The Question.
Except for GUIs, I prefer not to use frameworks for application software development. I simply don’t like to be the controllee. I like to be the controller; to be on top so to speak. I don’t like to be called; I’d rather call.
The UML figure below shows a simple class diagram and sequence diagram pair that illustrate how a typical framework and an application interact. On initialization, your code has to install a bunch of CallBack (CB) functions or objects into the framework. After initialization, your code then waits to be called by the framework with information on Events (E) that you’re interested in processing. You’re code is subservient to the Framework Gods.

After object oriented inheritance and programming by difference, frameworks were supposed to be the next silver bullet in software reuse. Well crafted, niche-based frameworks have their place of course, but they’re not the rage they once were in the 90s. A problem with frameworks, especially homegrown ones, is that in order to be all things to all people, they are often bloated beyond recognition and require steep learning curves. They also often place too much constraint on application developers while at the same time not providing necessary low level functionality that the application developer ends up having to write him/herself. Finding out what you can and can’t do under the “inverted control” structure of a framework is often an exercise in frustration. On the other hand, a framework imposes order and consistency across the set of applications written to conform to it’s operating rules; a boon to keeping maintenance costs down.
The alternative to a framework is a set of interrelated, but not too closely coupled, application domain libraries that the programmer (that’s you and me) can choose from. The UML class and sequence diagram pair below shows how application code interacts with a set of needed and wanted support libraries. Notice who’s on top.
 How about you? Do you like to be on top? What has been your experience working with non-GUI application frameworks? How about system-wide frameworks like CORBA or J2EE?
How about you? Do you like to be on top? What has been your experience working with non-GUI application frameworks? How about system-wide frameworks like CORBA or J2EE?
Wishful And Realistic
As software development orgs grow, they necessarily take on larger and larger projects to fill the revenue coffers required to sustain the growth. Naturally, before embarking on a new project, somebody’s gotta estimate how much time it will take and how many people will be needed to get it done in that guesstimated time.
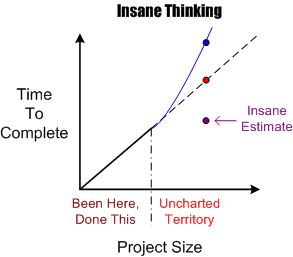
The figure below shows an example of the dumbass linear projection technique of guesstimation. Given a set of past performance time-size data points, a wishful estimate for a new and bigger project is linearly extrapolated forward via a neat and tidy, mechanistic, textbook approach. Of course, BMs, DICs, and customers all know from bitter personal experience that this method is bogus. Everyone knows that software projects don’t scale linearly, but (naturally) no one speaks up out of fear of gettin’ their psychological ass kicked by the pope du jour. Everyone wants to be perceived as a “team” player, so each individual keeps their trap shut to avoid the ostracism, isolation, and pariah-dom that comes with attempting to break from clanthink unanimity. Plus, even though everyone knows that the wishful estimate is an hallucination, no one has a clue of what it will really take to get the job done. Hell, no one even knows how to define and articulate what done means. D’oh! (Notice the little purple point in the lower right portion of the graph. I won’t even explain its presence because you can easily figure out why it’s there.)
 OK, you say, so what works better Mr. Smarty-Pants? Since no one knows with any degree of certainty what it will take to “just get it done” (<- tough management speak – lol!) nothing really works in the absolute sense, but there are some techniques that work better than the standard wishful/insane projection technique. But of course, deviation from the norm is unacceptable, so you may as well stop reading here and go back about your b’ness.
OK, you say, so what works better Mr. Smarty-Pants? Since no one knows with any degree of certainty what it will take to “just get it done” (<- tough management speak – lol!) nothing really works in the absolute sense, but there are some techniques that work better than the standard wishful/insane projection technique. But of course, deviation from the norm is unacceptable, so you may as well stop reading here and go back about your b’ness.
One such better, but forbidden, way to estimate how much time is needed to complete a large hairball software development project is shown below. A more realistic estimate can be obtained by assuming an exponential growth in complexity and associated time-to-complete with increasing project size. The trick is in conjuring up values for the constant K and exponent M. Hell, it requires trickery to even come up with an accurate estimate of the size of the project; be it function points, lines of code, number of requirements or any other academically derived metric.

An even more effective way of estimating a more accurate TTC is to leverage the dynamic learning (gasp!) that takes place the minute the project execution clock starts tickin’. Learning? Leverage learning? No mechanistic equations based on unquantifiable variables? WTF is he talkin’ bout? He’s kiddin’ right?

Continuous Turd Cleanup
Everyone knows that continuous refactoring of the source code is required to keep your code base clean. However, what about continuous cleanup of turd files? Do you iteratively do this unglamorous, janitorial task?
As you develop software and learn how to use one of the exotic new build systems like the autotools set, you will most likely find a bunch of project build files accumulating that are no longer needed. These files will clutter up your source control repository tree and frustrate project newcomers; starting them off with a “bad attitude” toward you and the other people who’ve “laid the groundwork” for them.

If you can’t find the time to diligently keep your source tree clean (“I am too busy!”), then you deserve what you get from your future team mates: disdain and disrespect.
WHAT WE HAVE DONE FOR OURSELVES ALONE DIES WITH US; WHAT WE HAVE DONE FOR OTHERS AND THE WORLD REMAINS AND IS IMMORTAL. – Dan Brown
Cleanliness And Understandability
While adding code to our component library framework yesterday, a colleague and myself concocted a 2 attribute quality system for evaluating source code:
 When subjectively evaluating the cleanliness attribute of a chunk of code, we pretty much agree on whether it is clean or dirty. The trouble is our difference in evaluating understandability. My obfuscated is his simple. Bummer.
When subjectively evaluating the cleanliness attribute of a chunk of code, we pretty much agree on whether it is clean or dirty. The trouble is our difference in evaluating understandability. My obfuscated is his simple. Bummer.
Anomalously Huge Discrepancies
I’m currently having a blast working on the design and development of a distributed, multi-process, multi-threaded, real-time, software system with a small core group of seasoned developers. The system is being constructed and tested on both a Sparc-Solaris 10 server and an Intel-Ubuntu Linux 2.6.x server. As we add functionality and grow the system via an incremental, “chunked” development process, we’re finding anomalously huge discrepancies in system build times between the two platforms.
The table below quantifies what the team has been qualitatively experiencing over the past few months. Originally, our primary build and integration machine was the Solaris 10 server. However, we quickly switched over to the Linux server as soon as we started noticing the performance difference. Now, we only build and test on the Solaris 10 server when we absolutely have to.

The baffling aspect of the situation is that even though the CPU core clock speed difference is only a factor of 2 between the servers, the build time difference is greater than a factor of 5 in favor of the ‘nix box. In addition, we’ve noticed big CPU loading performance differences when we run and test our multi-process, multi-threaded application on the servers – despite the fact that the Sun server has 32, 1.2 GHz, hardware threads to the ‘nix server’s 2, 2.4 GHz, hardware threads. I know there are many hidden hardware and software variables involved, but is Linux that much faster than Solaris? Got any ideas/answers to help me understand WTF is going on here?
Exaggerated And Distorted
The figure below provides a UML class diagram (“class” is such an appropriate word for this blarticle) model of the Manager-Developer relationship in most software development orgs around the globe. The model is so ubiquitous that you can replace the “Developer” class with a more generic “Knowledge Worker” class. Only the Code(), Test(), and Integrate() behaviors in the “Developer” class need to be modified for increased global applicability.

Everyone knows that this current model of developing software leads to schedule and cost overruns. The bigger the project, the bigger the overruns. D’oh!
In this article and this interview, Watts Humphrey trumps up his Team Software Process (TSP) as the cure for the disease. The figure below depicts an exaggerated and distorted model of the manger-developer relationship in Watts’s TSP. Of course, it’s an exaggerated and distorted view because it sprang forth from my twisted and tortured mind. Watts says, and I wholeheartedly agree (I really do!), that the only way to fix the dysfunction bred by the current way of doing things is to push the management activities out of the Manager class and down into the Developer class (can you say “empowerment”, sic?). But wait. What’s wrong with this picture? Is it so distorted and exaggerated that there’s not one grain of truth in it? Decide for yourself.

Even if my model is “corrected” by Watts himself so that the Manager class actually adds value to the revolutionary TSP-based system, do you think it’s pragmatically workable in any org structured as a CCH? Besides reallocating the control tasks from Manager to Developer, is there anything that needs to socially change for the new system to have a chance of decreasing schedule and cost overruns (hint: reallocation of stature and respect)? What about the reward and compensation system? Does that need to change (hint: increased workload/responsibility on one side and decreased workload/responsibility on the other)? How many orgs do you know of that aren’t structured as a crystalized CCH?
Strangely (or not?), Watts doesn’t seem to address these social system implications of his TSP. Maybe he does, but I just haven’t seen his explanations.
Double Whammy
Five Principles
Watts Humphrey is perhaps the most decorated and credentialed member of the software engineering community. Even though his project management philosophy is a tad too rigidly disciplined for me, the dude is 83 years young and he has obtained eons of experience developing all kinds of big, scary, software-intensive systems. Thus, he’s got a lot of wisdom to share and he’s definitely worth listening to.
In “Why Can’t We Manage Large Projects?“, Watts lists the following principles as absolutely necessary for the prevention of major cost and time overruns on knowledge-intensive projects – big and small.

Since nobody’s perfect (except for me — and you?), all tidy packages of advice contain both fluff and substance. The 5 point list above is no different. Numbers 1, 4 and 5, for example, are real motherhood and apple pie yawners – no? However, numbers 2 and 3 contain some substance.
Trustworthy Teams
Number 2 is intriguing to me because it moves the screwup spotlight away from the usual suspects (BMs of course), and onto the DICforce. Watt’s (rightly) says that DIC-teams must be willing to manage themselves. Later in his article, Watts states:
To truly manage themselves, the knowledge workers… must be held responsible for producing their own plans, negotiating their own commitments, and meeting these commitments with quality products.
Now, here’s the killer double whammy:
Knowledge worker DIC-types don’t want to do management work (planning, measuring, watching, controlling, evaluating), and BMs don’t want to give it up to them. – Bulldozer00
Besides disliking the nature of the work, the members of the DICforce know they won’t be rewarded or given higher status in the hierarchy for taking on the extra workload of planning, measuring, and status taking. Adding salt to the wound, BMs won’t give up their PWCE “job” responsibilities because then it would (rightfully) look like they’re worthless to their bosses in the new scheme of things. Bummer, no?

Facts And Data
As long as orgs remain structured as stratified hierarchies (which for all practical purposes will be forever unless an act of god occurs), Watts’s noble number 3 may never take hold. Ignoring facts/data and relying on seniority/status to make decisions is baked into the design of CCHs, and it always will be.
It’s the structure, stupid! – Bulldozer00
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address


{kind=link}