Archive
Components, Namespaces, Libraries

Regardless of which methodology you use to develop software, the following technical allocation chain must occur to arrive at working source code from some form of requirements:

The figure below shows a 2/6/13 end result of the allocation chain for a hypothetical example project. How the 2/6/13 combo was arrived at is person and domain-specific. Given the same set of requirements to N different, domain-knowledgeable people, N different designs will no doubt be generated. Person A may create a 3/6/9 design and person B may conjure up 4/8/16 design.

Given a set of static or evolving requirements, how should one allocate components to namespaces and libraries? The figure below shows extreme 1/1/13 and 13/13/13 cases for our hypothetical 13 component example.
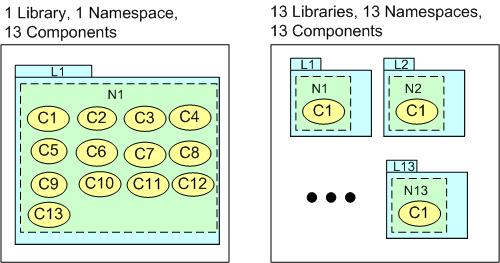
As the number of components, N, in the system design gets larger, the mindless N/N/N strategy becomes unscalable because of an increasing dependency management nightmare. In addition to deciding which K logical components to use in their application, library users must link all K physical libraries with their application code. In the mindless 1/1/N strategy, only one library must be linked with the application code, but because of the single namespace, the design may be harder to logically comprehend.
Expectedly, the solution to the allocation problem lies somewhere in between the two extremes. Arriving at an elegant architecture/design requires a proactive effort with some upfront design thinking. Domain knowledge and skillful application of the coupling-cohesion heuristic can do the trick. For large scale systems, letting a design emerge won’t.
Emergent design works in nature because evolution has had the luxury of millions of years to get it “right“. Even so, according to angry atheist Richard Dawkins, approximately 99% of all “deployed” species have gone extinct – that’s a lot of failed projects. In software development efforts, we don’t have the luxury of million year schedules or the patience for endless, random tinkering.
Alternative Considerations
Before you unquestioningly accept the gospel of the “evolutionary architecture” and “emergent design” priesthood, please at least pause to consider these admonitions:
Give me six hours to chop down a tree and I will spend the first four sharpening the axe – Abe Lincoln
Measure twice, cut once – Unknown
If I had an hour to save the world, I would spend 59 minutes defining the problem and one minute finding solutions – Albert Einstein
100% test coverage is insufficient. 35% of the faults are missing logic paths – Robert Glass

Intimately Bound
Out of the bazillions of definitions of “software architecture” out in the wild, my favorite is:
“the initial set of decisions that are costly to change downstream“.
It’s my fave because it encompasses the “whole” product development ecosystem and not just the structure and behavior of the product itself. Here are some example decisions that come to mind:
- Programming language(s)
- Third party libraries
- Architectural pattern/style
- Build system selection
- Targeted operating system(s)
- Version control system
- Automated testing framework
- Communication middleware
- GUI framework
- Requirements management tool
- Non-functional requirements (latency, throughput, availability, security, safety)
- Development process
Once your production code gets intimately bound with the set of items on the list, there comes a point of no return on the project timeline where changing any of them is pragmatically impossible. Once this mysterious time threshold is crossed, changing the product source code may be easier than changing anything else on the list.

Got any other items to add to the list?
Our Stack
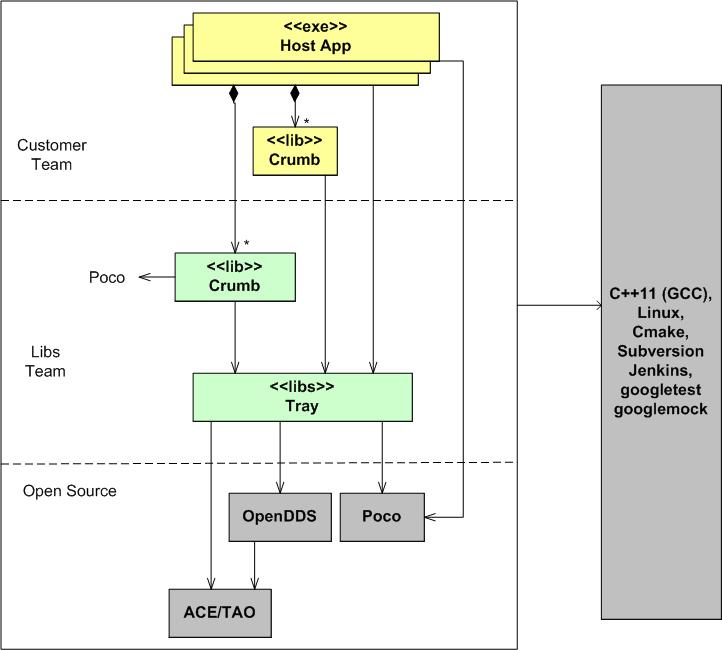
The figure below shows a layered view of the latest distributed system product that I’m working on. Customer teams compose their applications by writing their own system-specific Crumbs and linking them with our pre-written, pre-tested Crumbs. In the ideal case, customers don’t have to write a single line of Crumb code. They simply compose, compile, link, configure, and deploy an amalgamation of our off-the-shelf Crumbs as a set of application components that meets their needs.
Note that we are using C++11 to build the system. Also note the third party, open source libraries that we are building upon. Except for Poco, Crumb developers don’t directly use the OpenDDS or ACE/TAO APIs. Our Crumb “Tray” serves as a wrapper/facade that hides the complexity those inter-process communication facilities.
My role on the development team is as a Libs team “Crumb” designer/writer. If I gave you anymore product views or disclosed anything more concrete, then I’d either get fired or I’d have to kill you, or both.
What are you currently working on?
Working Code Over Comprehensive Documentation
Comprehensiveness is the enemy of comprehensibility – Martin Fowler
Martin’s quote may be the main reason why this preference was written into the Agile Manifesto…
Working software over comprehensive documentation
Obviously, it doesn’t say “Working software and no documentation“. I’d bet my house that Martin and his fellow colleagues who conjured up the manifesto intentionally stuck the word “comprehensive” in there for a reason. And the reason is that “good” documentation reduces costs in both the short and long runs. In addition, check out what the Grade-ster has to say:
The code tells the story, but not the whole story – Grady Booch
Now that the context for this post has been set, I’d like to put in a plug for Simon Brown’s terrific work on the subject of lightweight software architecture documentation. In tribute to Simon, I decided to hoist a few of his slides that resonate with me.



Note that the last graphic is my (and perhaps Simon’s?) way of promoting standardized UML-sketching for recording and communicating software architectures. Of course, if you don’t record and communicate your software architectures, then reading this post was a waste of your time; and I’m sorry for that.

The Gall Of That Man!
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system. – John Gall (1975, p.71)
This law is essentially an argument in favour of underspecification: it can be used to explain the success of systems like the World Wide Web and Blogosphere, which grew from simple to complex systems incrementally, and the failure of systems like CORBA, which began with complex specifications. – Wikipedia
We can add the Strategic Defense Initiative (Star Wars), the FBI’s Virtual Case File System (VCS), JTRS, FCS, and prolly a boatload of other high falutin’ defense projects to the list of wreckage triggered by violations of Gall’s law. Do you have any other majestic violations you’d like to share? Can you cite any counter-examples that attempt to refute the law….
One of the great tragedies of life is the murder of a beautiful theory by a gang of brutal facts – Benjamin Franklin
C++, which started out simply as “C With Classes“, is a successful complex “system“. Java, which started out as a simple and pure object-oriented system, has evolved into a successful complex system that now includes a mix of functional and generic programming features. Linux, which started out as a simple college operating system project, has evolved into a monstrously successful complex system. DDS, which started out as a convergence of two similar, field-tested, pub-sub messaging implementations from Thales Inc. and RTI Inc., has evolved into a successful complex system (in spite of being backed by the OMG). Do you have any other law abiding citizens you’d like to share?
Gall’s law sounds like a, or thee, platform for Fred Brooks‘ “plan to throw one away” admonition and Grady Booch‘s “evolution through a series of stable intermediate forms” advice.
Here are two questions to ponder: Is your org in the process of trying to define/develop a grand system design from scratch? Scanning your project portfolio, can you definitively know if you’re about to, or currently are, attempting a frontal assault on Gall’s galling law – and would it matter if you did know?

Asynchronous Flows And Synchronous Transactions
The figure below shows a pair of BD00 concocted models for two classes of systems; peer-to-peer and client-server:

The primary mission of an AFCS is to progressively transform a high rate stream of incoming raw samples into a higher level, abstract representation of some phenomena that’s important to its users. In an STCS, the system’s primary mission is to transform low rate user requests into information that’s important to its users.
In business support applications, STC systems dominate the scene. In aerospace and defense applications, AFC systems are king. Of course, the situation is never as simplistic as BD00 sez. Hybrid systems like the sensor-based command and control model below can be found everywhere.

For some reason (maybe market size and/or community culture and/or media exposure?), most software technology advancements (languages, patterns, methodologies, frameworks, etc) seem to emerge out of the STCS space. Those innovations that are “applicable” get adopted in the AFCS space. Hell, even those that are inapplicable (because they weren’t designed with performance as the top priority) get adopted.
Boulders And Pebbles
When embarking on a Software Product Line (SPL) development, one of the first, far-reaching cost decisions to be tackled is the level of “granularity” of the component set. Obviously, you don’t want to develop one big, fat-ass, 5 million line monstrosity that has to have 1000s of lines changed/added/hacked for each customer “instantiation“. Gee, that’s probably how you operate now and why you’re tinkering with the idea of an SPL approach for the future.
On the other hand, you don’t want to build 1000s of 10K-line pieces that are a nightmare for composition, configuration, versioning and integration. For a given domain, there’s a “subjective” sweet spot somewhere between a behemoth 5M-line boulder and a basket of 10K-line pebbles. However, if you’re gonna err on one side or the other, err on the side of “bigger“:
…beware of overly fine-grained components, because too many components are hard to manage, especially when versioning rears its ugly head, hence “DLL hell.” – Martin Fowler (UML Distilled)
The primacy of system functions and system function groups allows a new member of the product line to be treated as the composition of a few dozen high-quality, high-confidence components that interact with each other in controlled, predictable ways as opposed to thousands of small units that must be regression tested with each new change. Assembly of large components without the need to retest at the lowest level of granularity for each new system is a critical key to making reuse work. – Brownsword/Clements (A Case Study In Successful Product Line Development)

Time For A Toga Party!

Three Degrees Of Distribution
Behold the un-credentialed and un-esteemed BD00’s taxonomy of software-intensive system complexity:
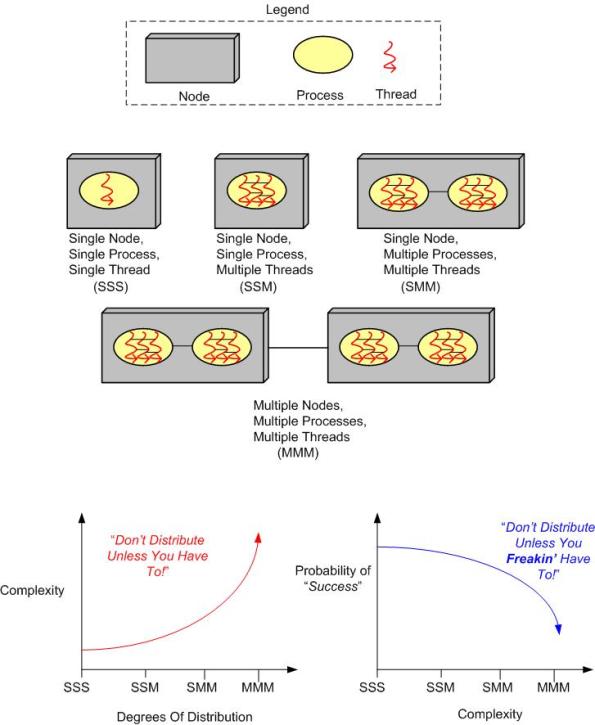
How many “M”s does the system you’re working on have? If the answer is three, should it really be two? If the answer is two, should it really be one? How do you know what number of “M”s your system design should have? When tacking on another “M” to your system design because you “have to“, what newly emergent property is the largest complexity magnifier?
Now, replace the inorganic legend at the top of the page with the following organic one and contemplate how the complexity and “success” curves are affected:
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

