Archive
The Hodgepodge Myth
There are two kinds of languages. Those that everyone complains about and those that nobody uses. – Bjarne Stroustrup
I’ve seen C++ described as a thoughtless hodgepodge of features and approaches that were carelessly slapped together and foist upon the programming community. However, if any of those detractors read “The Design And Evolution Of C++” and dive deeply into the language’s technical details, they might change their minds and marvel at the essential complexity baked into C++.
As a systems programming language whose target niche is infrastructure and constrained-resource (CPU speed and memory) applications, C++ is all about achieving efficient abstraction (as opposed to increasing programmer productivity). For efficiency, its constructs must not move too far away from how computing hardware actually stores and manipulates data (linear arrays, pointers, stack-based variables). Otherwise, a “hidden” layer of translational code must be inserted between what the programmer actually writes and the code that actually runs on the hardware. To write large, domain-specific programs, C++ must also provide abstraction facilities for implementing domain concepts and inter-concept relationships directly in code (classes, inheritance, friendship, templates, namespaces, exceptions, meta-programming).
Comparatively speaking, no other high level language comes close to achieving the blend of abstraction and efficiency that C++ attains. Sure, there are many newer languages that increase programmer productivity by decreasing verbosity, increasing levels of abstraction, and insulating the programmer from details, but the price paid for this productivity gain is a loss in runtime performance, a shallow understanding of what goes on underneath the covers, and long stretches of optimization/tuning efforts to meet performance requirements.
Once an engineer forms a string opinion on a technical tool or methodology, she is unlikely to change it – no matter what evidence is placed in front of her. As regular readers of this ball-busting blog know, BD00 chronically suffers from this “fan boy” malady all too well. And this post is a prime example of that behavioral trait.

Don’t Panic!
The fourth edition of “The C++ Programming Language” weighs in at 1346 pages and 44 chapters allocated over four partitions. The end of each chapter provides a list of advisory items – yielding a grand total of 699 nuggets of general programming and C++ specific wisdom for the reader to ponder.

The figure below shows a breakdown of the behemoth book’s table of contents. The number of advisories provided in each chapter and each partition are shown on the right side.

As a temporary excursion from reading and studying and writing exploratory snippets of C++11 code, I went through all 699 items and plucked out a subset of the tidbits I found most useful. Of course, your personal list would no doubt turn out differently.

Even though it’s not on my list, my absolute favorite item of advice is the first one presented at the end of chapter 2:

D’oh! Wanna guess at how much time is needed for all to become clear? Maybe Malcolm Gladwell‘s famous “10,000 hours” isn’t enough? But that’s why I love C++. It provides an endlessly rich and deep opportunity for learning.
Two Peas In A Pod
It’s funny how I never know which, if any, of my bogus posts will have the potential to generate an above average number of hits on this blog. The posts that I thought may have triggered a rise above the average daily hit count (approximately 50) never have. The posts that have indeed appreciably crossed the threshold, I never thought would. In four years of blogging, not a single one of my a-priori guesses has come true.
When I stitched together “The Point Of No Return” post, I thought “meh“; it’s just another average, unenlightening BD00 post. However, somehow, somewhere, some kind soul on the blog staff at the official ISO C++ org web site decided otherwise. He/she thought it useful enough to post a link to it right smack on the site’s home page:
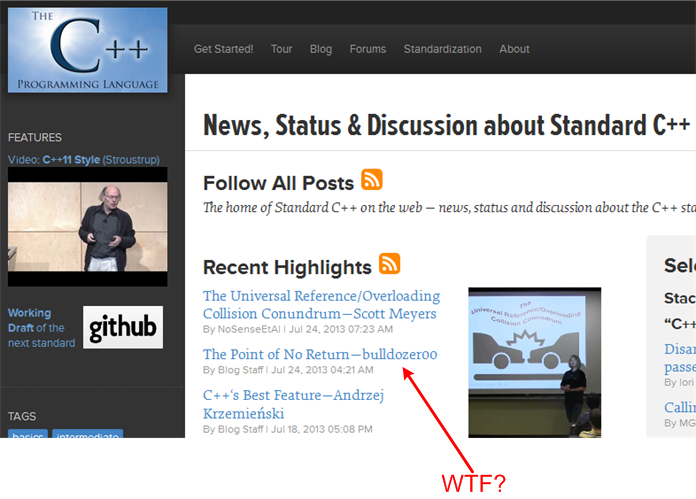
W00T! Me and my man Bjarne Stroustrup on the same page – like two peas in a pod. Do ya think Bjarne would appreciate the BD00 connection?

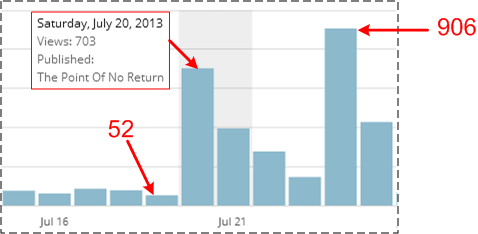
The dashboard below shows the spike in traffic experienced by BD00’s blog as a result of the generous plug from the blog staff at isocpp.org. I surely hope that the wordpress.com server farm didn’t crash from the sudden surge in traffic!
Freakin’ Oops!
With great power there must also come… great responsibility – Stan Lee
C++, being as sprawling and powerful and flexible as it is, rightly gets dinged for its propensity to bite you in the ass (if you don’t fully understand a language feature you’re trying to use). Thus, many C++ programming book authors point out common “gotchas” while teaching the language to their readers.
The graphic below depicts some “watchout!” snippets from four different, popular C++ programming books. As you might surmise from the picture, my favorite word in a C++ programming book is (freakin’) “Oops!”.

make_unique
On my current project, we’re joyfully using C++11 to write our computationally-dense target processing software. We’ve found that std::shared_ptr and std::unique_ptr are extremely useful classes for avoiding dreaded memory leaks. However, I find it mildly irritating that there is no std::make_unique to complement std::make_shared. It’s great that std::make_unique will be included in the C++14 standard, but whenever we use a std::unique_ptr we gotta include a fugly “new” in our C++11 code until then:
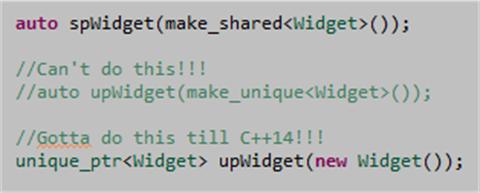
But wait! I stumbled across this helpful Herb Sutter slide:

A variadic function template that uses perfect forwarding. It’s outta my league, but….. Whoo Hoo! I’m gonna add this sucker to our platform library and start using it ASAP.
Rule-Based Safety
In this interesting 2006 slide deck, “C++ in safety-critical applications: the JSF++ coding standard“, Bjarne Stroustrup and Kevin Carroll provide the rationale for selecting C++ as the programming language for the JSF (Joint Strike Fighter) jet project:
First, on the language selection:
- “Did not want to translate OO design into language that does not support OO capabilities“.
- “Prospective engineers expressed very little interest in Ada. Ada tool chains were in decline.“
- “C++ satisfied language selection criteria as well as staffing concerns.“
They also articulated the design philosophy behind the set of rules as:
- “Provide “safer” alternatives to known “unsafe” facilities.”
- “Craft rule-set to specifically address undefined behavior.”
- “Ban features with behaviors that are not 100% predictable (from a performance perspective).”
Note that because of the last bullet, post-initialization dynamic memory allocation (using new/delete) and exception handling (using throw/try/catch) were verboten.
Interestingly, Bjarne and Kevin also flipped the coin and exposed the weaknesses of language subsetting:

What they didn’t discuss in the slide deck was whether the strengths of imposing a large coding standard on a development team outweigh the nasty weaknesses above. I suspect it was because the decision to impose a coding standard was already a done deal.

Much as we don’t want to admit it, it all comes down to economics. How much is the lowering of the risk of loss of life worth? No rule set can ever guarantee 100% safety. Like trying to move from 8 nines of availability to 9 nines, the financial and schedule costs in trying to achieve a Utopian “certainty” of safety start exploding exponentially. To add insult to injury, there is always tremendous business pressure to deliver ASAP and, thus, unconsciously cut corners like jettisoning corner-case system-level testing and fixing hundreds of “annoying” rules violations.
Does anyone have any data on whether imposing a strict coding standard actually increases the safety of a system? Better yet, is there any data that indicates imposing a standard actually decreases the safety of a system? I doubt that either of these questions can be answered with any unbiased data. We’ll just continue on auto-believing that the answer to the first question is yes because it’s supposed to be self-evident.
The Renaissance That Wasn’t
In the thoughtful and well-written article, “The Rise and Fall of Languages in 2012”, Andrew Binstock rightly noted that the C++ renaissance predicted by C++ ISO committee chairman Herb Sutter did not materialize last year. Even though C++ butters my bread and I’m a huge Sutter fan, I have to agree with Mr. Binstock’s assessment:
In fact, I can find no evidence that C++ is breaking into new niches at a pace that will affect the language’s overall numbers. For that to happen, it would need to emerge as a primary language in one of today’s busiest sectors: mobile, or the cloud, or big data. Time will tell, but I feel comfortable projecting that C++ will continue to grow in its traditional niches and will advance at the same rate as those niches grow.
Nevertheless, if you buy into Herb’s prognostication that power consumption and computing efficiency (performance per watt) will overtake programmer productivity as the largest business cost drag in the future, then the C++ renaissance may still be forthcoming. Getting 2X the battery life out of a mobile gadget or a .5X reduction in the cost to run a data center may be the economic ticket that triggers a deeper C++ penetration into what Andrew says are today’s busiest sectors: mobile, the cloud, and big data. However, if the C++ renaissance does occur, it won’t take hold overnight, let alone over the one year that has passed since the C++11 standard was hatched.
It’s tough to make predictions, especially about the future – Yogi Berra

Cpp Initialization Styles
For most cases, the “assignment” and “function” styles of initializing objects in C++ are the same. However, as the example below shows, in some edge cases, the function style of initialization can be more efficient. Nevertheless, for all practical purposes they are essentially the same since the compiler may optimize away the actual assignment step in the 2 step “assignment” style.
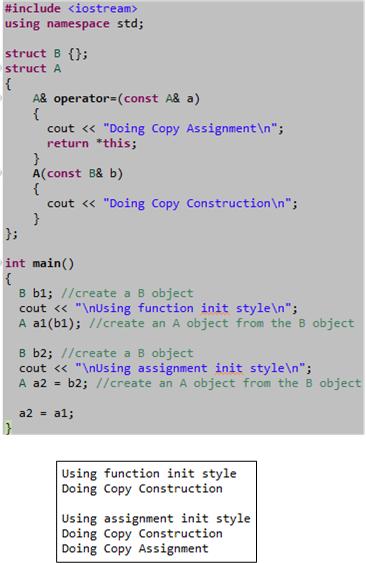
The motivation for this post came from a somewhat lengthy debate with a fellow member of the “C++ Developers Group” on LinkedIn.com. I knew that a subtle difference between the two initialization styles existed, but I couldn’t remember where I read about it. However, after I wrote this post, I browsed through my C++ references again and I found the source. The difference is explained in a much more intelligible and elegant way in “Efficient C++ Performance Programming Techniques“. Specifically, the discussion and example code in Chapter 5, “Temporaries – Object Definition“, does the trick.
Update 12/3/12
As my colleague friend pointed out, the above post is outright wrong with respect to the possibility of the assignment operator being used during initialization. Assignment is only used to copy values from one existing object into another existing object – not when an object is being created. That’s what constructors do. The “Doing Copy Assignment” text in the above code only prints to the console because of the last a2 = a1 statement in main(), which I put there to stop the g++ compiler from complaining about an unused variable. D’oh!
The example in the “Efficient” book that triggered our discussion is provided here:

The authors go on to state:
Only the first form of initialization is guaranteed, across compiler implementations, not to generate a temporary object. If you use forms 2 or 3, you may end up with a temporary, depending on the compiler implementation. In practice, however, most compilers should optimize the temporary away, and the three initialization forms presented here would be equivalent in their efficiency.
Ever since I read that book many years ago, I’ve always preferred to use the “function” style initialization over the “assignment” style. But it’s just a personal preference.
A Real Renaissance
For quite some time now, I’ve been hearing that C++ has been undergoing a resurgence of interest; a renaissance. However, until recently, I couldn’t tell if the claim was real, or just some hype coming out of the C++ community to fruitlessly combat the rise of a plethora of new languages.
Well, I’m convinced that the renaissance is legit. The slides below, pilfered from Herb Sutter‘s “The Future Of C++” talk at Microsoft Build 2012, introduced the formation of a new C++ trade group, the “Standard C++ Foundation“.

Note that there are some big guns with deep pockets backing the foundation along with a cadre of brilliant and dedicated directors at the helm.
It’s a good time to be a C++ programmer, so join the renaissance and start learning the new features and libraries offered up in C++11. Of course, if your technical management is not forward looking and it’s tight with training dollars, you’ll have to do it on your own time, covertly, behind the scenes. But it will not only be fun, it will enhance your marketability.
The C++ Product Roadmap
Fresh from the ISO C++ chairman himself, Herb Sutter, I present you with the C++ product roadmap:

If all goes according to plan, a minor release of the ISO standard will be hatched in 2014. By minor, Herb means that it will be mostly bug fixes to C++11, plus a filesystem library based on Boost.org‘s brilliant work. The networking library, which is big and being developed by a large group of smart people, will be hatched incrementally in a series of Technical Specifications (TS).
The main point that Herb stressed when he hoisted the slide was that “the past is not a good predictor of the future“. If all goes according to plan, the time between major releases of the standard will have been cut from 13 years to 6.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

