Archive
Morrie Three
Check out these shots of my best buddy Morrie….

Proximity In Space And Time
When a failure occurs in a complex, networked, socio-technical system, the probability is high that the root cause is located far away from the failure detection point in time, space, or both. The progression in time goes something like this:
fault ———–> error———-> error—————–>error——>failure discovered!
An unanticipated fault begets an error, which begets another error(s), which begets another error(s), etc, until the failure is manifest via loss of life or money somewhere and sometime downstream in the system. In the case of a software system, the time from fault to catastrophic failure may take milliseconds, but the distance between fault and failure can be in the 100s of thousands of lines of source code sprinkled across multiple machines and networks.

Let’s face it. Envisioning, designing, coding, and testing for end-to-end “system level” error conditions in software systems is unglamorous and tedious (unless you’re using Erlang – which is thoughtfully designed to lessen the pain). It’s usually one of the first things to get jettisoned when the pressure is ratcheted up to meet some arbitrary schedule premised on a baseless, one-time, estimate elicited under duress when the project was kicked-off. Bummer.
Immediate Past Head

I’ve stumbled upon some really whacky titles (especially on linkedin.com), but this one takes the BD00 prize in titular creativity…. so far:

So, when does “immediate” expire and the title get dropped? Or will it slowly fade away via a series of lesser titles: “recent past head“, “distant past head“, “historic past head“?
What’s the strangest title you’ve come across?
Heaven And Hell
This is one of those picture-only posts where BD00 invites you to fill in the words of the missing story…


Cpp Initialization Styles
For most cases, the “assignment” and “function” styles of initializing objects in C++ are the same. However, as the example below shows, in some edge cases, the function style of initialization can be more efficient. Nevertheless, for all practical purposes they are essentially the same since the compiler may optimize away the actual assignment step in the 2 step “assignment” style.
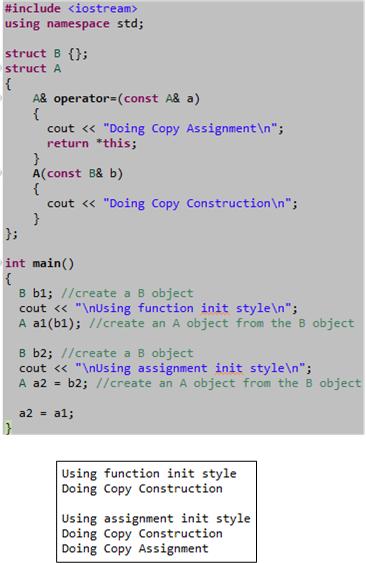
The motivation for this post came from a somewhat lengthy debate with a fellow member of the “C++ Developers Group” on LinkedIn.com. I knew that a subtle difference between the two initialization styles existed, but I couldn’t remember where I read about it. However, after I wrote this post, I browsed through my C++ references again and I found the source. The difference is explained in a much more intelligible and elegant way in “Efficient C++ Performance Programming Techniques“. Specifically, the discussion and example code in Chapter 5, “Temporaries – Object Definition“, does the trick.
Update 12/3/12
As my colleague friend pointed out, the above post is outright wrong with respect to the possibility of the assignment operator being used during initialization. Assignment is only used to copy values from one existing object into another existing object – not when an object is being created. That’s what constructors do. The “Doing Copy Assignment” text in the above code only prints to the console because of the last a2 = a1 statement in main(), which I put there to stop the g++ compiler from complaining about an unused variable. D’oh!
The example in the “Efficient” book that triggered our discussion is provided here:

The authors go on to state:
Only the first form of initialization is guaranteed, across compiler implementations, not to generate a temporary object. If you use forms 2 or 3, you may end up with a temporary, depending on the compiler implementation. In practice, however, most compilers should optimize the temporary away, and the three initialization forms presented here would be equivalent in their efficiency.
Ever since I read that book many years ago, I’ve always preferred to use the “function” style initialization over the “assignment” style. But it’s just a personal preference.
Uniform Initialization Failure?
On our latest distributed system project, we’ve decided to use some of the C++11 features provided by GCC 4.7. Right off the bat, I happily started using the “uniform initialization” feature, the auto keyword, range-for loops, and in-class member initializers.
While incorporating uniform initialization all over my crappy code, I either stumbled into a compiler bug or a flaw in my understanding of the feature. I don’t know which is the case, and that’s why I’m gonna ask for your help figuring it out in this “normal” blog post.
Behold the code that the compiler explodes on:

But Mr. Compiler, I’m trying to initialize a non-const reference (std::mutex& mtx_) lvalue with an rvalue of the exact same same type, another non-const reference (std::mutex& m). WTF?
Next, observe the change I had to make to satisfy the almighty compiler:

I’m bummed that I had to destroy the “elegance” (LOL!) of the product code by replacing the C++11 brace pair with the old style parenthesis pair of C++03.
Since little things like this tend to consume me, I explored the annoyance further by writing some little side test programs. I found that the compiler seems to barf every time I try to initialize any reference type via a brace pair – so the problem is not std::mutex specific.

So, I’m asking for your help. Is it a compiler bug, or a misunderstanding on my part?
Update A (12/1/12)
I’ve come to the conclusion that the issue is indeed a compiler bug. While searching for the cause, I found the following paper and set of initializer list examples on Bjarne Stroustrup‘s web site:

According to the man himself, my exploding code should compile cleanly, no?
Update B (12/1/12)
After further research, I’ve flip-flopped. Now I don’t think it’s a problem with the compiler. It’s simply that the std::mutex class is not designed to support an initializer list (of one)? In order to support uniform initialization, I think a class must be explicitly designed to provide it via some sort of constructor syntax that I haven’t learned yet. Thus, unless all the classes used in a program explicitly provide initializer list support, the program must use “mixed initialization” in order to compile. If this is true, then bummer. Uniform initialization doesn’t come “for free” with C++11 – which is what I erroneously thought.
Update C 12/5/12
After yet more research and coding on this annoying issue, I discovered that whether or not brace style initialization works for references is indeed type specific. As the example below shows, brace style initialization compiles fine for a reference to a plain old int.

In the process of experimenting, I also discovered what I think is a g++ 4.7.2 compiler bug:

Note that in this case, I’m trying to brace-init a member of type Base, not a reference to Base. There’s something screwy going on with brace initialization that I don’t understand. Got any advice/insight to share?
I-Speak
I don’t know where I read it, but I remember someone giving great advice about using “I-Speak” to present your case on a sensitive issue. Don’t go blasting away and saying stuff like “everyone thinks the system is a freakin’ disaster“. Instead, say “I have a hard time using the system as it’s designed“.
In really uptight and unresponsive groups, preface your concern with “I can only speak for myself, but…“. But don’t forget, in zero tolerance bureaucracies, keep your “I” trap totally shut tight and keep toiling along in quiet desperation.

Code First And Discover Later
In my travels through the whacky world of software development, I’ve found that bottom up design (a.k.a code first and “discover” the real design later) can lead to lots of unessential complexity getting baked into the code. Once this unessential complexity, in the form of extraneous classes and a rats nest of unneeded dependencies, gets baked into the system and the contraption “appears to work” in a narrow range of scenarios, the baker(s) will tend to irrationally defend the “emergent” design to the death. After all, the alternative would be to suffer humility and perform lots of risky, embarrassing, and ego-busting disentanglement rework. Of course, all of these behaviors and processes are socially unacceptable inside of orgs with macho cultures; where publicly admitting you’re wrong is a career-ending move. And that, my dear, is how we have created all those lovable, “legacy” systems that run the world today.
Don’t get BD00 wrong here. The esteemed one thinks that bottom up design and coding is fine for small scoped systems with around 7 +/- 2 classes (Miller’s number), but this “easy and fun and fast” approach sure doesn’t scale well. Even more ominously, the bottom up coding and emergent design strategy is unacceptable for long-lived, safety-critical systems that will be scrutinized “later on” by external technical inspectors.

Underlying Assumptions

The underlying assumptions harbored by executive decision-makers drive an org’s processes/policies. And those processes/policies influence an org’s social and financial performance. As a rule, assumptions based on Theory X thinking lead to mediocre performance and those based on Theory Y lead to stellar performance. Most org processes/policies (e.g. the annual “objective” performance appraisal ritual) are Theory X based constrictions cloaked in Theory Y rhetoric – regardless of what is espoused.

Faking Rationality
I recently dug up and re-read the classic Parnas/Clement 1986 paper: “A Rational Design Process: How And Why To Fake It“. Despite the tendency of people to want to desperately believe the process of design is “rational“, it never is. The authors know there is no such thing as a sequential, rational design process where:
- There’s always a good reason behind each successive design decision.
- Each step taken can be shown to be the best way to get to a well defined goal.
The culprit that will always doom a rational design process is “learning“:
Many of the details only become known to us as we progress in the implementation (of a design). Some of the things that we learn invalidate our design and we must backtrack (multiple times during the process). The resulting design may be one that would not result from a rational design process. – Parnas/Clements
Since “learning“, in the form of going backwards to repair discovered mistakes, is a punishable offense in social command & control hierarchies where everyone is expected to know everything and constantly march forward, the best strategy is to cover up mistakes and fake a rational design process when the time comes to formally present a “finished” design to other stakeholders.
Even though it’s unobtainable, for some strange reason, Spock-like rationality is revered by most orgs. Thus, everyone in org-land plays the “fake-it” game, whether they know it or not. To expect the world to run on rationality is irrational.
Executives preach “evidence-based decision-making“, but in reality they practice “decision-based evidence-making“.

Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

