Archive
We Must!
I don’t have a source link for this brilliant graphic, but I just HAD to re-hoist it on here.

A Showstopper And A Nuisance
I recently spent 3.5 days hunting down and squashing a “showstopper” bug that ended up being a side effect of an earlier fix that I had made to eradicate a long-standing “nuisance” bug.
SIDEBAR: The nuisance bug occurred only during system shutdown. The system would crash on exit, but no data was lost or corrupted. It was long thought to be an “out of sequence” object destruction problem, but because hundreds of lines of nested destructor code are called during shutdown in multiple threads of execution and the customer never formally reported the bug (because the system is very rarely shutdown), it’s annihilation was put on the shelf – until I “fixed” it.
When I was initially told about the showstopper, I was confounded because the bug seemed to be located somewhere in the code of a simple feature that I had thought I tested pretty thoroughly. And yet, there it was, plainly obvious and easily reproducible – a crash that happens during runtime whenever a specific sequence of operator actions are performed. WTF?
With the system model below embedded in my genius mind, I thought the bug HAD to be located somewhere in the massive, preexisting, 150K line legacy code base. After all, the number of code lines I added to the beast in order to implement the feature was so small and unassuming that the odds favored my hypothesis.

Even though my hypothesis was that the new code I added had uncovered and triggered some other dormant bug deep in the bowels of the software, I first inspected the measly few lines I recently added to the code base. Of course, the inspection yielded no “aha, there it is” moment. Bummer.
Next, I fired up the debugger, sprinkled a bunch of breakpoints throughout the code, and stepped through my brilliant and elegantly simple code. I found that when the control of execution descended into the netherworld below my impeccable work, the bug came out of hiding – crash! However, since a bunch of event driven callbacks were triggered each time the execution of control left my code, I couldn’t trace the execution path so easily.
Exasperated that the debugger didn’t tell me exactly where and what the freakin’ bug was, I started reading and reverse engineering (via targeted UML class and sequence diagram sketches) segments of the legacy code. Since it was my first focused foray down into the dungeon, it was a slow going, but beneficial, learning experience.
Finally, after a couple of days of inspection, reverse engineering, and a bazillion debugger runs, I stumbled upon a note written by yours truly in one of the infrastructure callback functions:
“The line of code below was commented out because it triggers a crash on shutdown“.
Bingo, a light went off! Quickly, I uncommented out the line of code and reran the program. Yepp, the bug was gone! As I initially thought, the critter did turn out to be living within the infrastructure, but I had unwittingly put it there a while ago in order to kill the long-standing “nuisance” shutdown bug. Ain’t life grand?
Of course, the tradeoff for re-enabling the line of code that killed the nasty bug is that the nuisance bug is alive and well again. And no, unless I’m directly ordered to, I ain’t gonna go uh huntin’ fer it aginn. No good deed goes unpunished.

Defect Density
ln “Software’s Hidden Clockwork: A General Theory of Software Defects“, Les Hatton presents these two interesting charts:


The thing I find hard to believe is that Les has concluded that there is no obvious significant relationship between defect density and the choice of programming language. But notice that he doesn’t seem to have any data points on his first chart for the relatively newer, less “tricky“, and easier-to-program languages like Java, C#, Ruby, Python, et al.
So, do you think Les might have jumped the gun here by prematurely asserting the virtual independence of defect density on programming language?
Proximity In Space And Time
When a failure occurs in a complex, networked, socio-technical system, the probability is high that the root cause is located far away from the failure detection point in time, space, or both. The progression in time goes something like this:
fault ———–> error———-> error—————–>error——>failure discovered!
An unanticipated fault begets an error, which begets another error(s), which begets another error(s), etc, until the failure is manifest via loss of life or money somewhere and sometime downstream in the system. In the case of a software system, the time from fault to catastrophic failure may take milliseconds, but the distance between fault and failure can be in the 100s of thousands of lines of source code sprinkled across multiple machines and networks.

Let’s face it. Envisioning, designing, coding, and testing for end-to-end “system level” error conditions in software systems is unglamorous and tedious (unless you’re using Erlang – which is thoughtfully designed to lessen the pain). It’s usually one of the first things to get jettisoned when the pressure is ratcheted up to meet some arbitrary schedule premised on a baseless, one-time, estimate elicited under duress when the project was kicked-off. Bummer.
Heaven And Hell
This is one of those picture-only posts where BD00 invites you to fill in the words of the missing story…


Cpp Initialization Styles
For most cases, the “assignment” and “function” styles of initializing objects in C++ are the same. However, as the example below shows, in some edge cases, the function style of initialization can be more efficient. Nevertheless, for all practical purposes they are essentially the same since the compiler may optimize away the actual assignment step in the 2 step “assignment” style.
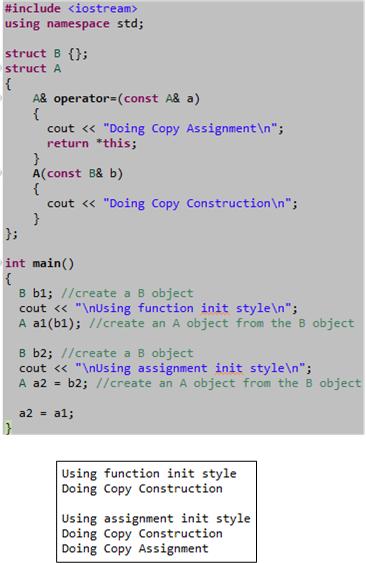
The motivation for this post came from a somewhat lengthy debate with a fellow member of the “C++ Developers Group” on LinkedIn.com. I knew that a subtle difference between the two initialization styles existed, but I couldn’t remember where I read about it. However, after I wrote this post, I browsed through my C++ references again and I found the source. The difference is explained in a much more intelligible and elegant way in “Efficient C++ Performance Programming Techniques“. Specifically, the discussion and example code in Chapter 5, “Temporaries – Object Definition“, does the trick.
Update 12/3/12
As my colleague friend pointed out, the above post is outright wrong with respect to the possibility of the assignment operator being used during initialization. Assignment is only used to copy values from one existing object into another existing object – not when an object is being created. That’s what constructors do. The “Doing Copy Assignment” text in the above code only prints to the console because of the last a2 = a1 statement in main(), which I put there to stop the g++ compiler from complaining about an unused variable. D’oh!
The example in the “Efficient” book that triggered our discussion is provided here:

The authors go on to state:
Only the first form of initialization is guaranteed, across compiler implementations, not to generate a temporary object. If you use forms 2 or 3, you may end up with a temporary, depending on the compiler implementation. In practice, however, most compilers should optimize the temporary away, and the three initialization forms presented here would be equivalent in their efficiency.
Ever since I read that book many years ago, I’ve always preferred to use the “function” style initialization over the “assignment” style. But it’s just a personal preference.
Code First And Discover Later
In my travels through the whacky world of software development, I’ve found that bottom up design (a.k.a code first and “discover” the real design later) can lead to lots of unessential complexity getting baked into the code. Once this unessential complexity, in the form of extraneous classes and a rats nest of unneeded dependencies, gets baked into the system and the contraption “appears to work” in a narrow range of scenarios, the baker(s) will tend to irrationally defend the “emergent” design to the death. After all, the alternative would be to suffer humility and perform lots of risky, embarrassing, and ego-busting disentanglement rework. Of course, all of these behaviors and processes are socially unacceptable inside of orgs with macho cultures; where publicly admitting you’re wrong is a career-ending move. And that, my dear, is how we have created all those lovable, “legacy” systems that run the world today.
Don’t get BD00 wrong here. The esteemed one thinks that bottom up design and coding is fine for small scoped systems with around 7 +/- 2 classes (Miller’s number), but this “easy and fun and fast” approach sure doesn’t scale well. Even more ominously, the bottom up coding and emergent design strategy is unacceptable for long-lived, safety-critical systems that will be scrutinized “later on” by external technical inspectors.

A Glimpse Into C++11PL4
At Microsoft’s Build 2012 conference, ISO C++ chairman Herb Sutter introduced the new isocpp.org web site. On the site, you can download a draft version of Chapter 2 from Bjarne Stroustrup‘s upcoming “The C++ Programming Language, 4th Edition“. As I read the chapter and took “the tour“, I noted the new C++11 features that Bjarne used in his graceful narrative. Here they are:
auto, intializer lists, range-for loops, constexpr, enum class, nullptr, static_assert.
Since I’m a big Stroustrup and C++ fan, I just wanted to pass along this tidbit of info to the C++ programmers that happen to stumble upon this blog.

A Real Renaissance
For quite some time now, I’ve been hearing that C++ has been undergoing a resurgence of interest; a renaissance. However, until recently, I couldn’t tell if the claim was real, or just some hype coming out of the C++ community to fruitlessly combat the rise of a plethora of new languages.
Well, I’m convinced that the renaissance is legit. The slides below, pilfered from Herb Sutter‘s “The Future Of C++” talk at Microsoft Build 2012, introduced the formation of a new C++ trade group, the “Standard C++ Foundation“.

Note that there are some big guns with deep pockets backing the foundation along with a cadre of brilliant and dedicated directors at the helm.
It’s a good time to be a C++ programmer, so join the renaissance and start learning the new features and libraries offered up in C++11. Of course, if your technical management is not forward looking and it’s tight with training dollars, you’ll have to do it on your own time, covertly, behind the scenes. But it will not only be fun, it will enhance your marketability.
The C++ Product Roadmap
Fresh from the ISO C++ chairman himself, Herb Sutter, I present you with the C++ product roadmap:

If all goes according to plan, a minor release of the ISO standard will be hatched in 2014. By minor, Herb means that it will be mostly bug fixes to C++11, plus a filesystem library based on Boost.org‘s brilliant work. The networking library, which is big and being developed by a large group of smart people, will be hatched incrementally in a series of Technical Specifications (TS).
The main point that Herb stressed when he hoisted the slide was that “the past is not a good predictor of the future“. If all goes according to plan, the time between major releases of the standard will have been cut from 13 years to 6.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

