Zero Out Of Ten
In a recent talk at Cambridge University, Bjarne Stroustrup presented this slide to his audience:

Although lots of hard work has been performed by some very smart people over the years in developing these features, Mr. Stroustrup (sadly) went on to say that none of them will be present in the formal C++17 specification. The last sentence on the slide succinctly summarizes why.
M Of N Fault Detection
Let’s say that, for safety reasons, you need to monitor the voltage (or some other dynamically changing physical attribute) of a safety-critical piece of equipment and either shut it down automatically and/or notify someone in the event of a “fault“.
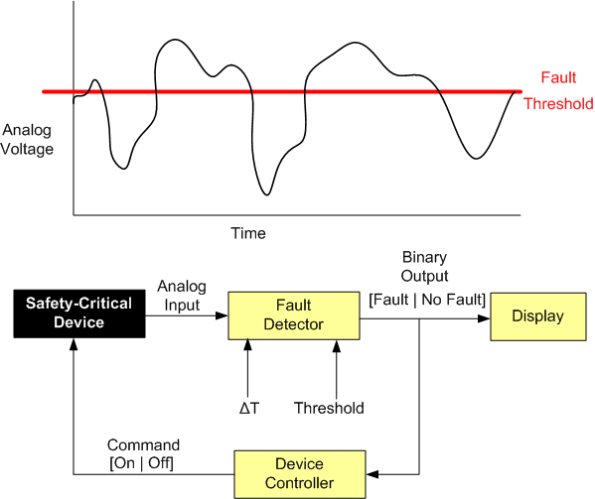
The figure below drills into the next level of detail of the Fault Detector. First, the analog input signal is digitized every ΔT seconds and then the samples are processed by an “M of N Detector”.
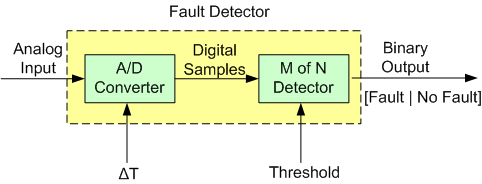
The logic implemented in the Detector is as follows:

Instead of “crying wolf” and declaring a fault each time the threshold is crossed (M == N == 1), the detector, by providing the user with the ability to choose the values of M and N, provides the capability to smooth out spurious threshold crossings.
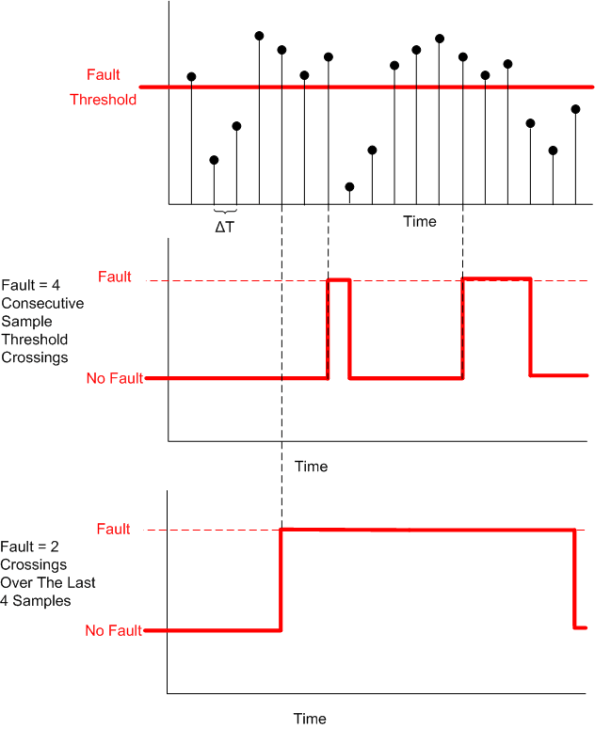
The next figure shows an example input sequence and the detector output for two configurations: (M == N == 4) and (M == 2, N == 4).
Finally, here’s a c++ implementation of an M of N Detector:
#ifndef MOFNDETECTOR_H_
#define MOFNDETECTOR_H_
#include <cstdint>
#include <deque>
class MofNDetector {
public:
MofNDetector(double threshold, int32_t M, int32_t N) :
_threshold(threshold), _M(M), _N(N) {
reset();
}
bool detectFault(double sample) {
if (sample > _threshold)
++_numCrossings;
//Add our newest sample to the history
if(sample > _threshold)
_lastNSamples.push_back(true);
else
_lastNSamples.push_back(false);
//Do we have enough history yet?
if(static_cast<int32_t>(_lastNSamples.size()) < _N) {
return false;
}
bool retVal{};
if(_numCrossings >= _M)
retVal = true;
//Get rid of the oldest sample
//to make room for the next one
if(_lastNSamples.front() == true)
--_numCrossings;
_lastNSamples.pop_front();
return retVal;
}
void reset() {
_lastNSamples.clear();
_numCrossings =0;
}
private:
int32_t _numCrossings;
double _threshold;
int32_t _M;
int32_t _N;
std::deque<bool> _lastNSamples{};
};
#endif /* MOFNDETECTOR_H_ */
A Quarter Of An Hour
Looky here at what someone I know sent me:

This person is working on a project in which management requires time tracking in .25 hour increments. On some days, that poor sap and her teammates spend at least that much time at the end of the day aggregating and entering their time into their formal timesheets.
Humorously, those in charge of running the project have no qualms about promoting their process as “agile“.
I can’t know for sure, but I speculate that the practice of micromanagement cloaked under the veil of “agile” is pervasive throughout the software development industry.
Linear Interpolation In C++
In scientific programming and embedded sensor systems applications, linear interpolation is often used to estimate a value from a series of discrete data points. The problem is stated and the solution is given as follows:
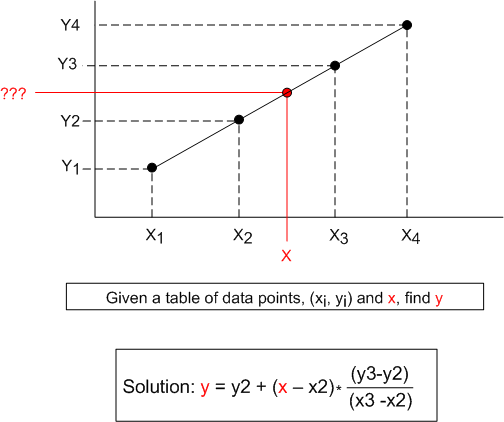
The solution assumes that any two points in a set of given data points represents a straight line. Hence, it takes the form of the classic textbook equation for a line, y = b + mx, where b is the y intercept and m is the slope of the line.
If the set of data points does not represent a linear underlying phenomenon, more sophisticated polynomial interpolation techniques that use additional data points around the point of interest can be utilized to get a more accurate estimate.
The code snippets below give the definition and implementation of a C++ functor class that performs linear interpolation. I chose to use a vector of pairs to represent the set of data points. What would’ve you used?
Interpolator.h
#ifndef INTERPOLATOR_H_
#define INTERPOLATOR_H_
#include <utility>
#include <vector>
class Interpolator {
public:
//On construction, we take in a vector of data point pairs
//that represent the line we will use to interpolate
Interpolator(const std::vector<std::pair<double, double>>& points);
//Computes the corresponding Y value
//for X using linear interpolation
double findValue(double x) const;
private:
//Our container of (x,y) data points
//std::pair::<double, double>.first = x value
//std::pair::<double, double>.second = y value
std::vector<std::pair<double, double>> _points;
};
#endif /* INTERPOLATOR_H_ */
Interpolator.cpp
#include "Interpolator.h"
#include <algorithm>
#include <stdexcept>
Interpolator::Interpolator(const std::vector<std::pair<double, double>>& points)
: _points(points) {
//Defensive programming. Assume the caller has not sorted the table in
//in ascending order
std::sort(_points.begin(), _points.end());
//Ensure that no 2 adjacent x values are equal,
//lest we try to divide by zero when we interpolate.
const double EPSILON{1.0E-8};
for(std::size_t i=1; i<_points.size(); ++i) {
double deltaX{std::abs(_points[i].first - _points[i-1].first)};
if(deltaX < EPSILON ) {
std::string err{"Potential Divide By Zero: Points " +
std::to_string(i-1) + " And " +
std::to_string(i) + " Are Too Close In Value"};
throw std::range_error(err);
}
}
}
double Interpolator::findValue(double x) const {
//Define a lambda that returns true if the x value
//of a point pair is < the caller's x value
auto lessThan =
[](const std::pair<double, double>& point, double x)
{return point.first < x;};
//Find the first table entry whose value is >= caller's x value
auto iter =
std::lower_bound(_points.cbegin(), _points.cend(), x, lessThan);
//If the caller's X value is greater than the largest
//X value in the table, we can't interpolate.
if(iter == _points.cend()) {
return (_points.cend() - 1)->second;
}
//If the caller's X value is less than the smallest X value in the table,
//we can't interpolate.
if(iter == _points.cbegin() and x <= _points.cbegin()->first) {
return _points.cbegin()->second;
}
//We can interpolate!
double upperX{iter->first};
double upperY{iter->second};
double lowerX{(iter - 1)->first};
double lowerY{(iter - 1)->second};
double deltaY{upperY - lowerY};
double deltaX{upperX - lowerX};
return lowerY + ((x - lowerX)/ deltaX) * deltaY;
}
In the constructor, the code attempts to establish the invariant conditions required before any post-construction interpolation can be attempted:
- It sorts the data points in ascending X order – just in case the caller “forgot” to do it.
- It ensures that no two adjacent X values have the same value – which could cause a divide-by-zero during the interpolation computation. If this constraint is not satisfied, an exception is thrown.
Here are the unit tests I ran on the implementation:
#include "catch.hpp"
#include "Interpolator.h"
TEST_CASE( "Test", "[Interpolator]" ) {
//Construct with an unsorted set of data points
Interpolator interp1{
{
//{X(i),Y(i)
{7.5, 32.0},
{1.5, 20.0},
{0.5, 10.0},
{3.5, 28.0},
}
};
//X value too low
REQUIRE(10.0 == interp1.findValue(.2));
//X value too high
REQUIRE(32.0 == interp1.findValue(8.5));
//X value in 1st sorted slot
REQUIRE(15.0 == interp1.findValue(1.0));
//X value in last sorted slot
REQUIRE(30.0 == interp1.findValue(5.5));
//X value in second sorted slot
REQUIRE(24.0 == interp1.findValue(2.5));
//Two points have the same X value
std::vector<std::pair<double, double>> badData{
{.5, 32.0},
{1.5, 20.0},
{3.5, 28.0},
{1.5, 10.0},
};
REQUIRE_THROWS(Interpolator interp2{badData});
}
How can this code be improved?
The Unwanted State Transition
Humor me for a moment by assuming that this absurdly simplistic state transition diagram accurately models the behavior of any given large institution:
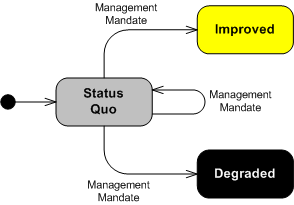
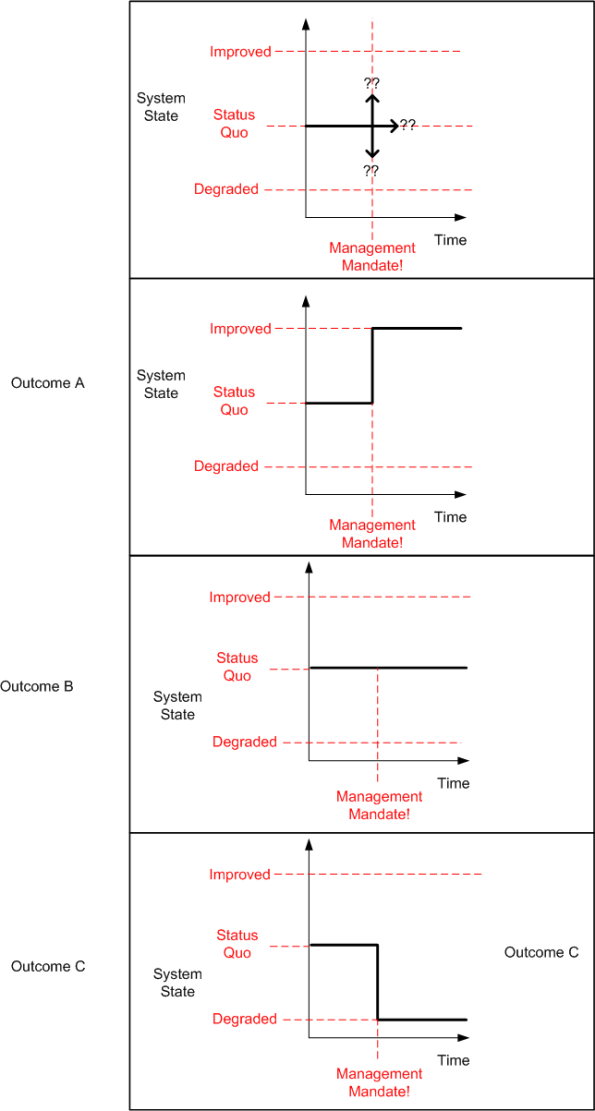
In your experience, which of the following transitions have you observed occurring most frequently at your institution?
First Confuse Them, And Then Unconfu$e Them
I don’t understand it. I simply don’t understand how some (many?) Scrum coaches and consultants can advocate dumping the words “estimates” and “backlogs” from Scrum.
The word “estimate” appears 9 times in the 16 page Scrum Guide:
- All incomplete Product Backlog Items are re-estimated and put back on the Product Backlog.
- The work done on them depreciates quickly and must be frequently re-estimated.
- Work may be of varying size, or estimated effort.
- Product Backlog items have the attributes of a description, order, estimate and value.
- Product Backlog refinement is the act of adding detail, estimates, and order to items in the Product Backlog
- More precise estimates are made based on the greater clarity and increased detail; the lower the order, the less detail.
- The Development Team is responsible for all estimates.
- ..the people who will perform the work make the final estimate.
- As work is performed or completed, the estimated remaining work is updated
As for the word “backlog“, it appears an astonishing 80 times in the 16 page Scrum Guide.
People who make their living teaching Scrum while insinuating that “estimates/backlogs” aren’t woven into the fabric of Scrum are full of sheet. How in the world could one, as a certified Scrum expert, teach Scrum to software development professionals and not mention “estimates/backlogs”?

Even though I think their ideas (so far) lack actionable substance, I have no problem with revolutionaries who want to jettison the words “estimates/backlogs” from the software development universe. I only have a problem with those who attempt to do so by disingenuously associating their alternatives with Scrum to get attention they wouldn’t otherwise get. Ideas should stand on their own merit.
If you follow these faux-scrummers on Twitter, they’ll either implicitly or explicitly trash estimates/backlogs and then have the audacity to deny it when some asshole (like me) calls them out on it. One of them actually cranked it up a notch by tweeting, without blinking an e-eye, that Scrum was defined before Scrum was defined – even though the second paragraph in the Scrum guide is titled “Definition Of Scrum“. Un-freakin-believable.

Sorry, but I lied in the first sentence of this post. I DO understand why some so-called Scrum advocates would call for the removal of concepts integrally baked into the definition of the Scrum framework. It’s because clever, ambiguous behavior is what defines the consulting industry in general. It’s the primary strategy the industry uses very, very effectively to make you part with your money: first they confuse you, then they’ll un-confuse you if you “hire us for $2K /expert/day“.
…and people wonder why I disdain the consulting industry.
The best book I ever read on the deviousness of the consulting industry was written by a reformed consultant: Matthew Stewart. Perhaps you should read it too:

Bidirectionally Speaking
Given a design that requires a bidirectional association between two peer classes:
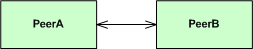
here is how it can be implemented in C++:

Note: I’m using structs here instead of classes to keep the code in this post less verbose
The key to implementing a bidirectional association in C++ is including a forward struct declaration statement in each of the header files. If you try to code the bidirectional relationship with #include directives instead of forward declarations:

you’ll have unknowingly caused a downstream problem because you’ve introduced a circular dependency into the compiler’s path. To show this, let’s implement the following larger design:
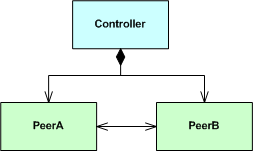
as:

Now, if we try to create a Controller object in a .cpp file like this:

the compiler will be happy with the forward class declarations implementation. However, it will barf on the circularly dependent #include directives implementation. The compiler will produce a set of confusing errors akin to this:
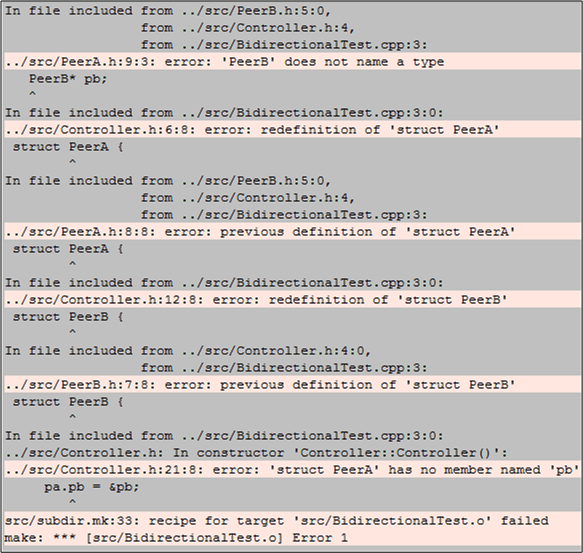
I can’t remember the exact details of the last time I tried coding up a design that had a bidirectional relationship between two classes, but I do remember creating an alternative design that did not require one.
Out With The Old, In With The New
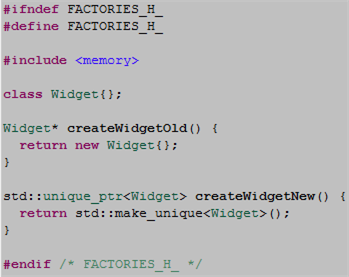
In “old” C++, object factories had little choice but to return unsafe naked pointers to users. In “new” C++, factories can return safe smart pointers. The code snippet below contrasts the old with new.
The next code snippet highlights the difference in safety between the old and the new.
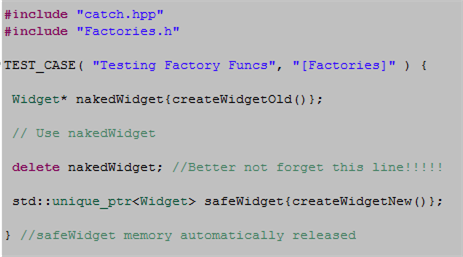
When a caller uses the old factory technique, safety may be compromised in two ways:
- If an exception is thrown in the caller’s code after the object is created but before the delete statement is executed, we have a leak.
- If the user “forgets” to write the delete statement, we have a leak.
Returning a smart pointer from a factory relegates these risks to the dust bin of history.
Publicizing My Private Parts
Check out the simple unit test code fragment below. What the hell is the #define private public preprocessor directive doing in there?
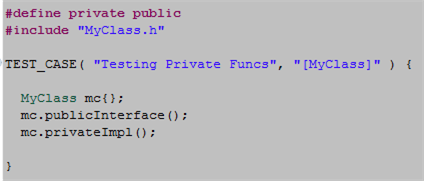
Now look at the simple definition of MyClass:
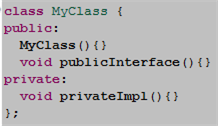
The purpose of the preprocessor #define statement is to provide a simple, elegant way of being able to unit test the privately defined MyClass::privateImpl() function. It sure beats the kludgy “friend class technique” that blasphemously couples the product code base to the unit test code base, no? It also beats the commonly abused technique of specifying all member functions as public for the sole purpose of being able to invoke them in unit test code, no?
Since the (much vilified) C++ preprocessor is a simple text substitution tool, the compiler sees this definition of MyClass just prior to generating the test executable:
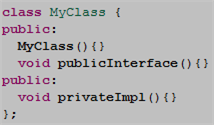
Embarassingly, I learned this nifty trick only recently from a colleague. Even more embarassingly, I didn’t think of it myself.
In an ideal world, there is never a need to directly call private functions or inspect private state in a unit test, but I don’t live in an ideal world. I’m not advocating the religious use of the #define technique to do white box unit testing, it’s just a simple tool to use if you happen to need it. Of course, it would be insane to use it in any production code.
Arne Mertz has a terrific post that covers just about every angle on unit testing C++ code: Unit Tests Are Not Friends.
Scraditionally Speaking

Gee, look at all those fancy, multidividual contributor titles. And then there is the development team, a.k.a the title-less induhvidual contributors.
Who am I?
Why am I here?
WTF?
Meh!
D'oh!
My BTC Address

